ما هو Milvus؟
كل ما تحتاج إلى معرفته عن Milvus في أقل من 10 دقائق.
ما هي تضمينات المتجهات؟
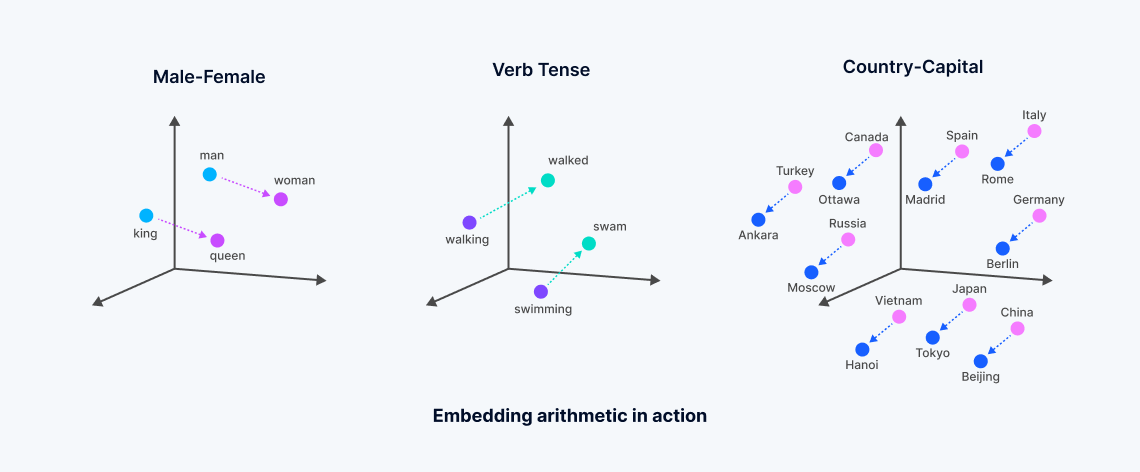
تضمينات المتجهات هي تمثيلات رقمية مستمدة من نماذج التعلم الآلي، تحتوي على المعنى الدلالي للبيانات غير المنظمة. تُنتج هذه التضمينات من خلال تحليل الارتباطات المعقدة داخل البيانات بواسطة الشبكات العصبية أو بنيات المحولات، مما يخلق مساحة متجهات كثيفة حيث يتوافق كل نقطة مع "المعنى" لكائنات البيانات، مثل الكلمات في مستند.
تحول هذه العملية البيانات النصية أو غير المنظمة إلى متجهات تعكس التشابه الدلالي - الكلمات التي تحمل معاني متشابهة توضع بالقرب من بعضها البعض في هذه المساحة متعددة الأبعاد، مما يسهل نوع من البحث يُعرف باسم "البحث بالمتجهات الكثيفة". يتناقض هذا مع البحث التقليدي بالكلمات الرئيسية، الذي يعتمد على التطابق الدقيق ويستخدم المتجهات الخفيفة. تتيح تطوير تضمينات المتجهات، التي غالباً ما تنبع من النماذج الأساسية التي تم تدريبها بشكل كبير من قبل الشركات التكنولوجية الكبرى، إجراء عمليات بحث أكثر دقة تلتقط جوهر البيانات، متجاوزة قيود طرق البحث بالمتجهات الخفيفة أو اللغوية.
ماذا يمكنني استخدام تضمينات المتجهات لأجله؟
يمكن استخدام تضمينات المتجهات في مختلف التطبيقات، مما يعزز الكفاءة والدقة بطرق متنوعة. إليك بعض أكثر الحالات شيوعاً:
العثور على صور أو مقاطع فيديو أو ملفات صوتية مماثلة
تتيح تضمينات المتجهات البحث عن محتوى متعدد الوسائط مماثل حسب المحتوى بدلاً من الكلمات الرئيسية فقط، باستخدام الشبكات العصبية التقليدية (CNNs) لتحليل الصور، إطارات الفيديو، أو مقاطع الصوت. يتيح ذلك إجراء عمليات بحث متقدمة، مثل العثور على صور بناءً على إشارات صوتية أو مقاطع فيديو من خلال استعلامات الصور، من خلال مقارنة التمثيلات المضمنة المخزنة في قواعد بيانات المتجهات.
