Cohérence
Cette rubrique présente les quatre niveaux de cohérence dans Milvus et les scénarios les mieux adaptés. Le mécanisme permettant d'assurer la cohérence dans Milvus est également abordé dans cette rubrique.
Vue d'ensemble
La cohérence dans une base de données distribuée fait spécifiquement référence à la propriété qui garantit que chaque nœud ou réplique a la même vue des données lors de l'écriture ou de la lecture des données à un moment donné.
Milvus prend en charge quatre niveaux de cohérence : forte, staleness limité, session et éventuellement. Le niveau de cohérence par défaut dans Milvus est l'obsolescence limitée. Vous pouvez facilement ajuster le niveau de cohérence lorsque vous effectuez une recherche monovectorielle, une recherche hybride ou une requête afin de l'adapter au mieux à votre application.
Niveaux de cohérence
Comme le définit le théorème PACELC, une base de données distribuée doit faire un compromis entre la cohérence, la disponibilité et la latence. Une cohérence élevée implique une grande précision mais aussi une latence de recherche élevée, tandis qu'une cohérence faible entraîne une vitesse de recherche rapide mais une certaine perte de visibilité des données. Par conséquent, différents niveaux de cohérence conviennent à différents scénarios.
Ce qui suit explique les différences entre les quatre niveaux de cohérence pris en charge par Milvus et les scénarios auxquels ils sont adaptés.
Fort
Strong est le niveau de cohérence le plus élevé et le plus strict. Il garantit que les utilisateurs peuvent lire la dernière version des données.
 Cohérence forte
Cohérence forte
Selon le théorème PACELC, si le niveau de cohérence est défini comme fort, la latence augmentera. Il est donc recommandé de choisir une cohérence forte lors des tests fonctionnels afin de garantir l'exactitude des résultats des tests. La cohérence forte est également la mieux adaptée aux applications qui exigent une cohérence stricte des données au détriment de la vitesse de recherche. Un exemple peut être un système financier en ligne traitant les paiements de commandes et la facturation.
Stabilité limitée (bounded staleness)
L'obsolescence limitée, comme son nom l'indique, autorise l'incohérence des données pendant une certaine période. Toutefois, en règle générale, les données sont toujours globalement cohérentes en dehors de cette période.
 Cohérence de l'impasse limitée
Cohérence de l'impasse limitée
L'obsolescence limitée convient aux scénarios qui doivent contrôler la latence de la recherche et qui peuvent accepter une invisibilité sporadique des données. Par exemple, dans les systèmes de recommandation tels que les moteurs de recommandation vidéo, l'invisibilité des données a parfois un faible impact sur le taux de rappel global, mais peut considérablement améliorer les performances du système de recommandation.
Session
La session garantit que toutes les données écrites peuvent être immédiatement perçues en lecture au cours de la même session. En d'autres termes, lorsque vous écrivez des données via un client, les données nouvellement insérées deviennent instantanément consultables.
