MilvusとDSPyの連携
![]()
DSPyとは
DSPyはスタンフォードNLPグループによって発表された、言語モデル内のプロンプトとウェイトを最適化するための画期的なプログラムフレームワークです。DSPyは、手作業での作成と微調整に依存する従来のプロンプトエンジニアリング技術とは異なり、学習ベースのアプローチを採用しています。DSPyは、クエリと回答の例を同化することで、特定のタスクに合わせて最適化されたプロンプトを動的に生成します。この革新的な手法により、パイプライン全体のシームレスな再組み立てが可能になり、手作業による継続的なプロンプトの調整が不要になります。DSPyのPythonicシンタックスは、様々なコンポーザブルで宣言的なモジュールを提供し、LLMのインストラクションを簡素化します。
DSPyを使用するメリット
- プログラミングアプローチ:DSPyは、LLMのプロンプトを表示するだけでなく、パイプラインをテキスト変換グラフとして抽象化することで、LMパイプライン開発のための体系的なプログラミングアプローチを提供します。DSPyの宣言型モジュールは、従来のプロンプトテンプレートによる試行錯誤的な手法に代わって、構造化された設計と最適化を可能にします。
- パフォーマンスの向上:DSPyは、既存の手法と比較して大幅な性能向上を示しています。ケーススタディを通じて、標準的なプロンプトや専門家が作成したデモンストレーションを凌駕し、より小さなLMモデルにコンパイルした場合でも、その汎用性と有効性を示しています。
- モジュール化された抽象化DSPyは、分解、微調整、モデル選択など、LMパイプライン開発の複雑な側面を効果的に抽象化します。DSPyを使用すると、簡潔なプログラムをGPT-4、Llama2-13b、T5-baseなどのさまざまなモデルの命令にシームレスに変換できるため、開発が効率化され、性能が向上します。
モジュール
LLMパイプラインを構築するために貢献するコンポーネントは数多くあります。ここでは、DSPyがどのように動作するかを高レベルで理解するために、いくつかの主要なコンポーネントについて説明します。
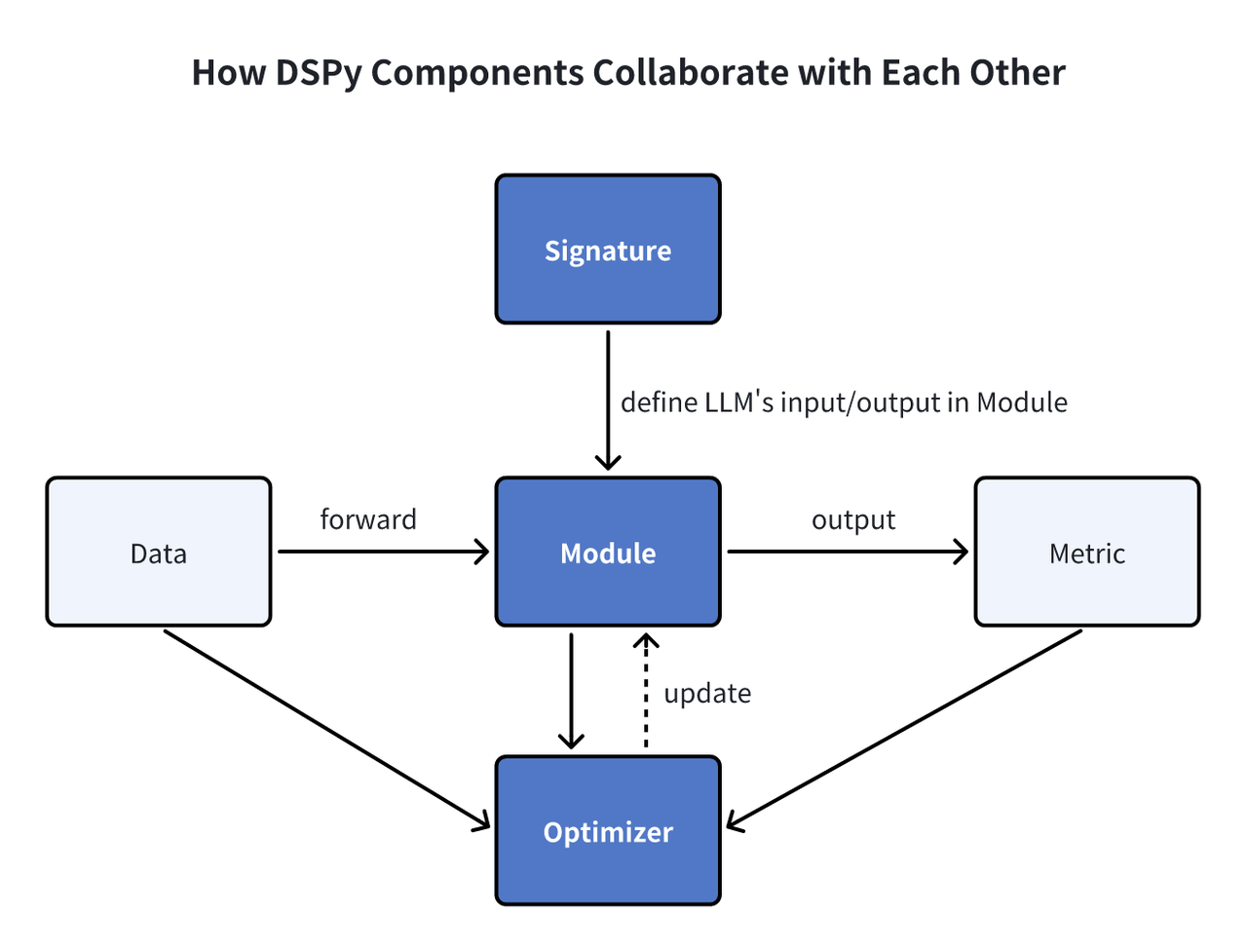 DSPyモジュール
DSPyモジュール
