MINHASH_LSH
Efficient deduplication and similarity search are critical for large-scale machine learning datasets, especially for tasks like cleaning training corpora for Large Language Models (LLMs). When dealing with millions or billions of documents, traditional exact matching becomes too slow and costly.
The MINHASH_LSH index in Milvus enables fast, scalable, and accurate approximate deduplication by combining two powerful techniques:
MinHash: Quickly generates compact signatures (or “fingerprints”) to estimate document similarity.
Locality-Sensitive Hashing (LSH): Rapidly finds groups of similar documents based on their MinHash signatures.
This guide walks you through the concepts, prerequisites, setup, and best practices for using MINHASH_LSH in Milvus.
Overview
Jaccard similarity
Jaccard similarity measures the overlap between two sets A and B, formally defined as:
Where its value ranges from 0 (completely disjoint) to 1 (identical).
However, computing Jaccard similarity exactly between all document pairs in large-scale datasets is computationally expensive—O(n²) in time and memory when n is large. This makes it infeasible for use cases such as LLM training corpus cleaning or web-scale document analysis.
MinHash signatures: Approximate Jaccard similarity
MinHash is a probabilistic technique that offers an efficient way to estimate Jaccard similarity. It works by transforming each set into a compact signature vector, preserving enough information to approximate set similarity efficiently.
The core idea:
The more similar the two sets are, the more likely their MinHash signatures will match at the same positions. This property enables MinHash to approximate the Jaccard similarity between sets.
This property allows MinHash to approximate the Jaccard similarity between sets without needing to compare the full sets directly.
The MinHash process involves:
Shingling: Convert documents into sets of overlapping token sequences (shingles)
