Milvus란 무엇인가요?
Milvus에 대해 알아야 할 모든 것을 10분 이내에 제공합니다.
벡터 임베딩이란 무엇인가요?
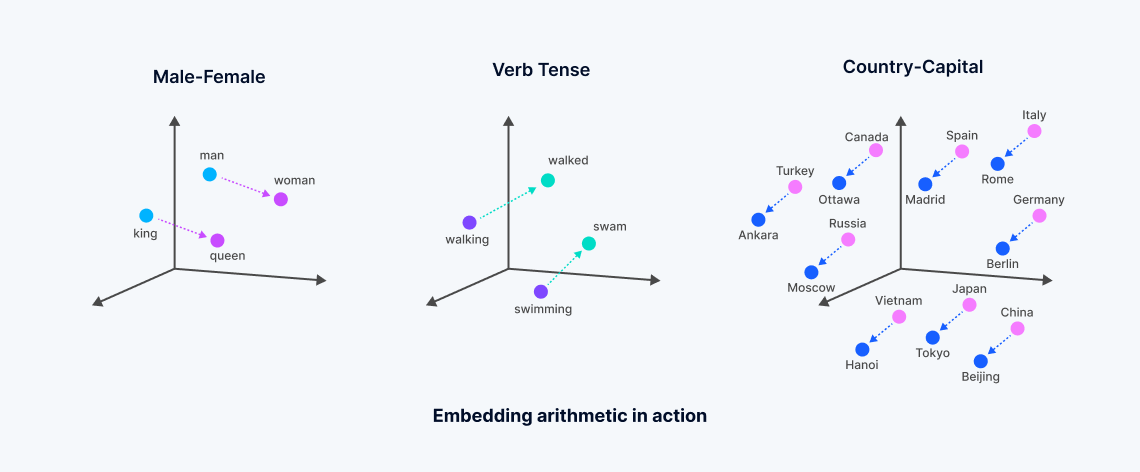
벡터 임베딩은 머신 러닝 모델에서 파생된 숫자 표현으로, 비정형 데이터의 의미를 캡슐화합니다. 이러한 임베딩은 신경망이나 트랜스포머 아키텍처를 통해 데이터 내의 복잡한 상관 관계를 분석하여 생성되며, 단어와 같은 데이터 객체의 "의미"에 해당하는 각 포인트가 있는 밀집 벡터 공간을 만듭니다.
이 프로세스는 텍스트 또는 기타 비정형 데이터를 의미론적 유사성을 반영하는 벡터로 변환합니다. 의미가 관련된 단어는 이 다차원 공간에서 더 가까이 배치되어 "밀집 벡터 검색"이라는 유형의 검색을 용이하게 합니다. 이는 정확한 일치에 의존하고 희소 벡터를 사용하는 전통적인 키워드 검색과는 대조적입니다. 벡터 임베딩의 개발(주로 주요 기술 회사에서 광범위하게 훈련된 기초 모델에서 파생)은 데이터의 본질을 포착하는 더 미묘한 검색을 가능하게 하여 어휘적 또는 희소 벡터 검색 방법의 한계를 넘어섭니다.
벡터 임베딩을 어디에 사용할 수 있나요?
벡터 임베딩은 다양한 애플리케이션에서 효율성과 정확성을 향상시키는 다양한 방법으로 활용할 수 있습니다. 다음은 가장 빈번한 사용 사례 중 일부입니다:
유사한 이미지, 비디오 또는 오디오 파일 찾기
벡터 임베딩을 사용하면 키워드뿐만 아니라 콘텐츠에 따라 유사한 멀티미디어 콘텐츠를 검색할 수 있습니다. 합성곱 신경망(CNN)을 사용하여 이미지, 비디오 프레임 또는 오디오 세그먼트를 분석하여 소리 단서를 기반으로 이미지를 찾거나 이미지 쿼리를 통해 비디오를 찾는 등의 고급 검색을 가능하게 합니다.
약물 발견 가속화
제약 산업에서 벡터 임베딩은 화합물의 화학 구조를 인코딩하여 타겟 단백질과의 유사성을 측정하여 유망한 약물 후보를 식별하는 데 도움을 줍니다. 이를 통해 약물 발견 프로세스가 가속화되어 가장 유망한 리드에 집중함으로써 시간과 자원을 절약할 수 있습니다.
의미론적 검색으로 검색 관련성 향상
내부 문서를 벡터로 임베딩하면 조직은 의미론적 검색을 활용하여 검색 결과의 관련성을 향상시킬 수 있습니다. 이 방법은 검색 의도를 이해하기 위해 Retrieval Augmented Generation(RAG)의 개념을 사용하며, ChatGPT와 같은 AI 모델을 통해 회사의 데이터에서 답변을 제공하여 관련성 없는 결과와 AI 환각을 줄입니다.
