Was ist Milvus?
Alles, was Sie in weniger als 10 Minuten über Milvus wissen müssen.
Was sind Vektoreinbettungen?
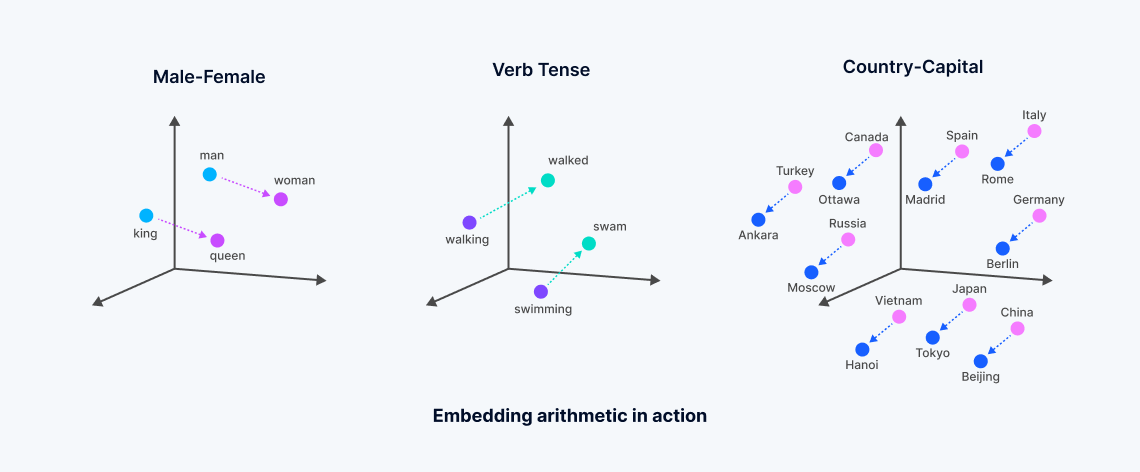
Vektoreinbettungen sind numerische Darstellungen, die aus Machine-Learning-Modellen abgeleitet werden und die semantische Bedeutung unstrukturierter Daten erfassen. Diese Einbettungen werden durch die Analyse komplexer Korrelationen innerhalb von Daten durch neuronale Netze oder Transformer-Architekturen erzeugt, wodurch ein dichter Vektorraum geschaffen wird, in dem jeder Punkt der „Bedeutung“ von Datenobjekten wie Wörtern in einem Dokument entspricht.
Dieser Prozess transformiert textuelle oder andere unstrukturierte Daten in Vektoren, die semantische Ähnlichkeiten widerspiegeln – Wörter mit verwandten Bedeutungen werden in diesem mehrdimensionalen Raum näher beieinander positioniert, was eine Art der Suche ermöglicht, die als „dichte Vektorsuche“ bekannt ist. Dies steht im Gegensatz zur traditionellen Schlüsselwortsuche, die auf exakten Übereinstimmungen basiert und spärliche Vektoren verwendet. Die Entwicklung von Vektoreinbettungen, die oft auf von großen Technologieunternehmen umfassend trainierten Grundmodellen basieren, ermöglicht eine differenziertere Suche, die das Wesen der Daten erfasst und über die Grenzen lexikalischer oder spärlicher Vektorsuchmethoden hinausgeht.
Wofür kann ich Vektoreinbettungen verwenden?
Vektoreinbettungen können in verschiedenen Anwendungen eingesetzt werden, um Effizienz und Genauigkeit auf vielfältige Weise zu verbessern. Hier sind einige der häufigsten Anwendungsfälle:
Ähnliche Bilder, Videos oder Audiodateien finden
Vektoreinbettungen ermöglichen die Suche nach ähnlichen Multimedia-Inhalten nach Inhalt und nicht nur nach Schlüsselwörtern, indem Convolutional Neural Networks (CNNs) verwendet werden, um Bilder, Videobilder oder Audiosegmente zu analysieren. Dies ermöglicht erweiterte Suchvorgänge, wie das Finden von Bildern basierend auf Tonhinweisen oder Videos durch Bildabfragen, indem die eingebetteten Darstellungen, die in Vektordatenbanken gespeichert sind, verglichen werden.