Hashing: Apply multiple independent hash functions to each shingle
Min Selection: For each hash function, record the minimum hash value across all shingles
You can see the entire process illustrated below:
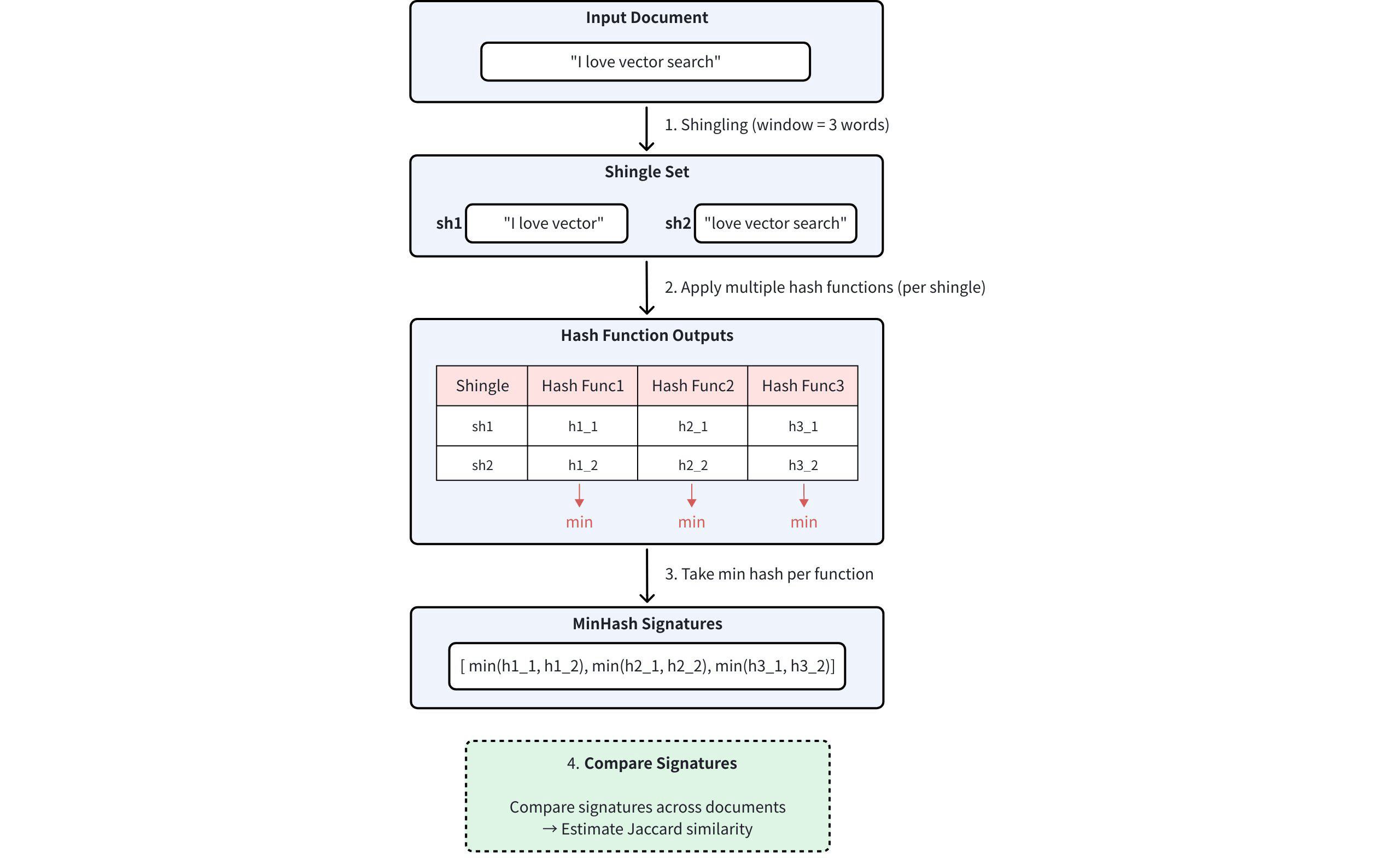 Minhash Workflow
Minhash Workflow
The number of hash functions used determines the dimensionality of the MinHash signature. Higher dimensions provide better approximation accuracy, at the cost of increased storage and computation.
LSH for MinHash
While MinHash signatures significantly reduce the cost of computing exact Jaccard similarity between documents, exhaustively comparing every pair of signature vectors is still inefficient at scale.
To solve this, LSH is used. LSH enables fast approximate similarity search by ensuring that similar items are hashed into the same “bucket” with high probability — avoiding the need to compare every pair directly.
The process involves:
Signature segmentation:
An n-dimensional MinHash signature is divided into b bands. Each band contains r consecutive hash values, so the total signature length satisfies: n = b × r.
For example, if you have a 128-dimensional MinHash signature (n = 128) and divide it into 32 bands (b = 32), then each band contains 4 hash values (r = 4).
Band-level hashing:
After segmentation, each band is independently processed using a standard hash function to assign it to a bucket. If two signatures produce the same hash value within a band—i.e., they fall into the same bucket—they are considered potential matches.
Candidate selection:
Pairs that collide in at least one band are selected as similarity candidates.
Why it works?
Mathematically, if two signatures have Jaccard similarity ,
The probability they are identical in one row (hash position) is
The probability they match in all rows of a band is
The probability that they match in at least one band is
For details, refer to Locality-sensitive hashing.
