リランキング
Milvusはhybrid_search()APIを使用してハイブリッド検索機能を実現し、複数のAnnSearchRequest インスタンスから検索結果を絞り込むための洗練されたリランキング戦略を組み込んでいます。このトピックでは、リランキングプロセスを取り上げ、その意義とMilvusにおける様々なリランキング戦略の実装について説明します。
概要
下図はMilvusにおけるハイブリッド検索の実行を示しており、このプロセスにおけるリランキングの役割を強調しています。

ハイブリッド検索における再ランク付けは、複数のベクトルフィールドからの結果を統合し、最終的な出力が関連性があり、正確に優先順位付けされていることを保証する重要なステップです。現在、Milvusは以下の再ランク付け戦略を提供しています:
WeightedRanker:このアプローチは、異なるベクトル検索からのスコア(またはベクトル距離)の加重平均を計算することによって結果を統合します。各ベクトルフィールドの重要性に基づいて重み付けを行います。RRFRanker:異なるベクトル列の順位に基づいて結果を結合する。
重み付きスコアリング(WeightedRanker)
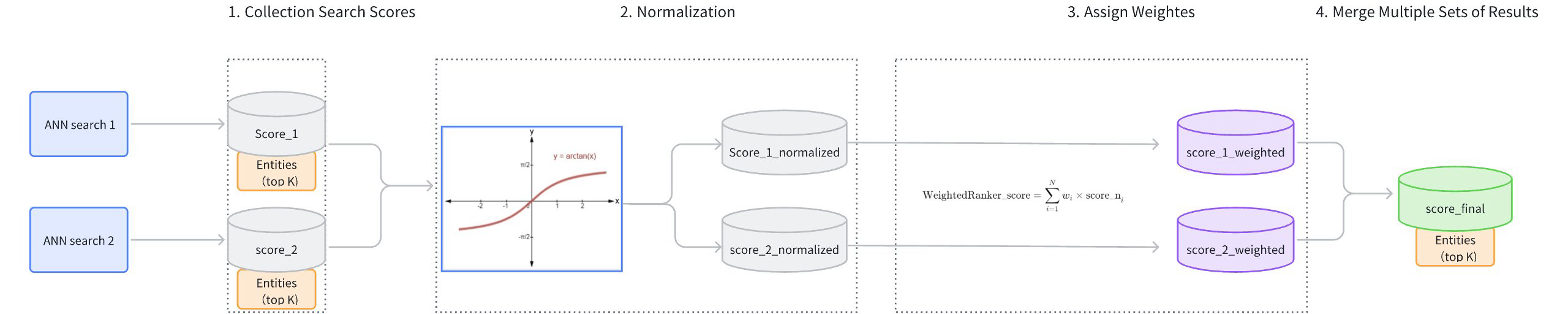
WeightedRanker 戦略は、各ベクトルフィールドの重要度に基づいて、各ベクトル検索ルートからの結果に異なる重みを割り当てます。このリランキング戦略は、各ベクトルフィールドの重要度が異なる場合に適用され、より高い重みを割り当てることで、特定のベクトルフィールドを他のベクトルフィールドよりも強調することができます。例えば、マルチモーダル検索では、画像の色分布よりもテキストの説明の方が重要だと考えられるかもしれない。
WeightedRankerの基本的なプロセスは以下の通りです:
検索時にスコアを収集する:異なるベクトル検索ルートから検索結果とそのスコアを収集する。
スコアの正規化:各ルートからのスコアを[0,1]の範囲に正規化する。スコアの分布はメトリックの種類によって異なるため、この正規化は非常に重要である。例えば、IPの距離は[-∞,+∞]、L2の距離は[0,+∞]です。Milvusは
arctan関数を採用し、値を[0,1]の範囲に変換することで、異なるメトリックタイプに対して標準化された基準を提供します。
重みの割り当て:各ベクトル検索ルートに重み(
w𝑖)を割り当てる。ユーザーは、データ・ソースの信頼性、精度、またはその他の適切なメトリックを反映する重みを指定します。各重みの範囲は [0,1] です。スコア・フュージョン:正規化されたスコアの加重平均を計算し、最終的なスコアを導き出します。次に、この最高スコアから最低スコアに基づいて結果をランク付けし、最終的なソート結果を生成する。