Beschleunigung der Arzneimittelentdeckung
In der pharmazeutischen Industrie können Vektoreinbettungen die chemischen Strukturen von Verbindungen kodieren, wodurch die Identifizierung vielversprechender Wirkstoffkandidaten erleichtert wird, indem ihre Ähnlichkeit zu Zielproteinen gemessen wird. Dies beschleunigt den Prozess der Arzneimittelentdeckung, spart Zeit und Ressourcen, indem der Fokus auf die vielversprechendsten Kandidaten gelegt wird.
Steigerung der Suchrelevanz mit semantischer Suche
Durch das Einbetten interner Dokumente in Vektoren können Organisationen die semantische Suche nutzen, um die Relevanz der Suchergebnisse zu verbessern. Diese Methode verwendet das Konzept der Retrieval Augmented Generation (RAG), um die Absicht hinter Abfragen zu verstehen und Antworten aus den Daten eines Unternehmens durch KI-Modelle wie ChatGPT zu liefern, wodurch irrelevante Ergebnisse und KI-Halluzinationen reduziert werden.
Empfehlungssysteme
Vektoreinbettungen revolutionieren Empfehlungssysteme, indem sie Benutzer und Artikel als Einbettungen darstellen, um Ähnlichkeiten zu messen. Dieser Ansatz ermöglicht personalisierte Empfehlungen basierend auf individuellen Präferenzen, was die Benutzerzufriedenheit und das Engagement mit Online-Plattformen erhöht.
Anomalieerkennung
In Bereichen wie Betrugserkennung, Netzwerksicherheit und industrieller Überwachung sind Vektoreinbettungen entscheidend für die Identifizierung ungewöhnlicher Muster. Datenpunkte, die als Einbettungen dargestellt werden, ermöglichen die Erkennung von Anomalien durch die Berechnung von Abständen oder Unähnlichkeiten, was die frühzeitige Identifizierung und präventive Maßnahmen gegen potenzielle Probleme erleichtert.
Was sind Vektordatenbanken?
Vektordatenbanken sind spezialisierte Systeme, die für die Verwaltung und den Abruf unstrukturierter Daten durch Vektoreinbettungen und numerische Darstellungen entwickelt wurden, die das Wesen von Datenobjekten wie Bildern, Audio, Videos und Textinhalten erfassen. Im Gegensatz zu traditionellen relationalen Datenbanken, die strukturierte Daten mit präzisen Suchoperationen verarbeiten, zeichnen sich Vektordatenbanken durch semantische Ähnlichkeitssuchen aus, die Techniken wie den Approximate Nearest Neighbor (ANN)-Algorithmus verwenden. Diese Fähigkeit ist entscheidend für die Entwicklung von Anwendungen in verschiedenen Bereichen, einschließlich Empfehlungssystemen, Chatbots und Multimedia-Inhaltssuchwerkzeugen, und für die Bewältigung der Herausforderungen, die KI und große Sprachmodelle wie ChatGPT mit sich bringen, wie das Verständnis von Kontext und Nuancen sowie KI-Halluzinationen.
Die Einführung von Vektordatenbanken wie Milvus verändert Branchen, indem sie inhaltsbasierte Suchen über eine Vielzahl unstrukturierter Daten ermöglichen und über die Grenzen menschlich generierter Labels hinausgehen. Wichtige Merkmale, die Vektordatenbanken auszeichnen, sind:
Skalierbarkeit und Anpassungsfähigkeit, um wachsende Datenmengen zu bewältigen
Mehrinstanzenfähigkeit und Datenisolation für effiziente Ressourcennutzung und Datenschutz
Ein umfassendes API-Set für verschiedene Programmiersprachen
Benutzerfreundliche Schnittstellen, die die Interaktion mit komplexen Daten vereinfachen.
Diese Attribute stellen sicher, dass Vektordatenbanken den Anforderungen moderner Anwendungen gerecht werden und leistungsstarke Werkzeuge für die Erforschung und Nutzung unstrukturierter Daten bieten, die traditionelle Datenbanken nicht können.