Consider three documents with 128-dimensional MinHash signatures:
 Lsh Workflow 1
Lsh Workflow 1
First, LSH divides the 128-dimensional signature into 32 bands of 4 consecutive values each:
 Lsh Workflow 2
Lsh Workflow 2
Then, each band is hashed into different buckets using a hash function. Document pairs sharing buckets are selected as similarity candidates. In the example below, Document A and Document B are selected as similarity candidates as their hash results collide in Band 0:
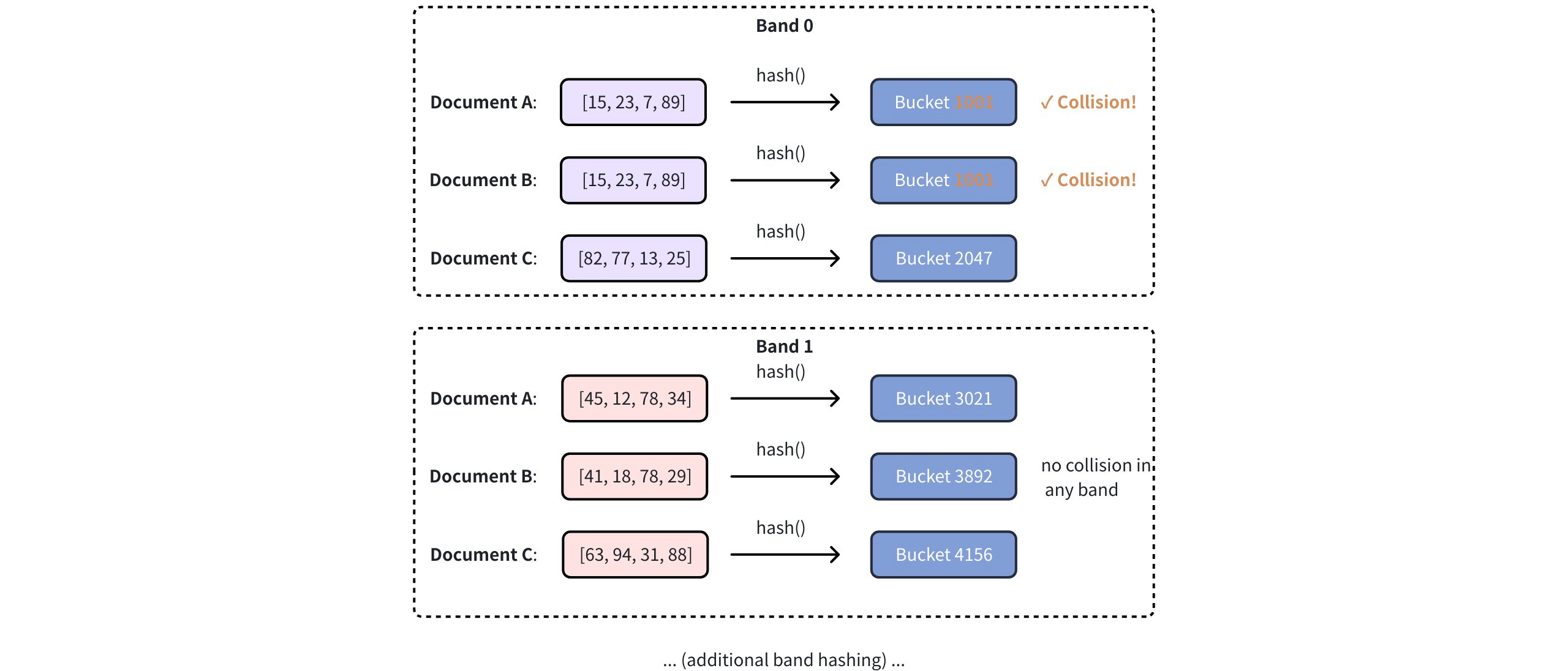 Lsh Workflow 3
Lsh Workflow 3
The number of bands is controlled by the mh_lsh_band parameter. For more information, refer to Index building params.
MHJACCARD: Comparing MinHash signatures
MinHash signatures approximate the Jaccard similarity between sets using fixed-length binary vectors. However, since these signatures do not preserve the original sets, standard metrics such as JACCARD, L2, or COSINE cannot be directly applied to compare them.
To address this, Milvus introduces a specialized metric type called MHJACCARD, designed specifically for comparing MinHash signatures.
When using MinHash in Milvus:
The vector field must be of type
BINARY_VECTORThe
index_typemust beMINHASH_LSH(orBIN_FLAT)The
metric_typemust be set toMHJACCARD
Using other metrics will either be invalid or yield incorrect results.
For more information about this metric type, refer to MHJACCARD.
Deduplication workflow
The deduplication process powered by MinHash LSH allows Milvus to efficiently identify and filter out near-duplicate text or structured records before inserting them into the collection.