추천 시스템
벡터 임베딩은 유사성을 측정하기 위해 사용자와 항목을 임베딩으로 표현하여 추천 시스템을 혁신합니다. 이 접근 방식을 통해 개인의 선호도에 따라 개인화된 추천이 가능하여 온라인 플랫폼에서 사용자 만족도와 참여도를 높입니다.
이상 탐지
사기 탐지, 네트워크 보안 및 산업 모니터링과 같은 분야에서 벡터 임베딩은 비정상적인 패턴을 식별하는 데 필수적입니다. 임베딩으로 표현된 데이터 포인트를 사용하여 거리나 불일치를 계산하여 이상을 탐지하고 잠재적인 문제에 대한 조기 식별 및 예방 조치를 가능하게 합니다.
벡터 데이터베이스란 무엇인가요?
벡터 데이터베이스는 이미지, 오디오, 비디오 및 텍스트 콘텐츠와 같은 데이터 항목의 본질을 포착하는 벡터 임베딩 및 숫자 표현을 통해 비정형 데이터를 관리하고 검색하도록 설계된 전문 시스템입니다. 전통적인 관계형 데이터베이스는 정확한 검색 작업을 사용하여 구조화된 데이터를 처리하는 반면, 벡터 데이터베이스는 근사 최근 이웃(ANN) 알고리즘과 같은 기술을 사용하여 의미론적 유사성 검색에 뛰어납니다. 이 기능은 추천 시스템, 챗봇 및 멀티미디어 콘텐츠 검색 도구를 포함한 다양한 도메인의 애플리케이션 개발과 ChatGPT와 같은 AI 및 대규모 언어 모델이 제기하는 문제를 해결하는 데 필수적입니다.
Milvus와 같은 벡터 데이터베이스의 등장은 인간이 생성한 라벨의 제약을 넘어 광범위한 비정형 데이터에 대한 콘텐츠 기반 검색을 가능하게 하여 산업을 변혁하고 있습니다. 벡터 데이터베이스를 다른 데이터베이스와 구분하는 주요 기능에는 다음이 포함됩니다.
성장하는 데이터 볼륨을 처리할 수 있는 확장성 및 조정 가능성
효율적인 리소스 사용 및 프라이버시를 위한 다중 테넌시 및 데이터 격리
다양한 프로그래밍 언어를 위한 포괄적인 API 스위트
복잡한 데이터와의 상호 작용을 단순화하는 사용자 친화적인 인터페이스
이러한 속성은 벡터 데이터베이스가 현대 애플리케이션의 요구를 충족하고 전통적인 데이터베이스로는 불가능한 방식으로 비정형 데이터를 탐색하고 활용할 수 있는 강력한 도구를 제공하도록 보장합니다.
벡터 데이터베이스 vs. 벡터 검색 라이브러리
FAISS, ScaNN 및 HNSW와 같은 벡터 검색 라이브러리는 효율적인 유사성 검색 및 밀집 벡터 클러스터링을 수행할 수 있는 프로토타입 시스템을 구축하기 위한 기본 도구를 제공합니다. 이러한 라이브러리는 강력하고 오픈 소스이며 주로 벡터 검색을 위해 설계되었으며 대규모 벡터 컬렉션 처리 및 평가 및 매개변수 조정을 위한 인터페이스 제공과 같은 기능을 제공합니다. 그러나 확장성, 다중 테넌시 및 동적 데이터 수정 측면에서 부족하여 더 큰 복잡한 데이터 세트 및 성장하는 사용자 기반에 덜 적합합니다.
반면에 벡터 데이터베이스는 수십억 개의 벡터를 실시간으로 검색하고 저장할 수 있도록 설계된 보다 포괄적인 솔루션으로 등장합니다. 이들은 벡터 검색 라이브러리의 기본 기능을 넘어서는 높은 수준의 추상화, 확장성, 클라우드 네이티브 및 사용자 친화적인 기능을 제공합니다. FAISS와 같은 라이브러리는 벡터 데이터베이스가 구축할 수 있는 중요한 구성 요소이지만 후자는 데이터 삽입 및 관리와 같은 작업을 단순화하는 완전한 서비스입니다. 따라서 대규모 동적 애플리케이션의 요구에 더 잘 맞습니다.
