What's new in Milvus 2.1 - Towards simplicity and speed
 What's new in Milvus 2.1 - Towards simplicity and speed
What's new in Milvus 2.1 - Towards simplicity and speed
We are very glad to announce the release of Milvus 2.1 is now live after six months of hard work by all of our Milvus community contributors. This major iteration of the popular vector database emphasizes performance and usability, two most important keywords of our focus. We added support for strings, Kafka message queue, and embedded Milvus, as well as a number of improvements in performance, scalability, security, and observability. Milvus 2.1 is an exciting update that will bridge the “last mile” from the algorithm engineer’s laptop to production-level vector similarity search services.
5ms-level latency
Milvus already supports approximate nearest neighbor (ANN) search, a substantial leap from the traditional KNN method. However, problems of throughput and latency continue to challenge users who need to deal with billion-scale vector data retrieval scenarios.
In Milvus 2.1, there is a new routing protocol that no longer relies on message queues in the retrieval link, significantly reducing retrieval latency for small datasets. Our test results show that Milvus now brings its latency level down to 5ms, which meets the requirements of critical online links such as similarity search and recommendation.
Concurrency control
Milvus 2.1 fine-tunes its concurrency model by introducing a new cost evaluation model and concurrency scheduler. It now provides concurrency control, which ensures that there will not be a large number of concurrent requests competing for CPU and cache resources, nor will the CPU be under-utilized because there are not enough requests. The new, intelligent scheduler layer in Milvus 2.1 also merges small-nq queries that have consistent request parameters, delivering an amazing 3.2x performance boost in scenarios with small-nq and high query concurrency.
In-memory replicas