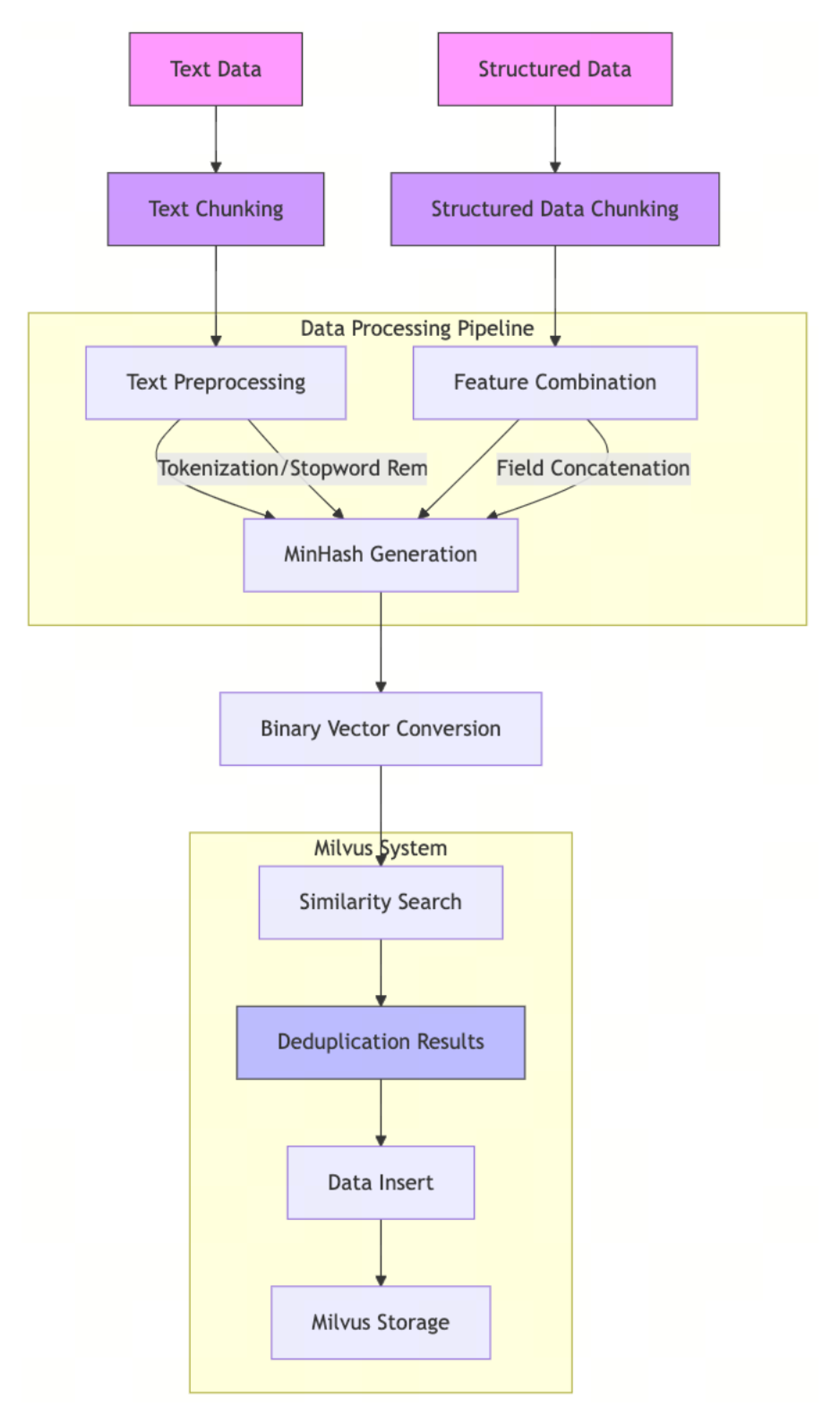
Chunk & preprocess: Split incoming text data or structured data (e.g., records, fields) into chunks; normalize text (lowercasing, punctuation removal), and remove stopwords as needed.
Feature construction: Build the token set used for MinHash (e.g., shingles from text; concatenated field tokens for structured data).
MinHash signature generation: Compute MinHash signatures for each chunk or record.
Binary vector conversion: Convert the signature to a binary vector compatible with Milvus.
