Thanks to Milvus, Anyone Can Build a Vector Database for 1+ Billion Images
Rising compute power and declining compute costs have made machine-scale analytics and artificial intelligence (AI) more accessible than ever before. In practice, this means with just one server and 10 lines of code, it is possible to build a reverse image search engine capable of querying 1+ billion images in real time. This article explains how Milvus, an open-source vector data management platform, can be used to create powerful systems for unstructured data processing and analysis, as well as the underlying technology that makes this all possible.
Jump to:
- Thanks to Milvus, Anyone Can Build a Vector Database for 1+ Billion Images
- How does AI enable unstructured data analytics?
- Neural networks convert unstructured data into computer-friendly feature vectors - AI algorithms convert unstructured data to vectors
- What are vector data management platforms?
- What are limitations of existing approaches to vector data management? - An overview of Milvus’ architecture.
- What are applications for vector data management platforms and vector similarity search?
- Reverse image search - Google’s “search by image” feature.
- Learn more about Milvus
How does AI enable unstructured data analytics?
An oft-cited statistic is that 80% of the world’s data is unstructured, but just 1% ever gets analyzed. Unstructured data, including images, video, audio, and natural language, doesn’t follow a predefined model or manner of organization. This makes processing and analyzing large unstructured datasets difficult. As the proliferation of smartphones and other connected devices pushes unstructured data production to new heights, businesses are increasingly aware of how important insights derived from this nebulous information can be.
For decades, computer scientists have developed indexing algorithms tailored for organizing, searching, and analyzing specific data types. For structured data, there is bitmap, hash tables, and B-tree, which are commonly used in relational databases developed by tech giants such as Oracle and IBM. For semi-structured data, inverted indexing algorithms are standard, and can be found in popular search engines like Solr and ElasticSearch. However, unstructured data indexing algorithms rely on compute-intensive artificial intelligence that has only become widely accessible in the past decade.
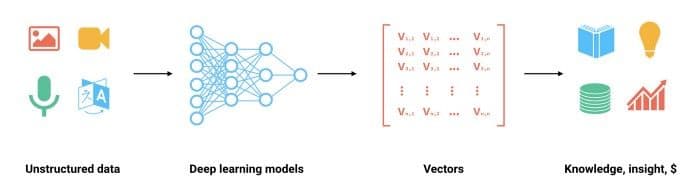
Neural networks convert unstructured data into computer-friendly feature vectors
Using neural networks (e.g. CNN, RNN, and BERT) unstructured data can be converted into feature vectors (a.k.a., embeddings), which are a string of integers or floats. This numerical data format is far more readily processed and analyzed by machines. Applications spanning reverse image search, video search, natural language processing (NLP) and more can be built by embedding unstructured data into feature vectors, then calculating similarity between vectors using measures like Euclidean distance or cosine similarity.
 Blog_Thanks to AI, Anyone Can Build a Search Engine for 1+ Billion Images_2.jpeg
Blog_Thanks to AI, Anyone Can Build a Search Engine for 1+ Billion Images_2.jpeg
Computing vector similarity is a relatively simple process that relies on established algorithms. However, unstructured datasets, even after being converted into feature vectors, are typically several orders of magnitude larger than traditional structured and semi-structured datasets. Vector similarity search is complicated by the sheer storage space and compute power required to efficiently and accurately query massive-scale unstructured data. However, if some degree of accuracy can be sacrificed, there are various approximate nearest neighbor (ANN) search algorithms that can drastically improve query efficiency for massive datasets with high dimensionality. These ANN algorithms decrease storage requirements and computation load by clustering similar vectors together, resulting in faster vector search. Commonly used algorithms include tree-based, graph-based, and combined ANNs.
What are vector data management platforms?
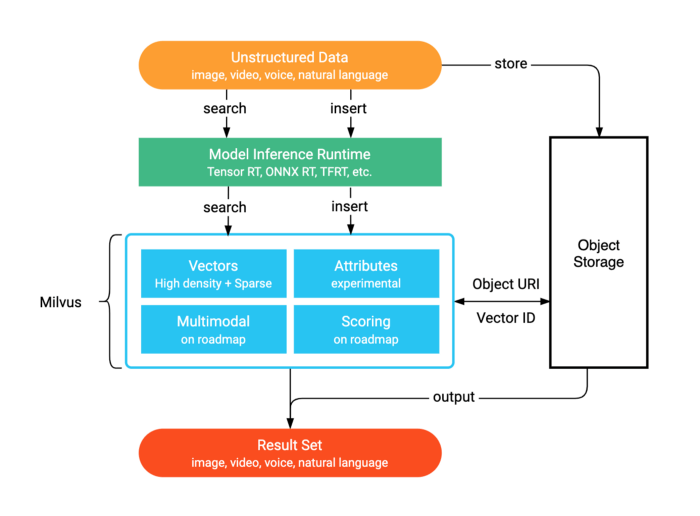
Vector data management platforms are purpose-built applications for storing, processing, and analyzing massive vector datasets. These tools are designed to easily interface with large amounts of data, and include functionality that streamlines vector data management. Unfortunately, few systems exist that are both flexible and powerful enough to solve modern big data challenges. Milvus, a vector data management platform initiated by Zilliz and released under an open-source license in 2019, attempts to fill this void.
