Spark-Milvus コネクタ ユーザーガイド
Spark-Milvus Connector (https://github.com/zilliztech/spark-milvus)はApache SparkとMilvus間のシームレスな統合を提供し、Apache Sparkのデータ処理とML機能とMilvusのベクトルデータストレージおよび検索機能を組み合わせます。この統合により、以下のような様々な興味深いアプリケーションが可能になります:
- ベクトルデータを効率的にMilvusに大量にロードする、
- Milvusと他のストレージシステムやデータベース間でデータを移動する、
- Spark MLlibやその他のAIツールを活用したMilvusでのデータ分析。
クイックスタート
準備
Spark-Milvus ConnectorはScalaとPythonプログラミング言語をサポートしています。PysparkまたはSpark-shellで使用できます。このデモを実行するには、以下の手順でSpark-Milvus Connectorの依存関係を含むSpark環境をセットアップする:
Apache Spark(バージョン3.3.0)をインストールする。
公式ドキュメントを参照してApache Sparkをインストールできる。
spark-milvusjarファイルをダウンロードする。
wget https://github.com/zilliztech/spark-milvus/raw/1.0.0-SNAPSHOT/output/spark-milvus-1.0.0-SNAPSHOT.jarspark-milvusjarを依存関係の1つとしてSparkランタイムを起動する。
Spark-Milvus ConnectorでSparkランタイムを起動するには、ダウンロードしたspark-milvusを依存関係の1つとしてコマンドに追加します。
pyspark
./bin/pyspark --jars spark-milvus-1.0.0-SNAPSHOT.jarスパークシェル
./bin/spark-shell --jars spark-milvus-1.0.0-SNAPSHOT.jar
デモ
このデモでは、ベクトルデータでサンプルのSpark DataFrameを作成し、Spark-Milvus Connectorを通してMilvusに書き込みます。スキーマと指定したオプションに基づいて、Milvusにコレクションが自動的に作成されます。
from pyspark.sql import SparkSession
columns = ["id", "text", "vec"]
data = [(1, "a", [1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0]),
(2, "b", [1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0]),
(3, "c", [1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0]),
(4, "d", [1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0])]
sample_df = spark.sparkContext.parallelize(data).toDF(columns)
sample_df.write \
.mode("append") \
.option("milvus.host", "localhost") \
.option("milvus.port", "19530") \
.option("milvus.collection.name", "hello_spark_milvus") \
.option("milvus.collection.vectorField", "vec") \
.option("milvus.collection.vectorDim", "8") \
.option("milvus.collection.primaryKeyField", "id") \
.format("milvus") \
.save()
import org.apache.spark.sql.{SaveMode, SparkSession}
object Hello extends App {
val spark = SparkSession.builder().master("local[*]")
.appName("HelloSparkMilvus")
.getOrCreate()
import spark.implicits._
// Create DataFrame
val sampleDF = Seq(
(1, "a", Seq(1.0,2.0,3.0,4.0,5.0)),
(2, "b", Seq(1.0,2.0,3.0,4.0,5.0)),
(3, "c", Seq(1.0,2.0,3.0,4.0,5.0)),
(4, "d", Seq(1.0,2.0,3.0,4.0,5.0))
).toDF("id", "text", "vec")
// set milvus options
val milvusOptions = Map(
"milvus.host" -> "localhost" -> uri,
"milvus.port" -> "19530",
"milvus.collection.name" -> "hello_spark_milvus",
"milvus.collection.vectorField" -> "vec",
"milvus.collection.vectorDim" -> "5",
"milvus.collection.primaryKeyField", "id"
)
sampleDF.write.format("milvus")
.options(milvusOptions)
.mode(SaveMode.Append)
.save()
}
上記のコードを実行した後、SDKまたはAttu (A Milvus Dashboard)を使ってMilvusに挿入されたデータを見ることができます。既に4つのエンティティが挿入されたhello_spark_milvus というコレクションが作成されていることがわかります。
機能とコンセプト
Milvusオプション
クイックスタートでは、Milvusを使用する際のオプション設定について説明しました。これらのオプションはMilvusオプションとして抽象化されています。これらのオプションはMilvusへの接続を作成したり、他のMilvusの動作を制御するために使用されます。すべてのオプションが必須というわけではありません。