تسريع اكتشاف الأدوية
في صناعة الأدوية، يمكن أن ترمز تضمينات المتجهات لبنيات المركبات الكيميائية، مما يسهل تحديد المرشحين الواعدين للأدوية من خلال قياس تشابهها مع البروتينات المستهدفة. يسرع هذا عملية اكتشاف الأدوية، مما يوفر الوقت والموارد من خلال التركيز على أكثر الفرص جدوى.
تعزيز أهمية البحث باستخدام البحث الدلالي
من خلال تضمين المستندات الداخلية في متجهات، يمكن للمنظمات استغلال البحث الدلالي لتحسين أهمية نتائج البحث. تستخدم هذه الطريقة مفهوم توليد الاسترجاع المعزز (RAG) لفهم النية وراء الاستعلامات، مما يوفر إجابات من بيانات الشركة من خلال نماذج الذكاء الاصطناعي مثل ChatGPT، مما يقلل من النتائج غير المرتبطة والهلوسات الذكاء الاصطناعي.
أنظمة التوصية
تثور تضمينات المتجهات في أنظمة التوصية من خلال تمثيل المستخدمين والعناصر كتضمينات لقياس التشابه. تتيح هذه الطريقة تقديم توصيات مخصصة بناءً على التفضيلات الفردية، مما يعزز رضا المستخدمين والتفاعل مع المنصات الإلكترونية.
كشف الشذوذ
في مجالات مثل كشف الاحتيال، وأمن الشبكة، ومراقبة الصناعة، تكون تضمينات المتجهات أداة أساسية في تحديد الأنماط غير العادية. تتيح نقاط البيانات الممثلة كتضمينات الكشف عن الشذوذ من خلال حساب المسافات أو الاختلافات، مما يسهل التعرف المبكر واتخاذ تدابير وقائية ضد المشكلات المحتملة.
ما هي قواعد البيانات المتجهة؟
قواعد بيانات المتجهات هي أنظمة متخصصة مصممة لإدارة واسترجاع البيانات غير المنظمة من خلال تضمينات المتجهات والتمثيلات الرقمية التي تلتقط جوهر عناصر البيانات مثل الصور، والصوت، ومقاطع الفيديو، والمحتوى النصي. على عكس قواعد البيانات العلائقية التقليدية التي تتعامل مع البيانات المنظمة مع عمليات بحث دقيقة، تتميز قواعد بيانات المتجهات في عمليات البحث عن التشابه الدلالي باستخدام تقنيات مثل خوارزمية الجار الأقرب التقريبي (ANN). تكون هذه القدرة حاسمة في تطوير تطبيقات في مجالات متعددة، بما في ذلك أنظمة التوصية، والروبوتات المحادثة، وأدوات البحث عن محتوى متعدد الوسائط، وللتعامل مع التحديات التي يفرضها الذكاء الاصطناعي ونماذج اللغة الكبيرة مثل ChatGPT، مثل فهم السياق والنغمات والهلوسات الذكاء الاصطناعي.
يحدث ظهور قواعد بيانات المتجهات مثل Milvus تحولاً في الصناعات من خلال تمكين عمليات البحث عن المحتوى عبر مجموعة واسعة من البيانات غير المنظمة، متجاوزاً القيود المفروضة على التسميات التي ينتجها الإنسان. تتميز قواعد بيانات المتجهات بميزات رئيسية مثل
القدرة على التوسع والتوافق للتعامل مع حجم البيانات المتزايد
التعددية وعزل البيانات لاستخدام الموارد بكفاءة والخصوصية
مجموعة شاملة من واجهات برمجة التطبيقات للغات البرمجة المتنوعة
واجهات سهلة الاستخدام تبسط التفاعل مع البيانات المعقدة.
تضمن هذه السمات أن قواعد بيانات المتجهات يمكن أن تلبي متطلبات التطبيقات الحديثة، مما يوفر أدوات قوية لاستكشاف واستغلال البيانات غير المنظمة بطرق لا تستطيع قواعد البيانات التقليدية تحقيقها.
