Leistung FAQ
Wie stellt man nlist und nprobe für IVF-Indizes ein?
Die Einstellung von nlist ist szenariospezifisch. Als Faustregel gilt, dass der empfohlene Wert von nlist 4 × sqrt(n) ist, wobei n die Gesamtzahl der Entitäten in einem Segment ist.
Die Größe der einzelnen Segmente wird durch den Parameter datacoord.segment.maxSize bestimmt, der standardmäßig auf 512 MB eingestellt ist. Die Gesamtzahl der Entitäten in einem Segment n kann geschätzt werden, indem datacoord.segment.maxSize durch die Größe der einzelnen Entitäten dividiert wird.
Die Einstellung von nprobe ist spezifisch für den Datensatz und das Szenario und beinhaltet einen Kompromiss zwischen Genauigkeit und Abfrageleistung. Wir empfehlen, den idealen Wert durch wiederholtes Experimentieren zu finden.
Die folgenden Diagramme zeigen die Ergebnisse eines Tests, der mit dem sift50m-Datensatz und dem IVF_SQ8-Index durchgeführt wurde und bei dem die Abruf- und Abfrageleistung verschiedener nlist/nprobe -Paare verglichen wurde.
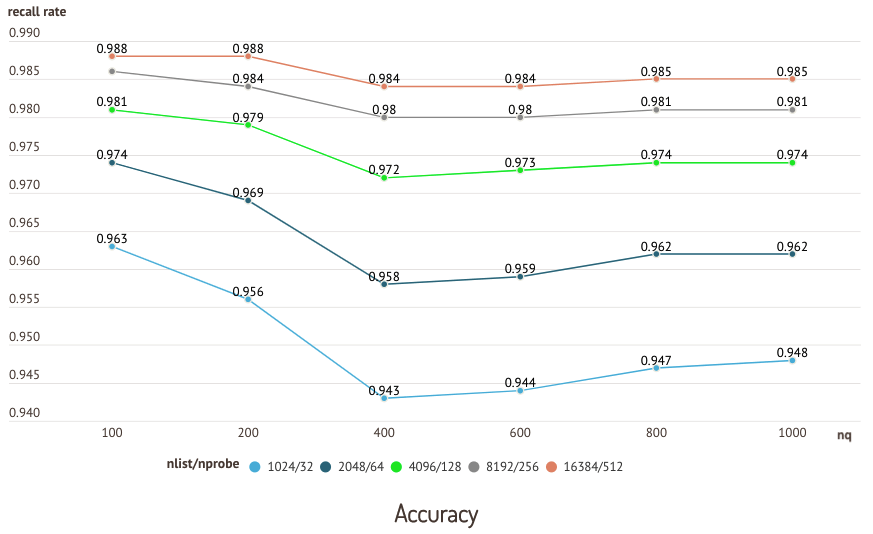 Genauigkeits-Test
Genauigkeits-Test 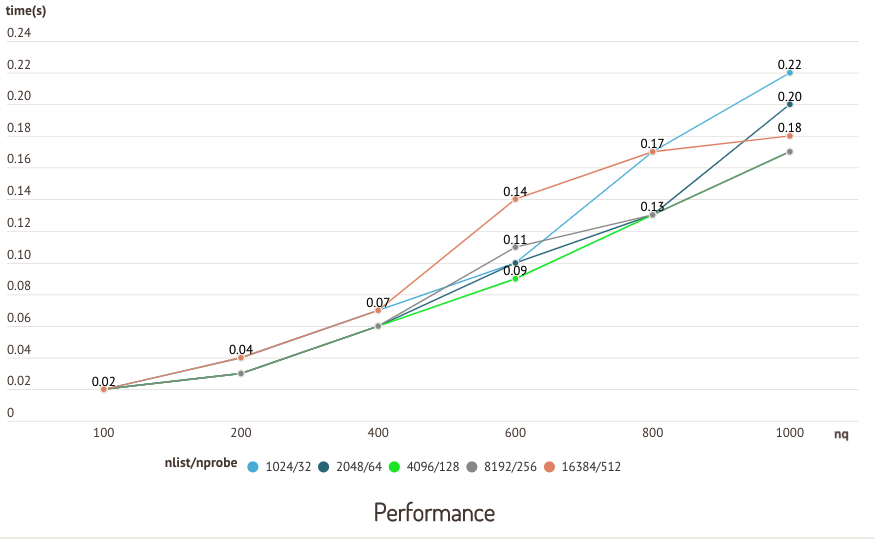 Leistungs-Test
Leistungs-Test
Warum dauern Abfragen auf kleineren Datensätzen manchmal länger?
Abfrageoperationen werden auf Segmenten durchgeführt. Indizes verringern die Zeit, die für die Abfrage eines Segments benötigt wird. Wenn ein Segment nicht indiziert wurde, greift Milvus auf eine Brute-Force-Suche in den Rohdaten zurück, was die Abfragezeit drastisch erhöht.