シグネチャ:DSPyのシグネチャは宣言的な仕様として機能し、モジュールの入出力動作の概要を示し、タスク実行における言語モデルの指針となる。 モジュール:DSPyのモジュールは、言語モデル(LM)を活用したプログラムの基本コンポーネントとして機能します。連鎖思考やReActのような様々なプロンプト技術を抽象化し、あらゆるDSPyシグネチャを扱うことができます。学習可能なパラメータと、入力を処理して出力を生成する機能を持つこれらのモジュールは、PyTorchのNNモジュールからインスピレーションを受けつつも、LMアプリケーション向けに調整された、より大きなプログラムを形成するために組み合わせることができます。 オプティマイザ:DSPyのオプティマイザは、プロンプトやLLMの重みなど、DSPyプログラムのパラメータを微調整し、精度などの指定されたメトリクスを最大化することで、プログラムの効率を高めます。
DSPyでmilvusを使う理由
DSPyは、RAGアプリケーションを強化する強力なプログラミングフレームワークです。このようなアプリケーションでは、回答の質を高めるために有用な情報を取得する必要があり、ベクトルデータベースが必要となります。Milvusは、パフォーマンスとスケーラビリティを向上させるオープンソースのベクトルデータベースとして知られています。DSPyのretrieverモジュールであるMilvusRMを使えば、Milvusの統合はシームレスになります。開発者は、Milvusの強力なベクトル検索機能を活用しながら、DSPyを使用してRAGプログラムを簡単に定義し、最適化できるようになりました。この連携により、DSPyのプログラミング機能とMilvusの検索機能を組み合わせることで、RAGアプリケーションはより効率的でスケーラブルになります。
例
それでは、RAGアプリケーションを最適化するためにDSPyでMilvusを活用する方法を、簡単な例で説明します。
前提条件
RAGアプリをビルドする前に、DSPyとPyMilvusをインストールしてください。
$ pip install "dspy-ai[milvus]"
$ pip install -U pymilvus
データセットのロード
この例では、複雑な質問と回答のペアのコレクションであるHotPotQAをトレーニングデータセットとして使用します。HotPotQAクラスを通して読み込むことができます。
from dspy.datasets import HotPotQA
# Load the dataset.
dataset = HotPotQA(
train_seed=1, train_size=20, eval_seed=2023, dev_size=50, test_size=0
)