Search before insert: Use the MinHash LSH index to search the target collection for near-duplicates of the incoming item.
Insert & store: Insert only unique items into the collection. They become searchable for future dedup checks.
Prerequisites
Before using MinHash LSH in Milvus, you must first generate MinHash signatures. These compact binary signatures approximate Jaccard similarity between sets and are required for MHJACCARD-based search in Milvus.
Choose a method to generate MinHash signatures
Depending on your workload, you can choose:
Use Python’s
datasketchfor simplicity (recommended for prototyping)Use distributed tools (e.g., Spark, Ray) for large-scale datasets
Implement custom logic (NumPy, C++, etc.) if performance tuning is critical
In this guide, we use datasketch for simplicity and compatibility with Milvus input format.
Install required libraries
Install the necessary packages for this example:
pip install pymilvus datasketch numpy
Generate MinHash signatures
We’ll generate 256-dimensional MinHash signatures, with each hash value represented as a 64-bit integer. This aligns with the expected vector format for MINHASH_LSH.
from datasketch import MinHash
import numpy as np
MINHASH_DIM = 256
HASH_BIT_WIDTH = 64
def generate_minhash_signature(text, num_perm=MINHASH_DIM) -> bytes:
m = MinHash(num_perm=num_perm)
for token in text.lower().split():
m.update(token.encode("utf8"))
return m.hashvalues.astype('>u8').tobytes() # Returns 2048 bytes
Each signature is 256 × 64 bits = 2048 bytes. This byte string can be directly inserted into a BINARY_VECTOR field. For more information on binary vectors used in Milvus, refer to Binary Vector.
(Optional) Prepare raw token sets (for refined search)
By default, Milvus uses only the MinHash signatures and LSH index to find approximate neighbors. This is fast but may return false positives or miss close matches.
If you want accurate Jaccard similarity, Milvus supports refined search that uses original token sets. To enable it:
Store token sets as a separate
VARCHARfieldSet
"with_raw_data": Truewhen building index parametersAnd enable
"mh_search_with_jaccard": Truewhen performing similarity search
Token set extraction example:
def extract_token_set(text: str) -> str:
tokens = set(text.lower().split())
return " ".join(tokens)
Use MinHash LSH
Once your MinHash vectors and original token sets are ready, you can store, index, and search them using Milvus with MINHASH_LSH.
Connect to your cluster
from pymilvus import MilvusClient
client = MilvusClient(uri="http://localhost:19530") # Update if your URI is different
// java
// nodejs
// go
# restful
Define collection schema
Define a schema with:
The primary key
A
BINARY_VECTORfield for the MinHash signaturesA
VARCHARfield for the original token set (if refined search is enabled)Optionally, a
documentfield for original text
from pymilvus import DataType
VECTOR_DIM = MINHASH_DIM * HASH_BIT_WIDTH # 256 × 64 = 8192 bits
schema = client.create_schema(auto_id=False, enable_dynamic_field=False)
schema.add_field("doc_id", DataType.INT64, is_primary=True)
schema.add_field("minhash_signature", DataType.BINARY_VECTOR, dim=VECTOR_DIM)
schema.add_field("token_set", DataType.VARCHAR, max_length=1000) # required for refinement
schema.add_field("document", DataType.VARCHAR, max_length=1000)
// java
// nodejs
// go
# restful
Build index parameters and create collection
Build a MINHASH_LSH index with Jaccard refinement enabled:
index_params = client.prepare_index_params()
index_params.add_index(
field_name="minhash_signature",
index_type="MINHASH_LSH",
metric_type="MHJACCARD",
params={
"mh_element_bit_width": HASH_BIT_WIDTH, # Must match signature bit width
"mh_lsh_band": 16, # Band count (128/16 = 8 hashes per band)
"with_raw_data": True # Required for Jaccard refinement
}
)
client.create_collection("minhash_demo", schema=schema, index_params=index_params)
// java
// nodejs
// go
# restful
For more information on index building parameters, refer to Index building params.
