Overview of Milvus Deployment Options
Milvus is a highly performant, scalable vector database. It supports use cases of a wide range of sizes, from demos running locally in Jupyter Notebooks to massive-scale Kubernetes clusters handling tens of billions of vectors. Currently, there are three Milvus deployment options: Milvus Lite, Milvus Standalone, and Milvus Distributed.
Milvus Lite
Milvus Lite is a Python library that can be imported into your applications. As a lightweight version of Milvus, it is ideal for quick prototyping in Jupyter Notebooks or running on smart devices with limited resources. Milvus Lite supports the same APIs as other Milvus deployments. The client-side code interacting with Milvus Lite can also work with Milvus instances in other deployment modes.
To integrate Milvus Lite into your applications, run pip install pymilvus to install it and use the MilvusClient("./demo.db") statement to instantiate a vector database with a local file that persists all your data. For more details, refer to Run Milvus Lite.
Milvus Standalone
Milvus Standalone is a single-machine server deployment. All components of Milvus Standalone are packed into a single Docker image, making deployment convenient. If you have a production workload but prefer not to use Kubernetes, running Milvus Standalone on a single machine with sufficient memory is a good option.
Milvus Distributed
Milvus Distributed can be deployed on Kubernetes clusters. This deployment features a cloud-native architecture, where ingestion load and search queries are separately handled by isolated nodes, allowing redundancy for critical components. It offers the highest scalability and availability, as well as the flexibility in customizing the allocated resources in each component. Milvus Distributed is the top choice for enterprise users running large-scale vector search systems in production.
Choose the Right Deployment for Your Use Case
The selection of a deployment mode typically depends on the development stage of your application:
For Quick Prototyping
If you would like to quickly build something as a prototype or for learning purposes, such as Retrieval Augmented Generation (RAG) demos, AI chatbots, multi-modality search, Milvus Lite itself or a combination of Milvus Lite and Milvus Standalone is suitable. You can use Milvus Lite in notebooks for rapid prototyping and explore various approaches such as different chunking strategies in RAG. You may want to deploy the application built with Milvus Lite in a small-scale production to serve real users, or validating the idea on larger datasets, say more than a few millions of vectors. Milvus Standalone is appropriate. The application logic for Milvus Lite can still be shared as all Milvus deployments have the same client side API. The data stored in Milvus Lite can also be ported to Milvus Standalone with a command line tool.
Small-Scale Production Deployment
For early-stage production, when the project is still seeking product-market fit and agility is more important than scalability, Milvus Standalone is the best choice. It can still scale up to 100M vectors given enough machine resource, while requiring much less DevOps than maintaining a K8s cluster.
Large-Scale Production Deployment
As your business is rapidly growing and the data scale exceeds the capacity of a single server, it’s time to consider Milvus Distributed. You can keep using Milvus Standalone for dev or staging environment for its convenience, and operate the K8s cluster that runs Milvus Distributed. This can sustain you towards tens of billions of vectors, as well as providing flexibility on tailoring the node size for your particular workload, such as high-read, infrequent write or high-write, low read cases.
Local Search on Edge Devices
For searching through private or sensitive on edge devices, you can deploy Milvus Lite on the device without relying on a cloud-based service to do text or image search. This is suitable for cases such as proprietary document search, or on-device object detection.
The choice of Milvus deployment mode depends on your project’s stage and scale. Milvus provides a flexible and powerful solution for various needs, from rapid prototyping to large-scale enterprise deployment.
- Milvus Lite is recommended for smaller datasets, up to a few million vectors.
- Milvus Standalone is suitable for medium-sized datasets, scaling up to 100 million vectors.
- Milvus Distributed is designed for large-scale deployments, capable of handling datasets from 100 million up to tens of billions of vectors.
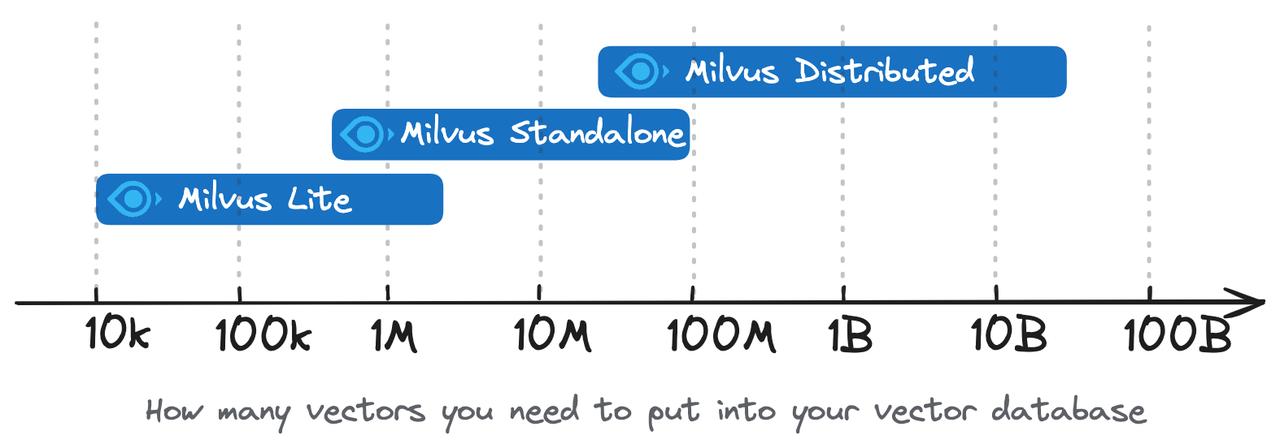 Select deployment option for your use case
Select deployment option for your use case
Comparison on functionalities
| Feature | Milvus Lite | Milvus Standalone | Milvus Distributed |
|---|---|---|---|
| SDK / Client Lirary | Python gRPC | Python Go Java Node.js C# RESTful | Python Java Go Node.js C# RESTful |
| Data types | Dense Vector Sparse Vector Binary Vector Boolean Integer Floating Point VarChar Array JSON | Dense Vector Sparse Vector Binary Vector Boolean Integer Floating Point VarChar Array JSON | Dense Vector Sparse Vector Binary Vector Boolean Integer Floating Point VarChar Array JSON |
| Search capabilities | Vector Search (ANN Search) Metadata Filtering Range Search Scalar Query Get Entities by Primary Key Hybrid Search | Vector Search (ANN Search) Metadata Filtering Range Search Scalar Query Get Entities by Primary Key Hybrid Search | Vector Search (ANN Search) Metadata Filtering Range Search Scalar Query Get Entities by Primary Key Hybrid Search |
| CRUD operations | ✔️ | ✔️ | ✔️ |
| Advanced data management | N/A | Access Control Partition Partition Key | Access Control Partition Partition Key Physical Resource Grouping |
| Consistency Levels | Strong | Strong Bounded Staleness Session Eventual | Strong Bounded Staleness Session Eventual |