Vektordatenbank vs. Vektorsuchbibliothek
Vektorsuchbibliotheken wie FAISS, ScaNN und HNSW bieten grundlegende Werkzeuge für den Aufbau von Prototypsystemen, die effiziente Ähnlichkeitssuchen und dichte Vektorclustering durchführen können. Diese Bibliotheken, obwohl leistungsstark und Open-Source, sind in erster Linie für den Vektorabruf konzipiert und bieten eine schnelle Einrichtung mit Funktionen wie der Handhabung großer Vektorsammlungen und Schnittstellen für die Bewertung und Parameteranpassung. Sie sind jedoch in Bezug auf Skalierbarkeit, Mehrinstanzenfähigkeit und dynamische Datenänderungen weniger geeignet, was sie für größere, komplexere Datensätze und wachsende Benutzerbasen weniger geeignet macht.
Im Gegensatz dazu bieten Vektordatenbanken eine umfassendere Lösung, die für die Speicherung und den Echtzeitabruf von Millionen bis Milliarden von Vektoren ausgelegt ist. Sie bieten ein höheres Maß an Abstraktion, Skalierbarkeit, Cloud-Nativität und benutzerfreundlichen Funktionen, die die grundlegenden Funktionen von Vektorsuchbibliotheken übertreffen. Während Bibliotheken wie FAISS integrale Bestandteile sind, auf denen Vektordatenbanken aufbauen können, sind letztere vollwertige Dienste, die Operationen wie das Einfügen und Verwalten von Daten vereinfachen und sie besser an die Anforderungen großer, dynamischer Anwendungen im Bereich der unstrukturierten Datenverarbeitung anpassen.
Vektordatenbanken vs. Vektorsuchplugins für traditionelle Datenbanken
Vektordatenbanken und Vektorsuchplugins für traditionelle Datenbanken erfüllen unterschiedliche Rollen bei der Handhabung vektorbasierter Suchen. Plugins wie die in Elasticsearch 8.0 bieten Vektorsuchfunktionen innerhalb bestehender Datenbankarchitekturen und fungieren als Erweiterungen anstatt als umfassende Lösungen. Diese Plugins verfügen nicht über einen Full-Stack-Ansatz für das Einbettungsmanagement und die Vektorsuche, was zu Einschränkungen und suboptimaler Leistung für Anwendungen mit unstrukturierten Daten führt.
Wichtige Funktionen wie Anpassungsfähigkeit und benutzerfreundliche APIs/SDKs, die für den effektiven Betrieb einer Vektordatenbank entscheidend sind, fehlen in Vektorsuchplugins. Beispielsweise ist die ANN-Engine von Elasticsearch, obwohl sie grundlegende Vektorspeicherung und -abfrage unterstützt, durch ihren Indexierungsalgorithmus und die Optionen für Abstandsmetriken eingeschränkt und bietet weniger Flexibilität im Vergleich zu einer dedizierten Vektordatenbank wie Milvus. Milvus, das von Grund auf als Vektordatenbank entwickelt wurde, bietet eine intuitivere API, breitere Unterstützung für Indexierungsmethoden und Abstandsmetriken sowie das Potenzial für SQL-ähnliche Abfragen, was seine Überlegenheit bei der Verwaltung und Abfrage unstrukturierter Daten unterstreicht. Dieser grundlegende Unterschied verdeutlicht, warum Vektordatenbanken mit ihren umfassenden Funktionssätzen und ihrer Architektur, die auf unstrukturierte Daten zugeschnitten ist, Vektorsuchplugins für die optimale Suche und Verwaltung von Vektoreinbettungen vorgezogen werden.
Wie unterscheidet sich Milvus von anderen Vektordatenbanken?
Milvus zeichnet sich als Vektordatenbank durch seine skalierbare Architektur und vielfältigen Fähigkeiten aus, die darauf abzielen, Sucherlebnisse in verschiedenen Anwendungen zu beschleunigen und zu vereinheitlichen. Die wichtigsten Merkmale sind:
Skalierbare und elastische Architektur
Milvus ist für außergewöhnliche Skalierbarkeit und Elastizität entwickelt, um den dynamischen Anforderungen moderner Anwendungen gerecht zu werden. Dies wird durch eine dienstorientierte Architektur erreicht, die Speicher, Koordinatoren und Worker entkoppelt, was eine komponentenweise Skalierung ermöglicht. Dieser modulare Ansatz stellt sicher, dass verschiedene Berechnungsaufgaben unabhängig voneinander skaliert werden können, je nach Arbeitslast, und bietet eine fein abgestimmte Ressourcenzuweisung und Isolation.