벡터 데이터베이스 vs. 전통적인 데이터베이스의 벡터 검색 플러그인
벡터 데이터베이스와 전통적인 데이터베이스의 벡터 검색 플러그인은 벡터 기반 검색을 처리하는 데 있어 별개의 역할을 합니다. Elasticsearch 8.0과 같은 플러그인은 기존 데이터베이스 아키텍처 내에서 벡터 검색 기능을 제공하며 확장 기능으로 작동하지만 포괄적인 솔루션으로 작동하지는 않습니다. 이러한 플러그인에는 임베딩 관리 및 벡터 검색에 대한 전체 스택 접근 방식이 부족하여 비정형 데이터 애플리케이션에 대한 제한 및 최적이 아닌 성능이 발생합니다.
조정 가능성 및 사용자 친화적인 API/SDK와 같은 주요 기능은 벡터 검색 플러그인에 현저히 부족합니다. 예를 들어 Elasticsearch의 ANN 엔진은 기본 벡터 저장 및 쿼리를 지원하지만 인덱싱 알고리즘 및 거리 메트릭 옵션에 의해 제한되어 Milvus와 같은 전용 벡터 데이터베이스보다 유연성이 떨어집니다. Milvus는 벡터 데이터베이스로 설계되어 더 직관적인 API, 더 넓은 인덱싱 방법 및 거리 메트릭 지원, SQL과 같은 쿼리 가능성을 제공하여 비정형 데이터의 관리 및 쿼리에서 우수합니다. 이 근본적인 차이는 벡터 임베딩의 최적 검색 및 관리를 달성하기 위해 비정형 데이터에 최적화된 포괄적인 기능 세트 및 아키텍처를 갖춘 벡터 데이터베이스가 벡터 검색 플러그인보다 선호되는 이유를 설명합니다.
Milvus는 다른 벡터 데이터베이스와 어떻게 다른가요?
Milvus는 검색 경험을 가속화하고 통합하기 위해 설계된 확장 가능한 아키텍처와 다양한 기능을 갖춘 벡터 데이터베이스로 돋보입니다. 주요 기능 강조는 다음과 같습니다:
확장 가능하고 탄력적인 아키텍처
Milvus는 현대 애플리케이션의 동적 요구를 충족하기 위해 예외적인 확장성과 탄력성을 제공하도록 설계되었습니다. 이를 서비스 지향 설계를 통해 스토리지, 코디네이터 및 워커를 분리하여 구성 요소별로 확장하여 실현합니다. 이 모듈식 접근 방식을 통해 다양한 워크로드에 따라 다른 계산 작업이 독립적으로 확장할 수 있도록 하여 세밀한 리소스 할당 및 격리를 제공합니다.
다양한 인덱스 지원
Milvus는 HNSW, IVF, 제품 양자화 및 GPU 기반 인덱싱과 같은 10종류 이상의 인덱스 유형을 지원합니다. 이 다양성을 통해 개발자는 특정 성능 및 정확성 요구 사항에 따라 검색을 최적화하고 데이터 특성의 넓은 범위의 애플리케이션에 데이터베이스가 적응할 수 있도록 보장할 수 있습니다. GPU 인덱스와 같은 인덱스 제공의 지속적인 확장은 Milvus의 적응성과 복잡한 검색 작업 처리 능력을 더욱 향상시킵니다.
다재다능한 검색 기능
Milvus는 상위 K 근사 최근 이웃(ANN), 범위 ANN, 메타데이터 필터링이 있는 검색 및 향후 하이브리드 밀집 및 희소 벡터 검색을 포함한 다양한 검색 유형을 제공합니다. 이 다양성을 통해 비교할 수 없는 쿼리 유연성과 정확성을 실현하여 개발자가 특정 애플리케이션 요구 사항에 맞춰 데이터 검색 전략을 사용자 지정하고 검색 결과의 관련성과 효율성을 모두 최적화할 수 있도록 합니다.
조정 가능한 일관성
Milvus는 사용자가 쿼리 데이터의 "오래된 상태 허용"을 지정할 수 있는 델타 일관성 모델을 제공하여 쿼리 성능과 데이터 신선도 간의 맞춤형 균형을 실현합니다. 이 유연성은 최신 결과를 필요로 하지만 응답 시간을 희생하지 않으려는 애플리케이션에 필수적이며 애플리케이션 요구 사항에 따라 강력한 일관성과 최종 일관성을 모두 효과적으로 지원합니다.
하드웨어 가속 컴퓨팅 지원
Milvus는 AVX512 및 Neon과 같은 SIMD 실행을 위한 하드웨어 기능을 활용하도록 설계되었으며 양자화, 캐시 인식 최적화 및 GPU 지원을 갖추고 있습니다. 이 접근 방식을 통해 특정 하드웨어의 강점을 효율적으로 활용하여 빠른 처리 및 비용 효율적인 확장성을 보장합니다. 다양한 애플리케이션의 고유한 요구 사항에 맞춰 리소스 사용을 조정함으로써 Milvus는 벡터 데이터 관리 및 검색 작업의 속도와 효율성을 향상시킵니다.