| オプション キー | デフォルト値 | 説明 |
|---|---|---|
milvus.host | localhost | Milvusサーバホスト。詳細はMilvus接続の管理を参照してください。 |
milvus.port | 19530 | Milvusサーバポート。詳細はMilvus接続の管理を参照してください。 |
milvus.username | root | Milvusサーバのユーザ名.詳細はMilvus接続の管理を参照してください。 |
milvus.password | Milvus | Milvusサーバのパスワード詳細はMilvus接続の管理を参照してください。 |
milvus.uri | -- | MilvusサーバのURI。詳細はMilvus 接続の管理を参照してください。 |
milvus.token | -- | Milvusサーバトークン。詳細はMilvus接続の管理を参照してください。 |
milvus.database.name | default | 読み書きするMilvusデータベースの名前。 |
milvus.collection.name | hello_milvus | 読み書きするMilvusコレクションの名前。 |
milvus.collection.primaryKeyField | None | コレクション内の主キーフィールドの名前。コレクションが存在しない場合は必須。 |
milvus.collection.vectorField | None | コレクション内のベクトル・フィールドの名前。コレクションが存在しない場合は必須。 |
milvus.collection.vectorDim | None | コレクション内のベクトルフィールドの次元。コレクションが存在しない場合は必須。 |
milvus.collection.autoID | false | コレクションが存在しない場合、このオプションはエンティティの ID を自動的に生成するかどうかを指定する。詳細はcreate_collectionを参照。 |
milvus.bucket | a-bucket | Milvusストレージのバケット名。milvus.yaml のminio.bucketName と同じでなければなりません。 |
milvus.rootpath | files | Milvusストレージのルートパス。milvus.yamlの minio.rootpath 。 |
milvus.fs | s3a:// | Milvusストレージのファイルシステム。s3a:// はオープンソースの Spark に適用されます。Databricks の場合はs3:// を使用してください。 |
milvus.storage.endpoint | localhost:9000 | Milvusストレージのエンドポイント。milvus.yaml のminio.address:minio.port と同じにします。 |
milvus.storage.user | minioadmin | Milvusストレージのユーザー。milvus.yamlの minio.accessKeyID 。 |
milvus.storage.password | minioadmin | Milvusストレージのパスワード。milvus.yamlの minio.secretAccessKey 。 |
milvus.storage.useSSL | false | MilvusストレージにSSLを使用するかどうか。milvus.yamlの minio.useSSL 。 |
Milvusデータフォーマット
Spark-Milvus Connectorは以下のMilvusデータフォーマットでのデータの読み書きをサポートしています:
milvus:Spark DataFrameからMilvusエンティティへのシームレスな変換のためのMilvusデータフォーマット。milvusbinlog:Milvus組み込みのbinlogデータを読み込むためのMilvusデータフォーマット。mjson:Milvusにデータを一括挿入するためのMilvus JSONフォーマット。
Milvus
クイックスタートでは、milvusフォーマットを使用してサンプルデータをMilvusクラスタに書き込みます。milvusフォーマットは新しいデータフォーマットで、Spark DataFrameデータをMilvus Collectionsにシームレスに書き込むことができます。これはMilvus SDKのInsert APIをバッチコールすることで実現されます。コレクションがMilvusに存在しない場合、Dataframeのスキーマに基づいて新しいコレクションが作成されます。しかし、自動的に作成されたコレクションは、コレクションスキーマのすべての機能をサポートしているとは限りません。そのため、まずSDK経由でコレクションを作成し、その後spark-milvusを使用して書き込みを行うことを推奨します。詳細はデモを参照してください。
milvusbinlog
新しいデータフォーマットmilvusbinlogはMilvus組み込みのbinlogデータを読み込むためのものです。BinlogはパーケットベースのMilvus内部データ保存フォーマットです。残念ながら、通常のパーケットライブラリでは読み込むことができないため、Sparkジョブが読み込めるようにこの新しいデータフォーマットを実装しました。 milvusの内部ストレージの詳細に精通していない限り、milvusbinlogを直接使用することはお勧めしません。次のセクションで紹介するMilvusUtils関数を使うことをお勧めします。
val df = spark.read
.format("milvusbinlog")
.load(path)
.withColumnRenamed("val", "embedding")
mjson
Milvusは大規模なデータセットを扱う際に、書き込みのパフォーマンスを向上させるためにBulkinsert機能を提供しています。しかし、Milvusが使用するJSONフォーマットはSparkのデフォルトJSON出力フォーマットとは若干異なる。 これを解決するために、Milvusの要件を満たすデータを生成するためにmjsonデータフォーマットを導入する。以下にJSON-linesとmjsonの違いを示す例を示します:
JSON-lines:
{"book_id": 101, "word_count": 13, "book_intro": [1.1, 1.2]} {"book_id": 102, "word_count": 25, "book_intro": [2.1, 2.2]} {"book_id": 103, "word_count": 7, "book_intro": [3.1, 3.2]} {"book_id": 104, "word_count": 12, "book_intro": [4.1, 4.2]} {"book_id": 105, "word_count": 34, "book_intro": [5.1, 5.2]}mjson (Milvus Bulkinsertでは必須):
{ "rows":[ {"book_id": 101, "word_count": 13, "book_intro": [1.1, 1.2]}, {"book_id": 102, "word_count": 25, "book_intro": [2.1, 2.2]}, {"book_id": 103, "word_count": 7, "book_intro": [3.1, 3.2]}, {"book_id": 104, "word_count": 12, "book_intro": [4.1, 4.2]}, {"book_id": 105, "word_count": 34, "book_intro": [5.1, 5.2]} ] }
これは将来的に改善される予定です。Milvusのバージョンがv2.3.7以上であり、Parquetフォーマットでのbulkinsertをサポートしている場合は、spark-milvusの統合でparquetフォーマットを使用することをお勧めします。Githubのデモを参照してください。
MilvusUtils
MilvusUtilsにはいくつかの便利なutil関数が含まれています。現在はScalaでのみサポートされています。詳しい使用例は高度な使用法のセクションにあります。
MilvusUtils.readMilvusCollection
MilvusUtils.readMilvusCollectionはMilvusコレクション全体をSpark Dataframeにロードするためのシンプルなインターフェースです。Milvus SDKの呼び出し、milvusbinlogの読み込み、一般的なunion/joinオペレーションなど様々なオペレーションをラップしています。
val collectionDF = MilvusUtils.readMilvusCollection(spark, milvusOptions)
MilvusUtils.bulkInsertFromSpark
MilvusUtils.bulkInsertFromSparkはSparkの出力ファイルを一括してMilvusにインポートする便利な方法を提供します。Milvus SDKのBullkinsertAPIをラップしています。
df.write.format("parquet").save(outputPath)
MilvusUtils.bulkInsertFromSpark(spark, milvusOptions, outputPath, "parquet")
高度な使い方
このセクションでは、Spark-Milvus Connectorの高度な使用例として、データ分析やマイグレーションをご紹介します。より多くのデモについては、例を参照してください。
MySQL -> エンベッディング -> Milvus
このデモでは
- Spark-MySQL Connectorを通してMySQLからデータを読み込む、
- エンベッディングを生成し(例としてWord2Vecを使用)、そして
- 埋め込みデータをMilvusに書き込む。
Spark-MySQL Connectorを有効にするには、以下の依存関係をSpark環境に追加する必要があります:
spark-shell --jars spark-milvus-1.0.0-SNAPSHOT.jar,mysql-connector-j-x.x.x.jar
import org.apache.spark.ml.feature.{Tokenizer, Word2Vec}
import org.apache.spark.sql.functions.udf
import org.apache.spark.sql.{SaveMode, SparkSession}
import zilliztech.spark.milvus.MilvusOptions._
import org.apache.spark.ml.linalg.Vector
object Mysql2MilvusDemo extends App {
val spark = SparkSession.builder().master("local[*]")
.appName("Mysql2MilvusDemo")
.getOrCreate()
import spark.implicits.\_
// Create DataFrame
val sampleDF = Seq(
(1, "Milvus was created in 2019 with a singular goal: store, index, and manage massive embedding vectors generated by deep neural networks and other machine learning (ML) models."),
(2, "As a database specifically designed to handle queries over input vectors, it is capable of indexing vectors on a trillion scale. "),
(3, "Unlike existing relational databases which mainly deal with structured data following a pre-defined pattern, Milvus is designed from the bottom-up to handle embedding vectors converted from unstructured data."),
(4, "As the Internet grew and evolved, unstructured data became more and more common, including emails, papers, IoT sensor data, Facebook photos, protein structures, and much more.")