Milvus 2.1 brings in-memory replicas that improve scalability and availability for small datasets. Similar to the read-only replicas in traditional databases, in-memory replicas can scale horizontally by adding machines when the read QPS is high. In vector retrieval for small datasets, a recommendation system often needs to provide QPS that exceeds the performance limit of a single machine. Now in these scenarios, the system’s throughput can be significantly improved by loading multiple replicas in the memory. In the future, we will also introduce a hedged read mechanism based on in-memory replicas, which will quickly request other functional copies in case the system needs to recover from failures and makes full use of memory redundancy to improve the system’s overall availability.
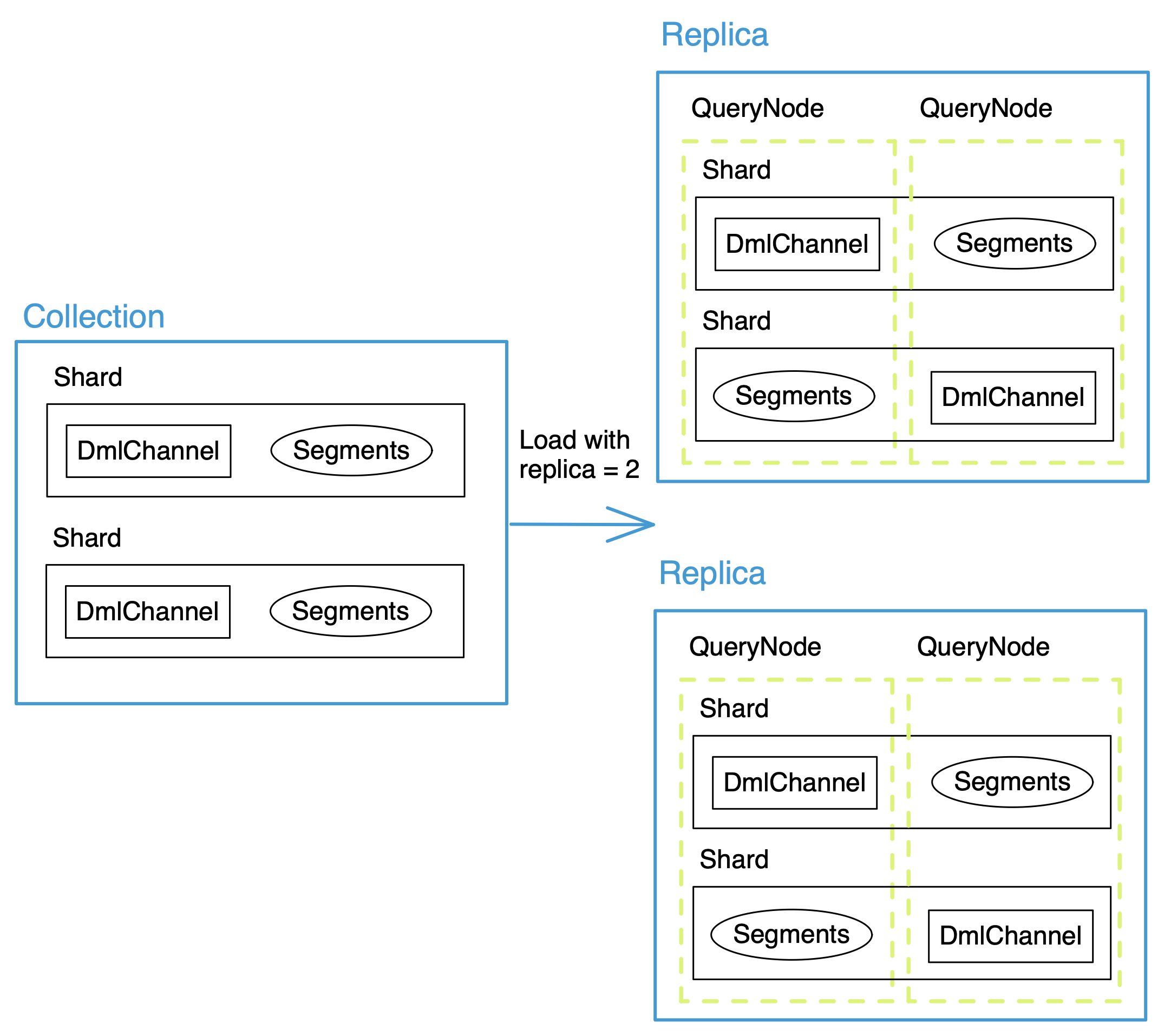 In-memory replicas allow query services to be based on separate
copies of the same data.
In-memory replicas allow query services to be based on separate
copies of the same data.
Faster data loading
The last performance boost comes from data loading. Milvus 2.1 now compresses binary logs with Zstandard (zstd), which significantly reduces data size in the object and message stores as well as network overhead during data loading. In addition, goroutine pools are now introduced so that Milvus can load segments concurrently with memory footprints controlled and minimize the time required to recover from failures and to load data.
The complete benchmark results of Milvus 2.1 will be released on our website soon. Stay tuned.
String and scalar index support
With 2.1, Milvus now supports variable-length string (VARCHAR) as a scalar data type. VARCHAR can be used as the primary key that can be returned as output, and can also act as attribute filters. Attribute filtering is one of the most popular functions Milvus users need. If you often find yourself wanting to "find products most similar to a user in a 300 price range", or "find articles that have the keyword ‘vector database’ and are related to cloud-native topics", you’ll love Milvus 2.1.
Milvus 2.1 also supports scalar inverted index to improve filtering speed based on succinct MARISA-Tries as the data structure. All the data can now be loaded into memory with a very low footprint, which allows much quicker comparison, filtering and prefix matching on strings. Our test results show that the memory requirement of MARISA-trie is only 10% of that of Python dictionaries to load all the data into memory and provide query capabilities.