قاعدة بيانات المتجهات مقابل مكتبة البحث عن المتجهات
توفر مكتبات البحث عن المتجهات مثل FAISS، وScaNN، وHNSW أدوات أساسية لبناء أنظمة نموذجية قادرة على إجراء عمليات بحث عن التشابه وتجميع المتجهات الكثيفة بكفاءة. تم تصميم هذه المكتبات، على الرغم من أنها قوية ومفتوحة المصدر، بشكل أساسي لاسترجاع المتجهات وتوفير إعداد سريع مع قدرات مثل التعامل مع مجموعات المتجهات الكبيرة وتوفير واجهات للتقييم وضبط المعلمات. ومع ذلك، فإنها تفتقر إلى القدرة على التوسع، والتعددية، وتعديل البيانات بشكل ديناميكي، مما يجعلها أقل ملاءمة لمجموعات البيانات الأكبر والأكثر تعقيداً وقواعد المستخدمين المتزايدة.
من ناحية أخرى، تظهر قواعد بيانات المتجهات كحل أكثر شمولاً مصمم لاستيعاب تخزين واسترجاع المتجهات في الوقت الفعلي لملايين إلى مليارات المتجهات. توفر هذه القواعد مستوى أعلى من التجريد، والقدرة على التوسع، والقدرة على العمل في السحابة، وميزات سهلة الاستخدام تتجاوز الوظائف الأساسية لمكتبات البحث عن المتجهات. على الرغم من أن المكتبات مثل FAISS هي مكونات أساسية قد تعتمد عليها قواعد بيانات المتجهات، إلا أن الأخيرة هي خدمات مكتملة تبسط عمليات مثل إدراج البيانات وإدارتها، مما يجعلها أكثر ملاءمة لمتطلبات التطبيقات الديناميكية والكبيرة الحجم في مجال معالجة البيانات غير المنظمة.
قواعد بيانات المتجهات مقابل الإضافات البحث عن المتجهات لقواعد البيانات التقليدية
تخدم قواعد بيانات المتجهات والإضافات البحث عن المتجهات لقواعد البيانات التقليدية أدواراً متميزة في التعامل مع عمليات البحث عن المتجهات. توفر الإضافات مثل تلك الموجودة في Elasticsearch 8.0 قدرات البحث عن المتجهات داخل بنيات قواعد البيانات الحالية، وتعمل كتحسينات بدلاً من حلول شاملة. تفتقر هذه الإضافات إلى نهج شامل لإدارة التضمين والبحث عن المتجهات، مما يؤدي إلى قيود وأداء دون المستوى لتطبيقات البيانات غير المنظمة.
تغيب ميزات رئيسية مثل القدرة على التوافق وواجهات البرمجة/مجموعات التطوير القياسية السهلة الاستخدام، وهي ضرورية لتشغيل قاعدة بيانات المتجهات بفعالية، بشكل واضح في الإضافات البحث عن المتجهات. على سبيل المثال، يدعم محرك ANN في Elasticsearch التخزين الأساسي للمتجهات والاستعلامات، ولكنه محدود بخوارزمية الفهرسة وخيارات معايير المسافة، مما يوفر مرونة أقل مقارنة بقاعدة بيانات متجهات مخصصة مثل Milvus. يوفر Milvus، الذي تم تصميمه من الأساس كقاعدة بيانات متجهات، واجهة برمجة تطبيقات أكثر حداثة، ودعم أوسع لطرق الفهرسة ومعايير المسافة، والقدرة على استعلامات شبيهة بـ SQL، مما يبرز تفوقه في إدارة واستعلام البيانات غير المنظمة. يوضح هذا الفرق الأساسي لماذا تُفضل قواعد بيانات المتجهات، مع مجموعات الميزات الشاملة والبنية التحتية المصممة للبيانات غير المنظمة، على الإضافات البحث عن المتجهات لتحقيق أفضل بحث وإدارة لتضمينات المتجهات.