 重み付き再ランカー
重み付き再ランカー
このストラテジーを使用するには、WeightedRanker インスタンスを適用し、可変数の数値引数を渡して重み値を設定します。
from pymilvus import WeightedRanker
# Use WeightedRanker to combine results with specified weights
rerank = WeightedRanker(0.8, 0.8, 0.7)
以下の点に注意:
各重み値の範囲は 0(最も重要でない)から 1(最も重要)までで、最終的な集計スコアに影響する。
WeightedRankerで指定する重み値の総数は、先に作成したAnnSearchRequestインスタンスの数と同じでなければならない。異なるメトリックタイプの異なる測定値のため、我々は想起結果の距離が区間[0,1]になるように正規化する。最終的なスコアは重み値と距離の合計となる。
レシプロランク・フュージョン(RRFRanker)
RRFは、順位の逆数に基づいてランキングリストを結合するデータフュージョン手法である。特に重要度の優先順位が明確でない場合に、各ベクトルフィールドの影響力をバランスさせる効果的な方法です。この方法は通常、すべてのベクトルフィールドを同等に考慮したい場合や、各フィールドの相対的な重要性が不明確な場合に使用されます。
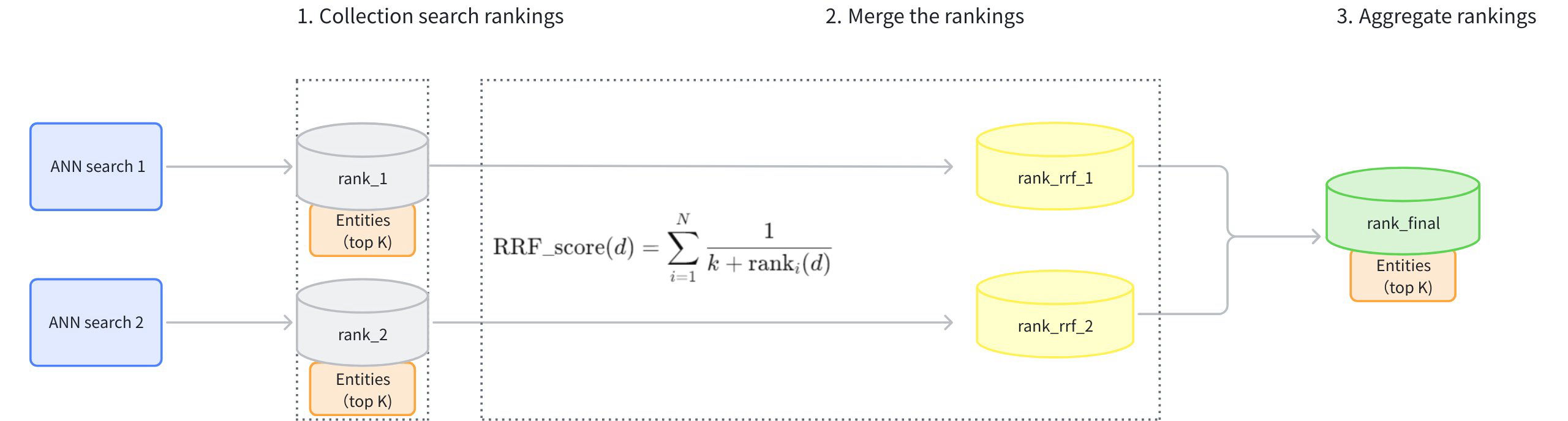
RRFの基本的なプロセスは以下の通りである:
検索時にランキングを収集する:複数のベクトルフィールドにまたがるリトリーバーが結果を取得し、ソートする。
ランク融合:RRFアルゴリズムは、各リトリーバーからのランクを重み付けし、結合する。計算式は以下の通り:
 RRF-RANKER
RRF-RANKER ここで、↪Lu_1 は異なる検索ルートの数を表し、rank𝑖(↪Ll_1D451) は𝑖番目の検索エンジンによって検索されたドキュメント𝑑のランク位置、↪Ll_1D458 は平滑化パラメータで、通常は60に設定される。
総合ランキング:最終的な結果を生成するために、検索された結果を総合スコアに基づいて再ランク付けする。
この戦略を使用するには、RRFRanker インスタンスを適用する。
from pymilvus import RRFRanker
# Default k value is 60
ranker = RRFRanker()
# Or specify k value
ranker = RRFRanker(k=100)
RRFでは、明示的な重みを指定することなく、分野間の影響力のバランスをとることができる。最終的なランキングでは、複数のフィールドで合意された上位のマッチが優先されます。