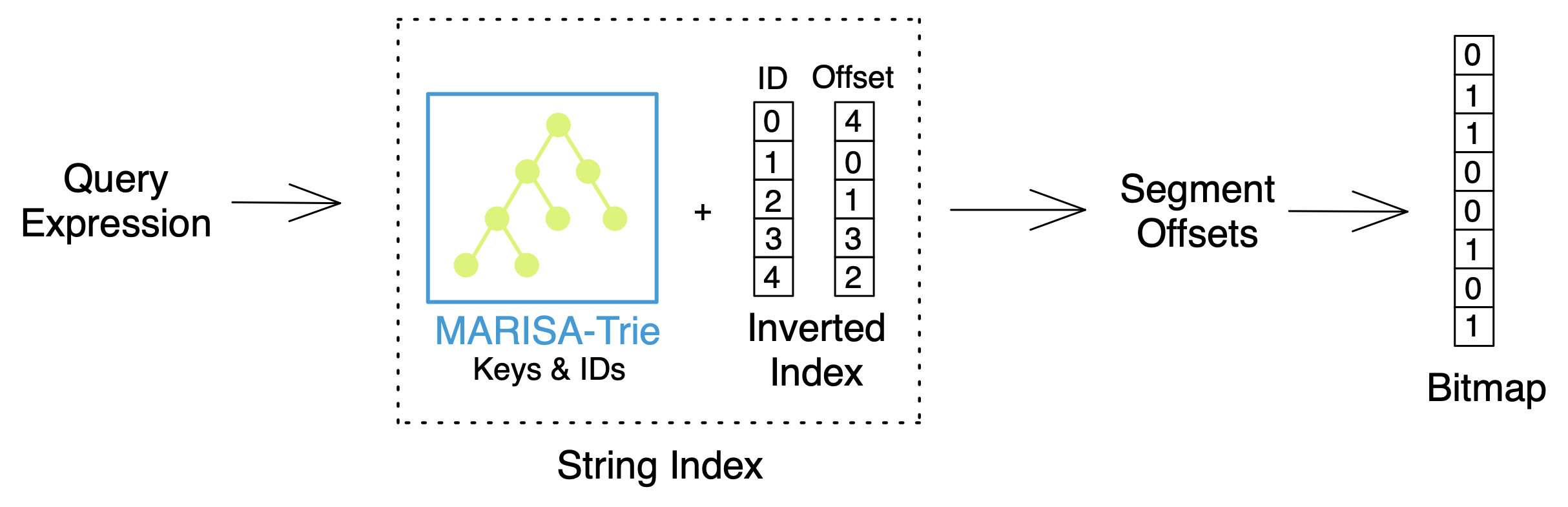 Milvus 2.1 combines MARISA-Trie with inverted index to significantly improve filtering speed.
Milvus 2.1 combines MARISA-Trie with inverted index to significantly improve filtering speed.
In the future, Milvus will continue focusing on scalar query-related developments, support more scalar index types and query operators, and provide disk-based scalar query capabilities, all as part of an ongoing effort to reduce storage and usage cost of scalar data.
Kafka support
Our community has long been requesting support for Apache Kafka as the message storage in Milvus. Milvus 2.1 now offers you the option to use Pulsar or Kafka as the message storage based on user configurations, thanks to the abstraction and encapsulation design of Milvus and the Go Kafka SDK contributed by Confluent.
Production-ready Java SDK
With Milvus 2.1, our Java SDK is now officially released. The Java SDK has the exact same capabilities as the Python SDK, with even better concurrency performance. In the next step, our community contributors will gradually improve documentation and use cases for the Java SDK, and help push Go and RESTful SDKs into the production-ready stage, too.
Observability and maintainability
Milvus 2.1 adds important monitoring metrics such as vector insertion counts, search latency/throughput, node memory overhead, and CPU overhead. Plus, the new version also significantly optimizes log keeping by adjusting log levels and reducing useless log printing.
Embedded Milvus
Milvus has greatly simplified the deployment of large-scale massive vector data retrieval services, but for scientists who want to validate algorithms on a smaller scale, Docker or K8s is still too unnecessarily complicated. With the introduction of embedded Milvus, you can now install Milvus using pip, just like with Pyrocksb and Pysqlite. Embedded Milvus supports all the functionalities of both the cluster and standalone versions, allowing you to easily switch from your laptop to a distributed production environment without changing a single line of code. Algorithm engineers will have a much better experience when building a prototype with Milvus.
Moreover, Milvus 2.1 also has some great improvements in stability and scalability, and we look forward to your use and feedbacks.
What’s next
- See the detailed Release Notes for all the changes in Milvus 2.1
- Install Milvus 2.1 and try out the new features
- Join our Slack community and discuss the new features with thousands of Milvus users around the world
- Follow us on Twitter and LinkedIn to get updates once our blogs on specific new features are out
Edited by Songxian Jiang
- 5ms-level latency
- Concurrency control
- In-memory replicas
- Faster data loading
- String and scalar index support
- Kafka support
- Production-ready Java SDK
- Observability and maintainability
- Embedded Milvus
- What's next
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