).toDF("id", "text")
// Write to MySQL Table
sampleDF.write
.mode(SaveMode.Append)
.format("jdbc")
.option("driver","com.mysql.cj.jdbc.Driver")
.option("url", "jdbc:mysql://localhost:3306/test")
.option("dbtable", "demo")
.option("user", "root")
.option("password", "123456")
.save()
// Read from MySQL Table
val dfMysql = spark.read
.format("jdbc")
.option("driver","com.mysql.cj.jdbc.Driver")
.option("url", "jdbc:mysql://localhost:3306/test")
.option("dbtable", "demo")
.option("user", "root")
.option("password", "123456")
.load()
val tokenizer = new Tokenizer().setInputCol("text").setOutputCol("tokens")
val tokenizedDf = tokenizer.transform(dfMysql)
// Learn a mapping from words to Vectors.
val word2Vec = new Word2Vec()
.setInputCol("tokens")
.setOutputCol("vectors")
.setVectorSize(128)
.setMinCount(0)
val model = word2Vec.fit(tokenizedDf)
val result = model.transform(tokenizedDf)
val vectorToArrayUDF = udf((v: Vector) => v.toArray)
// Apply the UDF to the DataFrame
val resultDF = result.withColumn("embedding", vectorToArrayUDF($"vectors"))
val milvusDf = resultDF.drop("tokens").drop("vectors")
milvusDf.write.format("milvus")
.option(MILVUS_HOST, "localhost")
.option(MILVUS_PORT, "19530")
.option(MILVUS_COLLECTION_NAME, "text_embedding")
.option(MILVUS_COLLECTION_VECTOR_FIELD, "embedding")
.option(MILVUS_COLLECTION_VECTOR_DIM, "128")
.option(MILVUS_COLLECTION_PRIMARY_KEY, "id")
.mode(SaveMode.Append)
.save()
}
Milvus -> Transform -> Milvus
このデモでは
- Milvusコレクションからデータを読み込む、
- 変換を適用し(例としてPCAを使用)、そして
- 変換されたデータをBulkinsert API経由で別のMilvusに書き込む。
PCAモデルは、機械学習で一般的な操作である埋め込みベクトルの次元を削減する変換モデルです。 変換ステップには、フィルタリング、結合、正規化などの他の処理操作を追加することができます。
import org.apache.spark.ml.feature.PCA
import org.apache.spark.ml.linalg.{Vector, Vectors}
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.udf
import org.apache.spark.sql.util.CaseInsensitiveStringMap
import zilliztech.spark.milvus.{MilvusOptions, MilvusUtils}
import scala.collection.JavaConverters.\_
object TransformDemo extends App {
val sparkConf = new SparkConf().setMaster("local")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits.\_
val host = "localhost"
val port = 19530
val user = "root"
val password = "Milvus"
val fs = "s3a://"
val bucketName = "a-bucket"
val rootPath = "files"
val minioAK = "minioadmin"
val minioSK = "minioadmin"
val minioEndpoint = "localhost:9000"
val collectionName = "hello_spark_milvus1"
val targetCollectionName = "hello_spark_milvus2"