كيف يتميز Milvus عن قواعد بيانات المتجهات الأخرى؟
يتميز Milvus كقاعدة بيانات متجهات ببنيتها القابلة للتوسع وقدراتها المتنوعة المصممة لتسريع وتوحيد تجارب البحث عبر مختلف التطبيقات. أبرز الميزات هي:
البنية القابلة للتوسع والمرنة
تم تصميم Milvus لتوفير قدرة استثنائية على التوسع والمرونة، مما يلبي المتطلبات الديناميكية للتطبيقات الحديثة. يتم تحقيق ذلك من خلال تصميم موجه للخدمات، فصل التخزين، والمنسقات، والعمال، مما يتيح التوسع حسب المكونات. يضمن هذا النهج القائم على الوحدات أن المهام الحسابية المختلفة يمكن أن تتوسع بشكل مستقل وفقاً لأحمال العمل المتغيرة، مما يوفر تخصيص الموارد بدقة وعزلها.
دعم فهارس متنوعة
يدعم Milvus مجموعة واسعة من أكثر من 10 أنواع من الفهارس، بما في ذلك الأنواع المستخدمة على نطاق واسع مثل HNSW، وIVF، وProduct Quantization، والفهرسة على أساس GPU. تتيح هذه التنوع للمطورين تحسين عمليات البحث وفقاً لمتطلبات الأداء والدقة المحددة، مما يضمن أن قاعدة البيانات يمكن أن تتكيف مع مجموعة واسعة من التطبيقات وخصائص البيانات. يعزز توسيع مستمر لعروض الفهرس الخاصة به، مثل فهرس GPU، من قدرة Milvus على التكيف والفعالية في التعامل مع مهام البحث المعقدة.
قدرات البحث المتنوعة
يوفر Milvus مجموعة واسعة من أنواع البحث، بما في ذلك أقرب K Approximate Nearest Neighbor (ANN)، وANN النطاق، والبحث مع تصفية البيانات الوصفية، والبحث الهجين الكثيف والخفيف القادم. تتيح هذه التنوع مرونة ودقة استعلام لا تضاهى، مما يمنح المطورين القدرة على تخصيص استراتيجيات استرجاع البيانات لتلبية متطلبات التطبيقات المحددة، مما يعزز كل من أهمية وكفاءة نتائج البحث.
التوافق القابل للضبط
يوفر Milvus نموذج توافق دلتا يتيح للمستخدمين تحديد "تسامح القدم" لبيانات الاستعلام، مما يتيح توازن مخصص بين أداء الاستعلام وجدة البيانات. تكون هذه المرونة حاسمة للتطبيقات التي تحتاج إلى نتائج حديثة دون المساس بأوقات الاستجابة، مما يدعم كل من التوافق القوي والنهائي وفقاً لاحتياجات التطبيق.
دعم الحساب المعجل بالأجهزة
يتم تصميم Milvus لاستغلال مختلف أنواع قدرات الحساب، مثل AVX512 وNeon لتنفيذ SIMD، بالإضافة إلى الكمية، وتحسينات تخزين الكاشي، ودعم GPU. يتيح هذا النهج استخدام فعال لقوى الأجهزة المحددة، مما يضمن معالجة سريعة وقابلية توسع فعالة من حيث التكلفة. من خلال تخصيص استخدام الموارد لتلبية المتطلبات الفريدة للتطبيقات المختلفة، يعزز Milvus كل من السرعة والكفاءة في عمليات إدارة وبحث البيانات المتجهة.