Vielfältige Indexunterstützung
Milvus unterstützt eine umfangreiche Palette von über 10 Indextypen, darunter weit verbreitete wie HNSW, IVF, Product Quantization und GPU-basierte Indizierung. Diese Vielfalt ermöglicht es Entwicklern, Suchen nach spezifischen Leistungs- und Genauigkeitsanforderungen zu optimieren, und stellt sicher, dass die Datenbank an eine Vielzahl von Anwendungen und Datenmerkmalen angepasst werden kann. Die kontinuierliche Erweiterung des Indexangebots, z.B. GPU-Index, erhöht die Anpassungsfähigkeit und Effektivität von Milvus bei der Bewältigung komplexer Suchaufgaben weiter.
Vielseitige Suchfähigkeiten
Milvus bietet eine breite Palette von Suchtypen, darunter top-K Approximate Nearest Neighbor (ANN), Range ANN und Suche mit Metadatenfilterung sowie zukünftig hybride dichte und spärliche Vektorsuche. Diese Vielfalt ermöglicht eine unübertroffene Abfrageflexibilität und -genauigkeit, was Entwicklern die Möglichkeit gibt, Datenabrufstrategien an spezifische Anwendungsanforderungen anzupassen und so sowohl die Relevanz als auch die Effizienz der Suchergebnisse zu optimieren.
Anpassbare Konsistenz
Milvus bietet ein Delta-Konsistenzmodell, das es Benutzern ermöglicht, eine „Stale-Toleranz“ für Abfragedaten festzulegen, wodurch eine maßgeschneiderte Balance zwischen Abfrageleistung und Datenaktualität erreicht wird. Diese Flexibilität ist entscheidend für Anwendungen, die aktuelle Ergebnisse ohne Beeinträchtigung der Antwortzeiten benötigen, und unterstützt effektiv sowohl starke als auch eventuelle Konsistenz je nach Anwendungsbedarf.
Hardwarebeschleunigte Rechenunterstützung
Milvus ist darauf ausgelegt, verschiedene Arten von Rechenkapazitäten zu nutzen, wie AVX512 und Neon für SIMD-Ausführung, zusammen mit Quantisierung, cachebewussten Optimierungen und GPU-Unterstützung. Dieser Ansatz ermöglicht eine effiziente Nutzung spezifischer Hardwarestärken und gewährleistet eine schnelle Verarbeitung und kosteneffektive Skalierbarkeit. Durch die Anpassung der Ressourcennutzung an die einzigartigen Anforderungen verschiedener Anwendungen verbessert Milvus sowohl die Geschwindigkeit als auch die Effizienz der Vektordatenverwaltung und Suchoperationen.
Wie funktioniert Milvus in Kürze?