val properties = Map(
MilvusOptions.MILVUS_HOST -> host,
MilvusOptions.MILVUS_PORT -> port.toString,
MilvusOptions.MILVUS_COLLECTION_NAME -> collectionName,
MilvusOptions.MILVUS_BUCKET -> bucketName,
MilvusOptions.MILVUS_ROOTPATH -> rootPath,
MilvusOptions.MILVUS_FS -> fs,
MilvusOptions.MILVUS_STORAGE_ENDPOINT -> minioEndpoint,
MilvusOptions.MILVUS_STORAGE_USER -> minioAK,
MilvusOptions.MILVUS_STORAGE_PASSWORD -> minioSK,
)
// 1, configurations
val milvusOptions = new MilvusOptions(new CaseInsensitiveStringMap(properties.asJava))
// 2, batch read milvus collection data to dataframe
// Schema: dim of `embeddings` is 8
// +-+------------+------------+------------------+
// | | field name | field type | other attributes |
// +-+------------+------------+------------------+
// |1| "pk" | Int64 | is_primary=True |
// | | | | auto_id=False |
// +-+------------+------------+------------------+
// |2| "random" | Double | |
// +-+------------+------------+------------------+
// |3|"embeddings"| FloatVector| dim=8 |
// +-+------------+------------+------------------+
val arrayToVectorUDF = udf((arr: Seq[Double]) => Vectors.dense(arr.toArray[Double]))
val collectionDF = MilvusUtils.readMilvusCollection(spark, milvusOptions)
.withColumn("embeddings_vec", arrayToVectorUDF($"embeddings"))
.drop("embeddings")
// 3. Use PCA to reduce dim of vector
val dim = 4
val pca = new PCA()
.setInputCol("embeddings_vec")
.setOutputCol("pca_vec")
.setK(dim)
.fit(collectionDF)
val vectorToArrayUDF = udf((v: Vector) => v.toArray)
// embeddings dim number reduce to 4
// +-+------------+------------+------------------+
// | | field name | field type | other attributes |
// +-+------------+------------+------------------+
// |1| "pk" | Int64 | is_primary=True |
// | | | | auto_id=False |
// +-+------------+------------+------------------+
// |2| "random" | Double | |
// +-+------------+------------+------------------+
// |3|"embeddings"| FloatVector| dim=4 |
// +-+------------+------------+------------------+
val pcaDf = pca.transform(collectionDF)
.withColumn("embeddings", vectorToArrayUDF($"pca_vec"))
.select("pk", "random", "embeddings")
// 4. Write PCAed data to S3
val outputPath = "s3a://a-bucket/result"
pcaDf.write
.mode("overwrite")
.format("parquet")
.save(outputPath)
// 5. Config MilvusOptions of target table
val targetProperties = Map(
MilvusOptions.MILVUS*HOST -> host,
MilvusOptions.MILVUS_PORT -> port.toString,