# Tell DSPy that the 'question' field is the input. Any other fields are labels and/or metadata.
trainset = [x.with_inputs("question") for x in dataset.train]
devset = [x.with_inputs("question") for x in dataset.dev]
Milvusベクトルデータベースにデータを取り込む
ベクトル検索のためにコンテキスト情報をmilvusコレクションに取り込む。このコレクションにはembedding フィールドとtext フィールドが必要です。この場合、デフォルトのクエリ埋め込み関数としてOpenAIのtext-embedding-3-small モデルを使用する。
import requests
import os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>"
MILVUS_URI = "example.db"
MILVUS_TOKEN = ""
from pymilvus import MilvusClient, DataType, Collection
from dspy.retrieve.milvus_rm import openai_embedding_function
client = MilvusClient(uri=MILVUS_URI, token=MILVUS_TOKEN)
if "dspy_example" not in client.list_collections():
client.create_collection(
collection_name="dspy_example",
overwrite=True,
dimension=1536,
primary_field_name="id",
vector_field_name="embedding",
id_type="int",
metric_type="IP",
max_length=65535,
enable_dynamic=True,
)
text = requests.get(
"https://raw.githubusercontent.com/wxywb/dspy_dataset_sample/master/sample_data.txt"
).text
for idx, passage in enumerate(text.split("\n")):
if len(passage) == 0:
continue
client.insert(
collection_name="dspy_example",
data=[
{
"id": idx,
"embedding": openai_embedding_function(passage)[0],
"text": passage,
}
],
)
MilvusRMの定義
次にMilvusRMを定義します。
from dspy.retrieve.milvus_rm import MilvusRM
import dspy
retriever_model = MilvusRM(
collection_name="dspy_example",
uri=MILVUS_URI,
token=MILVUS_TOKEN, # ignore this if no token is required for Milvus connection
embedding_function=openai_embedding_function,
)
turbo = dspy.OpenAI(model="gpt-3.5-turbo")
dspy.settings.configure(lm=turbo)
シグネチャの構築
データをロードしたので、パイプラインのサブタスクのシグネチャを定義する。単純な入力question と出力answer を識別することができますが、RAGパイプラインを構築しているため、Milvusからコンテキスト情報を取得します。そこで、シグネチャをcontext, question --> answer と定義します。
class GenerateAnswer(dspy.Signature):
"""Answer questions with short factoid answers."""
context = dspy.InputField(desc="may contain relevant facts")
question = dspy.InputField()
answer = dspy.OutputField(desc="often between 1 and 5 words")
context 、answer のフィールドには、モデルが何を受け取り、何を生成すべきかの明確なガイドラインを定義するための短い説明を記述する。
パイプラインの構築
では、RAGパイプラインを定義しよう。
class RAG(dspy.Module):
def __init__(self, rm):
super().__init__()
self.retrieve = rm
# This signature indicates the task imposed on the COT module.
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
def forward(self, question):
# Use milvus_rm to retrieve context for the question.
context = self.retrieve(question).passages
# COT module takes "context, query" and output "answer".
prediction = self.generate_answer(context=context, question=question)
return dspy.Prediction(
context=[item.long_text for item in context], answer=prediction.answer
)
パイプラインの実行と結果の取得
さて、RAGパイプラインを構築しました。試しに結果を出してみましょう。
rag = RAG(retriever_model)
print(rag("who write At My Window").answer)
Townes Van Zandt
データセットの定量的な結果を評価することができます。
from dspy.evaluate.evaluate import Evaluate
from dspy.datasets import HotPotQA
evaluate_on_hotpotqa = Evaluate(
devset=devset, num_threads=1, display_progress=False, display_table=5
)
metric = dspy.evaluate.answer_exact_match
score = evaluate_on_hotpotqa(rag, metric=metric)
print("rag:", score)
パイプラインの最適化
このプログラムを定義したら、次はコンパイルだ。このプロセスでは、パフォーマンスを向上させるために、各モジュール内のパラメータを更新する。コンパイルのプロセスは3つの重要な要素に依存する:
- トレーニングセット:トレーニングセット:トレーニングデータセットから20の質問と回答の例をこのデモに利用する。
- 検証メトリック:単純な
validate_context_and_answerメトリックを確立します。このメトリックは、予測された答えの正確さを検証し、検索されたコンテキストに答えが含まれていることを確認します。 - 特定のオプティマイザー(テレプロンプター):DSPyのコンパイラには、プログラムを効果的に最適化するために設計された複数のテレプロンプターが組み込まれています。
from dspy.teleprompt import BootstrapFewShot
# Validation logic: check that the predicted answer is correct.# Also check that the retrieved context does contain that answer.
def validate_context_and_answer(example, pred, trace=None):
answer_EM = dspy.evaluate.answer_exact_match(example, pred)
answer_PM = dspy.evaluate.answer_passage_match(example, pred)
return answer_EM and answer_PM
# Set up a basic teleprompter, which will compile our RAG program.
teleprompter = BootstrapFewShot(metric=validate_context_and_answer)
# Compile!
compiled_rag = teleprompter.compile(rag, trainset=trainset)
# Now compiled_rag is optimized and ready to answer your new question!
# Now, let’s evaluate the compiled RAG program.
score = evaluate_on_hotpotqa(compiled_rag, metric=metric)
print(score)
print("compile_rag:", score)
Ragasスコアは以前の値50.0から52.0に上昇し、解答品質の向上を示しています。
まとめ
DSPyは、プログラマブルなインターフェイスにより、言語モデルのインタラクションを飛躍的に向上させ、モデルのプロンプトとウェイトのアルゴリズムによる自動最適化を容易にします。RAGの実装にDSPyを活用することで、様々な言語モデルやデータセットへの適応が容易になり、面倒な手作業の必要性が大幅に減少します。