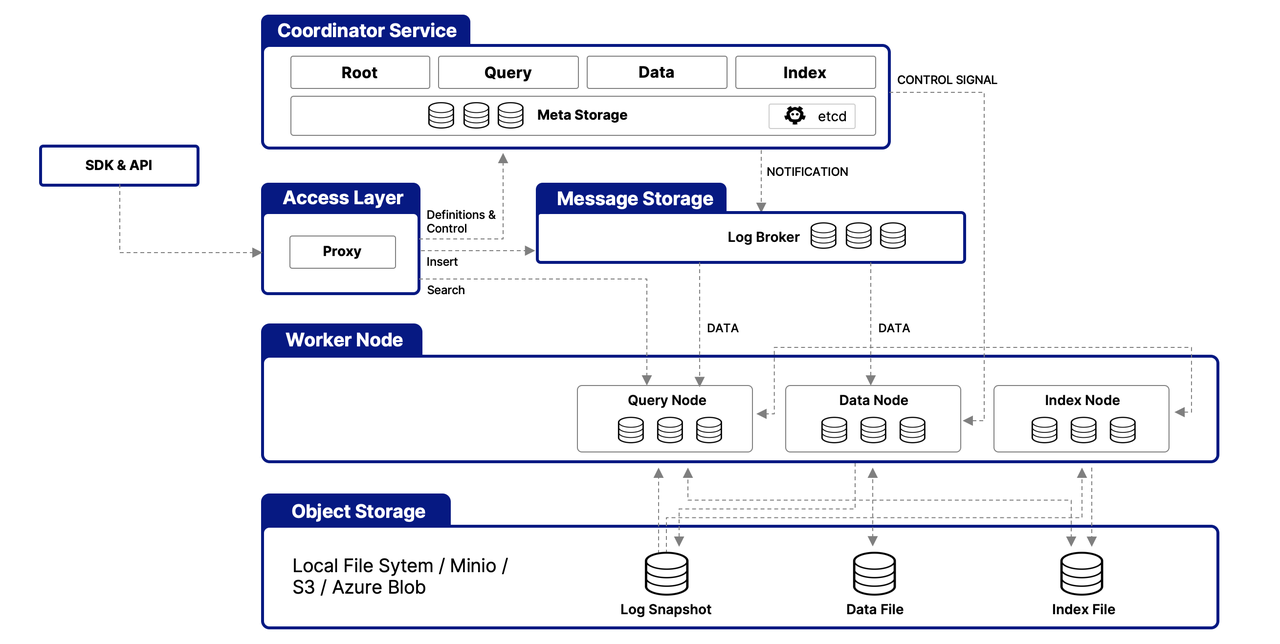
Milvus ist um eine mehrschichtige Architektur herum strukturiert, die darauf ausgelegt ist, Vektordaten effizient zu verarbeiten und zu verwalten, wobei Skalierbarkeit, Anpassungsfähigkeit und Datenisolation gewährleistet werden. Hier ist eine vereinfachte Übersicht über seine Architektur:
Zugriffsschicht
Diese Schicht dient als erster Kontaktpunkt für externe Anfragen und verwendet zustandslose Proxys für die Verwaltung von Client-Verbindungen, statische Überprüfungen und dynamische Prüfungen. Diese Proxys übernehmen auch das Lastenausgleich und sind entscheidend für die Implementierung des umfassenden API-Sets von Milvus. Sobald der nachgelagerte Dienst eine Anfrage verarbeitet hat, leitet die Zugriffsschicht die Antwort zurück an den Benutzer.
Koordinatordienst
Als zentrale Befehlsstelle orchestriert dieser Dienst den Lastenausgleich und die Datenverwaltung durch vier Koordinatoren, die eine effiziente Daten-, Abfrage- und Indexverwaltung gewährleisten.
The Root Coordinator: managing data-related tasks and global timestamps
The Query Coordinator: overseeing query nodes for search operations
The Data Coordinator: handling data nodes and metadata
The Index Coordinator: maintaining index nodes and metadata
Worker-Knoten
Verantwortlich für die tatsächliche Ausführung von Aufgaben, sind Worker-Knoten skalierbare Pods, die Befehle von Koordinatoren ausführen. Sie ermöglichen es Milvus, sich dynamisch an sich ändernde Daten-, Abfrage- und Indexierungsanforderungen anzupassen, und unterstützen die Skalierbarkeit und Anpassungsfähigkeit des Systems.
Objektspeicherschicht
Grundlegend für die Datenpersistenz besteht diese Schicht aus:
Meta store: using etcd for metadata snapshots and system health checks
Log broker: for streaming data persistence and recovery, utilizing Pulsar or RocksDB
Object storage: storing log snapshots, index files, and query results, with support for services like AWS S3, Azure Blob Storage, and MinIO
Wo geht es von hier aus weiter?
- To get hands-on experience with Milvus, follow the get started guide.
- To understand Milvus in more detail, read the Documentation.
- Browse through the Use Cases to learn how other users in our worldwide community are getting value from Milvus.
Join a local Unstructured Data meetup and our Discord.