MilvusOptions.MILVUS_COLLECTION_NAME -> targetCollectionName,
MilvusOptions.MILVUS_BUCKET -> bucketName,
MilvusOptions.MILVUS_ROOTPATH -> rootPath,
MilvusOptions.MILVUS_FS -> fs,
MilvusOptions.MILVUS_STORAGE_ENDPOINT -> minioEndpoint,
MilvusOptions.MILVUS_STORAGE_USER -> minioAK,
MilvusOptions.MILVUS_STORAGE_PASSWORD -> minioSK,
)
val targetMilvusOptions = new MilvusOptions(new CaseInsensitiveStringMap(targetProperties.asJava))
// 6. Bulkinsert Spark output files into milvus
MilvusUtils.bulkInsertFromSpark(spark, targetMilvusOptions, outputPath, "parquet")
}
Databricks -> Zilliz Cloud
Zilliz Cloud(マネージドMilvusサービス)を使用している場合、便利なData Import APIを活用することができます。Zilliz Cloudは、SparkやDatabricksを含む様々なデータソースからデータを効率的に移動するための包括的なツールとドキュメントを提供しています。S3バケットを仲介として設定し、Zilliz Cloudアカウントへのアクセスを開くだけです。Zilliz CloudのData Import APIが自動的にS3バケットからZilliz Cloudクラスタにデータをフルバッチでロードします。
準備
Databricks Clusterにjarファイルを追加してSparkランタイムをロードします。
ライブラリのインストール方法は様々です。このスクリーンショットは、ローカルからクラスタにjarをアップロードしています。詳細については、DatabricksドキュメントのCluster Librariesを参照してください。
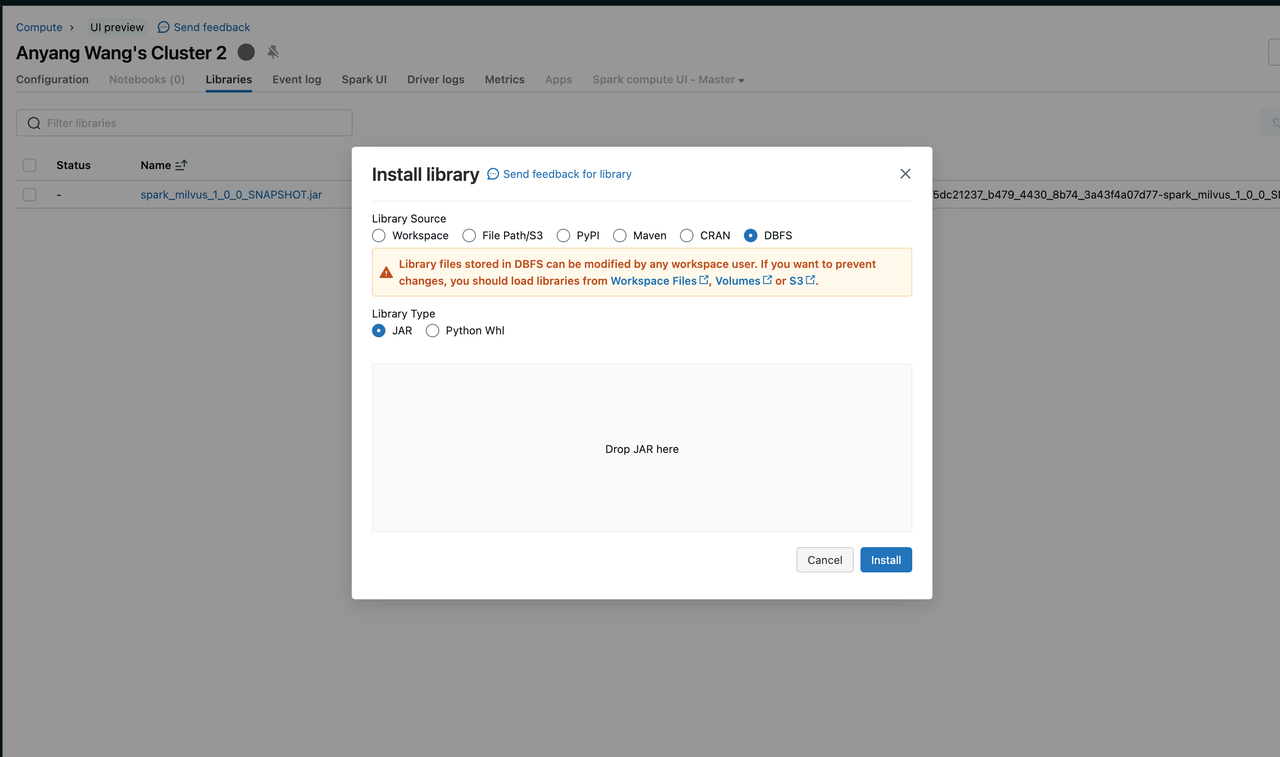 Databricksライブラリのインストール
Databricksライブラリのインストール S3バケットを作成し、Databricksクラスタの外部ストレージとして設定します。
Bulkinsertは、Zilliz Cloudが一括でデータをインポートできるように、一時的なバケットにデータを保存する必要があります。S3バケットを作成し、Databricksの外部ロケーションとして設定することができます。詳細は外部ロケーションを参照してください。
Databricks の認証情報を保護します。
詳細は、ブログ「Databricksで認証情報を安全に管理する」の説明を参照してください。
デモ
バッチデータ移行プロセスを紹介するコードスニペットです。上記のMilvusの例と同様に、クレデンシャルとS3バケットアドレスを置き換えるだけです。
// Write the data in batch into the Milvus bucket storage.
val outputPath = "s3://my-temp-bucket/result"
df.write
.mode("overwrite")
.format("mjson")
.save(outputPath)
// Specify Milvus options.
val targetProperties = Map(
MilvusOptions.MILVUS_URI -> zilliz_uri,
MilvusOptions.MILVUS_TOKEN -> zilliz_token,
MilvusOptions.MILVUS_COLLECTION_NAME -> targetCollectionName,
MilvusOptions.MILVUS_BUCKET -> bucketName,
MilvusOptions.MILVUS_ROOTPATH -> rootPath,
MilvusOptions.MILVUS_FS -> fs,
MilvusOptions.MILVUS_STORAGE_ENDPOINT -> minioEndpoint,
MilvusOptions.MILVUS_STORAGE_USER -> minioAK,
MilvusOptions.MILVUS_STORAGE_PASSWORD -> minioSK,
)
val targetMilvusOptions = new MilvusOptions(new CaseInsensitiveStringMap(targetProperties.asJava))
// Bulk insert Spark output files into Milvus
MilvusUtils.bulkInsertFromSpark(spark, targetMilvusOptions, outputPath, "mjson")
ハンズオン
Spark-Milvus Connectorをすぐに使い始められるように、MilvusとZilliz Cloudを使ったストリーミングとバッチのデータ転送プロセスを説明したノートブックを用意しました。