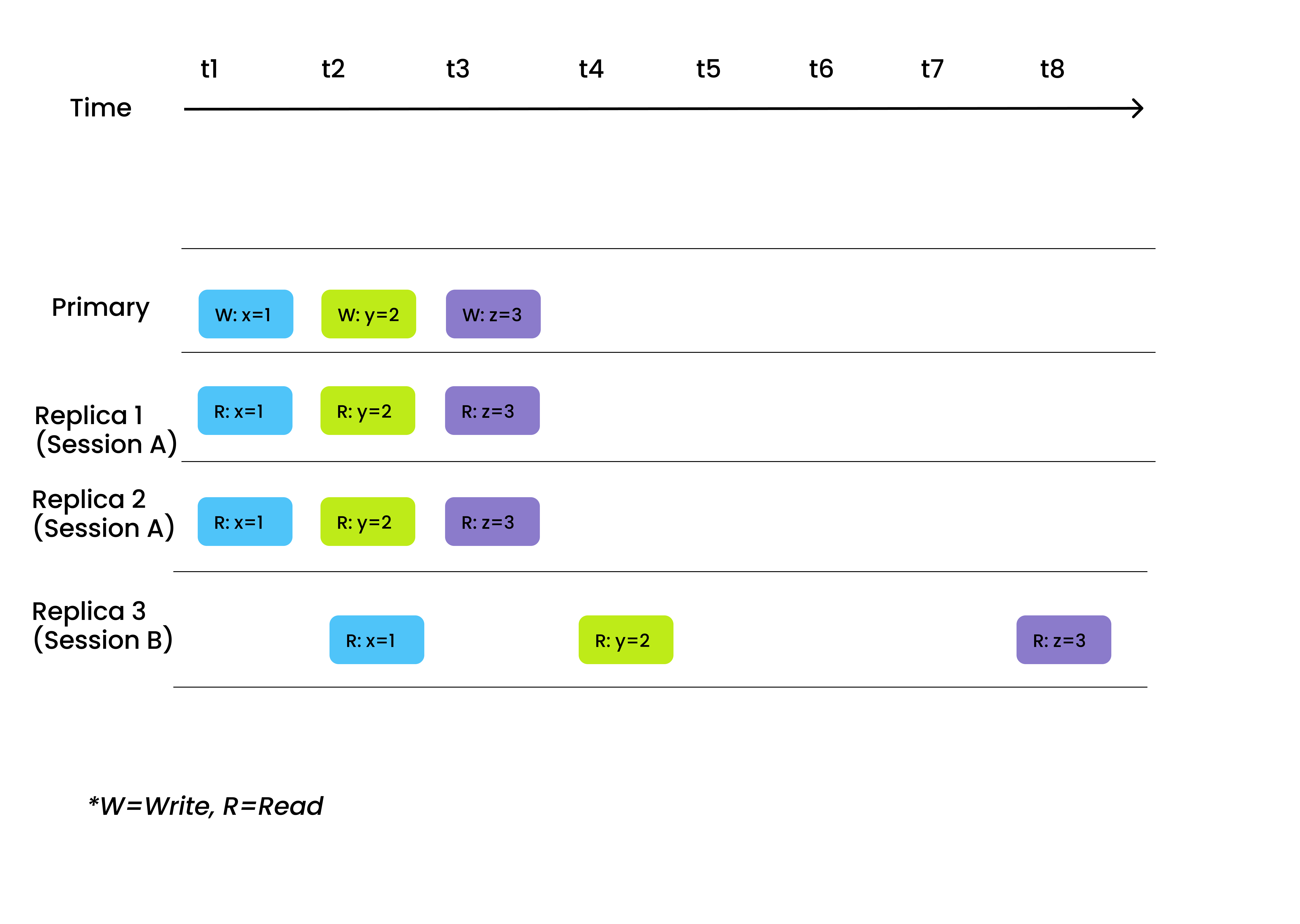 Cohérence de la session
Cohérence de la session
Nous recommandons de choisir la session comme niveau de cohérence pour les scénarios dans lesquels la demande de cohérence des données dans la même session est élevée. Un exemple peut être la suppression des données d'une entrée de livre dans le système de la bibliothèque, et après confirmation de la suppression et rafraîchissement de la page (une session différente), le livre ne devrait plus être visible dans les résultats de la recherche.
Éventuellement
Il n'y a pas d'ordre garanti pour les lectures et les écritures, et les répliques finissent par converger vers le même état si aucune autre opération d'écriture n'est effectuée. Dans le cas d'une cohérence "éventuelle", les répliques commencent à travailler sur les requêtes de lecture avec les dernières valeurs mises à jour. Le niveau de cohérence "éventuellement" est le plus faible des quatre.
 Cohérence éventuelle
Cohérence éventuelle
Cependant, selon le théorème PACELC, la latence de recherche peut être considérablement réduite en sacrifiant la cohérence. C'est pourquoi le niveau de cohérence éventuelle est le mieux adapté aux scénarios qui n'exigent pas une grande cohérence des données, mais qui requièrent des performances de recherche ultra-rapides. Un exemple peut être la recherche d'avis et d'évaluations de produits Amazon avec le niveau "eventually consistent".
Garantie de l'horodatage
Milvus réalise différents niveaux de cohérence en introduisant l'horodatage de garantie (GuaranteeTs).
Un horodatage de garantie sert à informer les nœuds de requête qu'une recherche ou une requête ne sera pas exécutée tant que toutes les données antérieures à l'horodatage de garantie ne peuvent pas être vues par les nœuds de requête. Lorsque vous spécifiez le niveau de cohérence, celui-ci est associé à une valeur de garantie spécifique. Différentes valeurs de GuaranteeTs correspondent à différents niveaux de cohérence :
Fort: La valeur de GuaranteeTs est identique à l'horodatage le plus récent du système, et les nœuds d'interrogation attendent que toutes les données antérieures à l'horodatage le plus récent du système soient visibles avant de traiter la demande de recherche ou d'interrogation.
Stabilité limitée: GuaranteeTs est relativement plus petit que l'horodatage le plus récent du système, et les nœuds d'interrogation effectuent des recherches sur une vue de données tolérable et moins mise à jour.
Session: Le client utilise l'horodatage de la dernière opération d'écriture comme GuaranteeTs, de sorte que chaque client puisse au moins récupérer les données insérées par le même client.
Éventuellement: GuaranteeTs est fixé à une valeur très faible afin d'ignorer le contrôle de cohérence. Les nœuds d'interrogation effectuent une recherche immédiate sur la vue de données existante.
Voir Comment fonctionne GuaranteeTs pour plus d'informations sur le mécanisme garantissant différents niveaux de cohérence dans Milvus.
Prochaines étapes
- Apprendre à régler le niveau de cohérence lorsque