كيف يعمل Milvus باختصار؟
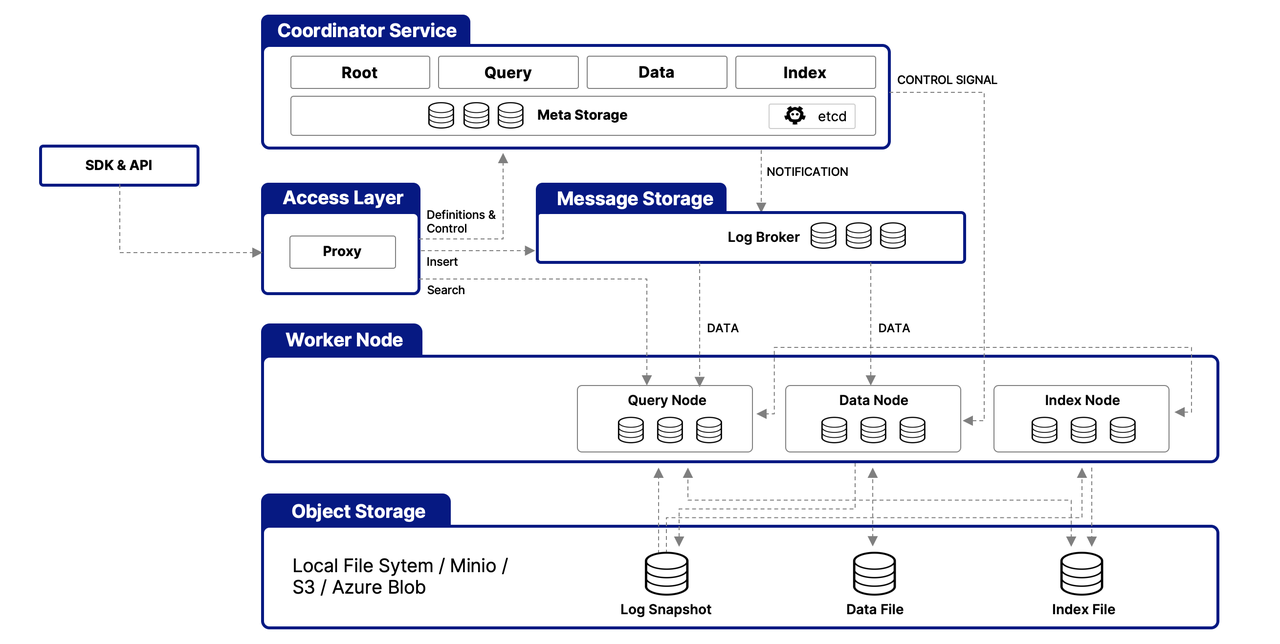
يتم تنظيم Milvus حول بنية متعددة الطبقات مصممة لمعالجة وتحليل بيانات المتجهات بكفاءة، مما يضمن القدرة على التوسع والتوافق وعزل البيانات. إليك نظرة مبسطة على بنيته:
طبقة الوصول
تخدم هذه الطبقة كنقطة اتصال أولية للطلبات الخارجية، باستخدام وكلاء خالية من الحالة لإدارة اتصالات العملاء، والتحقق الثابت، والفحوصات الديناميكية. كما أن هذه الوكلاء تتعامل مع توازن الأحمال وهي ركيزة في تنفيذ مجموعة شاملة من واجهات برمجة التطبيقات الخاصة بـ Milvus. بمجرد معالجة الخدمة المتدفقة للطلب، توجه طبقة الوصول الاستجابة مرة أخرى إلى المستخدم.
خدمة المنسق
باعتبارها القيادة المركزية، تنسق هذه الخدمة توازن الأحمال وإدارة البيانات من خلال أربعة منسقين، والذين يضمنون إدارة فعالة للبيانات، والاستعلامات، والفهارس.
The Root Coordinator: managing data-related tasks and global timestamps
The Query Coordinator: overseeing query nodes for search operations
The Data Coordinator: handling data nodes and metadata
The Index Coordinator: maintaining index nodes and metadata
عقد العمل
المسؤولة عن التنفيذ الفعلي للمهام، عقد العمل هي حاويات قابلة للتوسع تنفذ أوامر من المنسقين. تتيح لـ Milvus التكيف مع المتطلبات المتغيرة للبيانات، والاستعلامات، والفهرسة، مما يدعم القدرة على التوسع والتوافق في النظام.
طبقة تخزين الكائنات
أساسية لاستمرار البيانات، تتكون هذه الطبقة من
Meta store: using etcd for metadata snapshots and system health checks
Log broker: for streaming data persistence and recovery, utilizing Pulsar or RocksDB
Object storage: storing log snapshots, index files, and query results, with support for services like AWS S3, Azure Blob Storage, and MinIO
إلى أين نذهب من هنا؟
- To get hands-on experience with Milvus, follow the get started guide.
- To understand Milvus in more detail, read the Documentation.
- Browse through the Use Cases to learn how other users in our worldwide community are getting value from Milvus.
Join a local Unstructured Data meetup and our Discord.