Insert data
For each document, prepare:
A binary MinHash signature
A serialized token set string
(Optionally) the original text
documents = [
"machine learning algorithms process data automatically",
"deep learning uses neural networks to model patterns"
]
insert_data = []
for i, doc in enumerate(documents):
sig = generate_minhash_signature(doc)
token_str = extract_token_set(doc)
insert_data.append({
"doc_id": i,
"minhash_signature": sig,
"token_set": token_str,
"document": doc
})
client.insert("minhash_demo", insert_data)
client.flush("minhash_demo")
// java
// nodejs
// go
# restful
Perform similarity search
Milvus supports two modes of similarity search using MinHash LSH:
Approximate search — uses only MinHash signatures and LSH for fast but probabilistic results.
Refined search — re-computes Jaccard similarity using original token sets for improved accuracy.
5.1 Prepare the query
To perform a similarity search, generate a MinHash signature for the query document. This signature must match the same dimension and encoding format used during data insertion.
query_text = "neural networks model patterns in data"
query_sig = generate_minhash_signature(query_text)
// java
// nodejs
// go
# restful
5.2 Approximate search (LSH-only)
This is fast and scalable but may miss close matches or include false positives:
search_params={
"metric_type": "MHJACCARD",
"params": {}
}
approx_results = client.search(
collection_name="minhash_demo",
data=[query_sig],
anns_field="minhash_signature",
search_params=search_params,
limit=3,
output_fields=["doc_id", "document"],
consistency_level="Strong"
)
for i, hit in enumerate(approx_results[0]):
sim = 1 - hit['distance']
print(f"{i+1}. Similarity: {sim:.3f} | {hit['entity']['document']}")
// java
// nodejs
// go
# restful
5.3 Refined search (recommended for accuracy):
This enables accurate Jaccard comparison using the original token sets stored in Milvus. It’s slightly slower but recommended for quality-sensitive tasks:
search_params = {
"metric_type": "MHJACCARD",
"params": {
"mh_search_with_jaccard": True, # Enable real Jaccard computation
"refine_k": 5 # Refine top 5 candidates
}
}
refined_results = client.search(
collection_name="minhash_demo",
data=[query_sig],
anns_field="minhash_signature",
search_params=search_params,
limit=3,
output_fields=["doc_id", "document"],
consistency_level="Strong"
)
for i, hit in enumerate(refined_results[0]):
sim = 1 - hit['distance']
print(f"{i+1}. Similarity: {sim:.3f} | {hit['entity']['document']}")
// java
// nodejs
// go
# restful
Index params
This section provides an overview of the parameters used for building an index and performing searches on the index.
Index building params
The following table lists the parameters that can be configured in params when building an index.
Parameter |
Description |
Value Range |
Tuning Suggestion |
|---|---|---|---|
|
Bit width of each hash value in the MinHash signature. Must be divisible by 8. |
8, 16, 32, 64 |
Use |
|
Number of bands to divide the MinHash signature for LSH. Controls the recall-performance tradeoff. |
[1, signature_length] |
For 128-dim signatures: start with 32 bands (4 values/band). Increase to 64 for higher recall, decrease to 16 for better performance. Must divide signature length evenly. |
|
Whether to store LSH hash codes in anonymous memory ( |
true, false |
Use |
|
Whether to store original MinHash signatures alongside LSH codes for refinement. |
true, false |
Use |
|
False positive probability for Bloom filter used in LSH bucket optimization. |
[0.001, 0.1] |
Use |
Index-specific search params
The following table lists the parameters that can be configured in search_params.params when searching on the index.
Parameter |
Description |
Value Range |
Tuning Suggestion |
|---|---|---|---|
|
Whether to perform exact Jaccard similarity computation on candidate results for refinement. |
true, false |
Use |
|
Number of candidates to retrieve before Jaccard refinement. Only effective when |
[top_k, *top_k * 10*] |
Set to 2-5x the desired top_k for good recall-performance balance. Higher values improve recall but increase computation cost. |
|
Whether to enable batch optimization for multiple simultaneous queries. |
true, false |
Use |