Daher dauert die Abfrage eines kleinen Datensatzes (einer Sammlung) in der Regel länger, da kein Index erstellt wurde. Der Grund dafür ist, dass die Größe der Segmente nicht den von rootCoord.minSegmentSizeToEnableindex festgelegten Schwellenwert für die Indexerstellung erreicht hat. Rufen Sie create_index() auf, um Milvus zu zwingen, Segmente zu indizieren, die den Schwellenwert erreicht haben, aber noch nicht automatisch indiziert wurden, was die Abfrageleistung erheblich verbessert.
Welche Faktoren beeinflussen die CPU-Auslastung?
Die CPU-Auslastung steigt, wenn Milvus Indizes aufbaut oder Abfragen ausführt. Im Allgemeinen ist die Indexerstellung CPU-intensiv, außer bei Verwendung von Annoy, das auf einem einzigen Thread läuft.
Bei der Ausführung von Abfragen wird die CPU-Auslastung durch nq und nprobe beeinflusst. Wenn nq und nprobe klein sind, ist die Gleichzeitigkeit gering und die CPU-Auslastung bleibt niedrig.
Wirkt sich das gleichzeitige Einfügen von Daten und Suchen auf die Abfrageleistung aus?
Einfügevorgänge sind nicht CPU-intensiv. Da jedoch neue Segmente möglicherweise noch nicht den Schwellenwert für den Indexaufbau erreicht haben, greift Milvus auf die Brute-Force-Suche zurück, was die Abfrageleistung erheblich beeinträchtigt.
Der Parameter rootcoord.minSegmentSizeToEnableIndex bestimmt den Schwellenwert für die Indexerstellung für ein Segment und ist standardmäßig auf 1024 Zeilen eingestellt. Siehe Systemkonfiguration für weitere Informationen.
Wird der Speicherplatz nach dem Löschen von Daten in Milvus sofort wieder freigegeben?
Nein, der Speicherplatz wird nicht sofort freigegeben, wenn Sie Daten in Milvus löschen. Obwohl das Löschen von Daten Entitäten als "logisch gelöscht" kennzeichnet, wird der tatsächliche Speicherplatz möglicherweise nicht sofort freigegeben. Dies ist der Grund:
- Verdichtung: Milvus komprimiert Daten automatisch im Hintergrund. Bei diesem Prozess werden kleinere Datensegmente zu größeren zusammengeführt und logisch gelöschte Daten (zum Löschen markierte Entitäten) oder Daten, die ihre Time-To-Live (TTL) überschritten haben, entfernt. Bei der Verdichtung werden jedoch neue Segmente erstellt, während alte als "fallengelassen" markiert werden.
- Garbage Collection: Ein separater Prozess namens Garbage Collection (GC) entfernt diese "Dropped"-Segmente in regelmäßigen Abständen und gibt den von ihnen belegten Speicherplatz wieder frei. Dies gewährleistet eine effiziente Nutzung des Speichers, kann aber zu einer leichten Verzögerung zwischen dem Löschen und der Wiedergewinnung von Speicherplatz führen.
Kann ich eingefügte, gelöschte oder hochgeladene Daten sofort nach dem Vorgang sehen, ohne auf einen Flush zu warten?
Ja, in Milvus ist die Datentransparenz aufgrund der Disaggregationsarchitektur von Storage und Compute nicht direkt an Flush-Vorgänge gebunden. Sie können die Lesbarkeit der Daten über Konsistenzstufen verwalten.
Bei der Auswahl einer Konsistenzstufe sollten Sie die Kompromisse zwischen Konsistenz und Leistung berücksichtigen. Für Vorgänge, die eine sofortige Sichtbarkeit erfordern, sollten Sie eine "starke" Konsistenzstufe verwenden. Für schnellere Schreibvorgänge sollten Sie eine schwächere Konsistenz bevorzugen (die Daten sind möglicherweise nicht sofort sichtbar). Weitere Informationen finden Sie unter Konsistenz.
Kann die Indizierung eines VARCHAR-Feldes die Löschgeschwindigkeit verbessern?
Die Indizierung eines VARCHAR-Feldes kann die "Delete By Expression"-Operationen beschleunigen, aber nur unter bestimmten Bedingungen:
- INVERTED Index: Dieser Index hilft bei
INoder==Ausdrücken auf VARCHAR-Feldern mit nicht primären Schlüsseln. - Trie-Index: Dieser Index hilft bei Präfix-Abfragen (z.B.
LIKE prefix%) auf nicht-primären VARCHAR-Feldern.
Die Indizierung eines VARCHAR-Feldes führt jedoch nicht zu einer Beschleunigung:
- Löschen nach IDs: Wenn das VARCHAR-Feld der Primärschlüssel ist.
- Unverbundene Ausdrücke: Wenn das VARCHAR-Feld nicht Teil des Löschausdrucks ist.
Haben Sie noch Fragen?
Sie können:
- Schauen Sie sich Milvus auf GitHub an. Sie können Fragen stellen, Ideen austauschen und anderen helfen.
- Treten Sie unserem Discord-Server bei, um Unterstützung zu erhalten und sich mit unserer Open-Source-Community auszutauschen.