What are limitations of existing approaches to vector data management?
A common way to build an unstructured data analytics system is to pair algorithms like ANN with open-source implementation libraries such as Facebook AI Similarity Search (Faiss). Due to several limitations, these algorithm-library combinations are not equivalent to a full-fledged vector data management system like Milvus. Existing technology used for managing vector data faces the following problems:
- Flexibility: By default, existing systems typically store all data in main memory, meaning they cannot be run across multiple machines and are poorly suited for handling massive datasets.
- Dynamic data handling: Data is often assumed to be static once fed into existing systems, complicating processing for dynamic data and making near real-time search impossible.
- Advanced query processing: Most tools do not support advanced query processing (e.g., attribute filtering and multi-vector queries), which is essential for building useful similarity search engines.
- Heterogeneous computing optimizations: Few platforms offer optimizations for heterogenous system architectures on both CPUs and GPUs (excluding Faiss), leading to efficiency losses.
Milvus attempts to overcome all of these limitations. The system enhances flexibility by offering support for a variety of application interfaces (including SDKs in Python, Java, Go, C++ and RESTful APIs), multiple vector index types (e.g., quantization-based indexes and graph-based indexes), and advanced query processing. Milvus handles dynamic vector data using a log-structured merge-tree (LSM tree), keeping data insertions and deletions efficient and searches humming along in real time. Milvus also provides optimizations for heterogeneous computing architectures on modern CPUs and GPUs, allowing developers to adjust systems for specific scenarios, datasets, and application environments.
 Blog_Thanks to AI, Anyone Can Build a Search Engine for 1+ Billion Images_3.png
Blog_Thanks to AI, Anyone Can Build a Search Engine for 1+ Billion Images_3.png
Using various ANN indexing techniques, Milvus is able to achieve a 99% top-5 recall rate. The system is also capable of loading 1+ million data entries per minute. This results in query time of less than one second when running a reverse image search on 1 billion images. As a cloud native application that can operate as a distributed system deployed across multiple nodes, Milvus can easily and reliably achieve similar performance on datasets that contain 10, or even 100, billion images. Additionally, the system is not limited to image data, with applications spanning computer vision, conversational AI, recommendation systems, new drug discovery, and more.
What are applications for vector data management platforms and vector similarity search?
As outlined above, a capable vector data management platform like Milvus paired with approximate nearest neighbor algorithms enables similarity search on gigantic volumes of unstructured data. This technology can be used to develop applications that span a diverse array of fields. Below we briefly explain several common use cases for vector data management tools and vector similarity search.
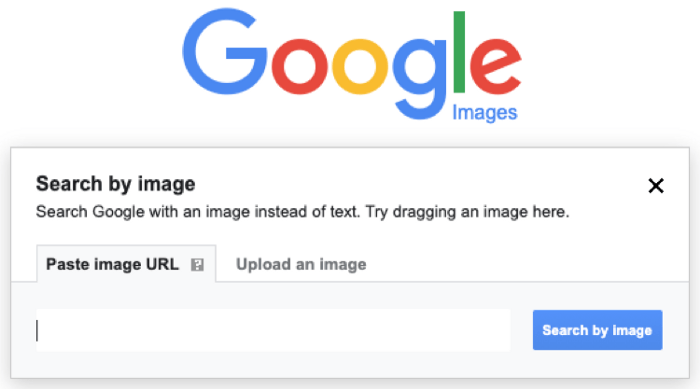
Reverse image search
Major search engines like Google already give users the option to search by image. Additionally, e-commerce platforms have realized the benefits this functionality offers online shoppers, with Amazon incorporating image search into its smartphone applications.
 Blog_Thanks to AI, Anyone Can Build a Search Engine for 1+ Billion Images_4.png
Blog_Thanks to AI, Anyone Can Build a Search Engine for 1+ Billion Images_4.png
Open-source software like Milvus makes it possible for any business to create their own reverse image search system, lowering the barriers to entry for this increasingly in-demand feature. Developers can use pre-trained AI models to convert their own image datasets into vectors, and then leverage Milvus to enable searching for similar products by image.
Video recommendation systems
Major online video platforms like YouTube, which receives 500 hours of user generated content each minute, present unique demands when it comes to content recommendation. In order to make relevant, real-time recommendations that take into consideration new uploads, video recommendation systems must offer lightning-fast query time and efficient dynamic data handling. By converting key frames into vectors and then feeding the results into Milvus, billions of videos can be searched and recommended in near real time.
Natural language processing (NLP)
Natural language processing is a branch of artificial intelligence that aims to build systems that can interpret human languages. After converting text data into vectors, Milvus can be used to quickly identify and remove duplicate text, power semantic search, or even build an intelligent writing assistant. An effective vector data management platform helps maximize the utility of any NLP system.
Learn more about Milvus
If you would like to learn more about Milvus visit our website. Additionally, our bootcamp offers several tutorials, with instructions for setting up Milvus, benchmark testing, and building a variety of different applications. If you’re interested in vector data management, artificial intelligence, and big data challenges, please join our open-source community on GitHub and chat with us on Slack.
Want more information about building an image search system? Check out this case study:
Like the article? Spread the word