Milvus는 어떻게 작동하나요?
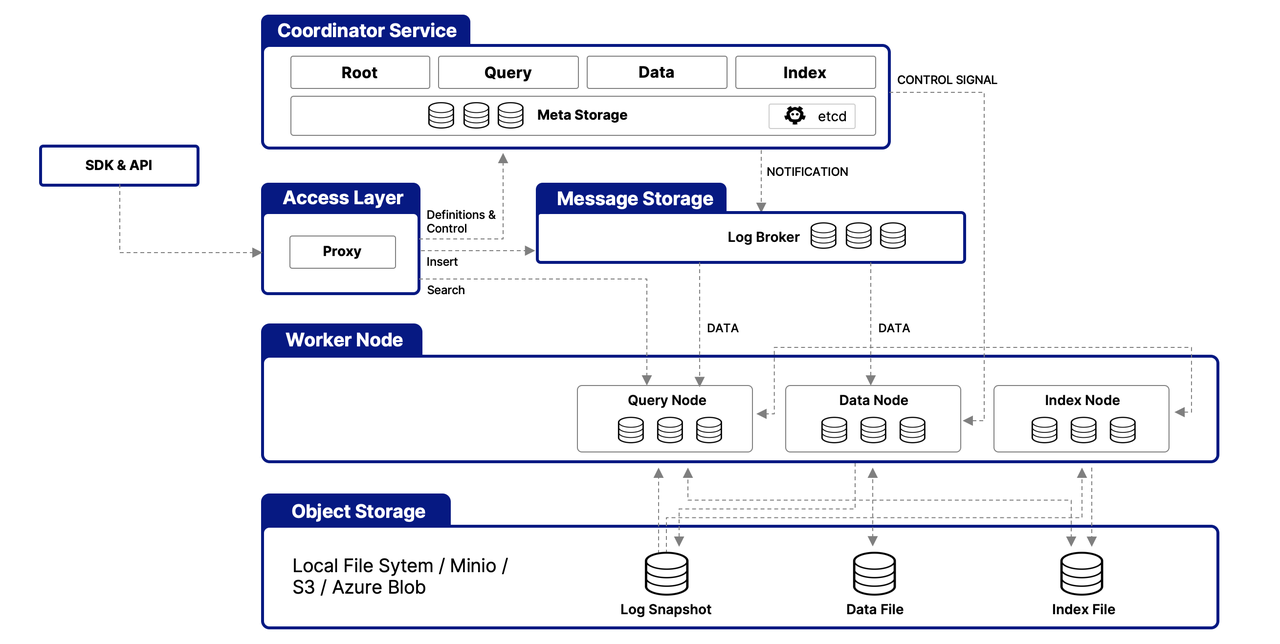
Milvus는 벡터 데이터를 효율적으로 처리하고 확장성, 조정 가능성 및 데이터 격리를 보장하기 위해 설계된 다층 아키텍처를 중심으로 구축되었습니다. 다음은 그 아키텍처의 단순화된 개요입니다:
액세스 계층
이 계층은 외부 요청의 최초 접점 역할을 하며 스테이트리스 프록시를 사용하여 클라이언트 연결 관리, 정적 검증 및 동적 검사를 수행합니다. 이러한 프록시는 또한 로드 밸런싱을 처리하며 Milvus의 포괄적인 API 스위트를 구현하는 데 중요합니다. 다운스트림 서비스가 요청을 처리한 후 액세스 계층은 응답을 사용자에게 라우팅합니다.
코디네이터 서비스
중앙 명령으로 작동하여 4개의 코디네이터를 통해 로드 밸런싱 및 데이터 관리를 조정합니다. 이를 통해 데이터, 쿼리 및 인덱스의 효율적인 관리가 가능합니다.
The Root Coordinator: managing data-related tasks and global timestamps
The Query Coordinator: overseeing query nodes for search operations
The Data Coordinator: handling data nodes and metadata
The Index Coordinator: maintaining index nodes and metadata
워커 노드
실제 작업 실행을 담당하며 코디네이터의 명령을 실행하는 확장 가능한 포드입니다. 이를 통해 Milvus는 변화하는 데이터, 쿼리 및 인덱싱 요구에 동적으로 조정하여 시스템의 확장성과 조정 가능성을 지원합니다.
객체 스토리지 계층
데이터 지속성에 필수적이며 다음 요소로 구성됩니다.
Meta store: using etcd for metadata snapshots and system health checks
Log broker: for streaming data persistence and recovery, utilizing Pulsar or RocksDB
Object storage: storing log snapshots, index files, and query results, with support for services like AWS S3, Azure Blob Storage, and MinIO
이제 어디로 가나요?
- To get hands-on experience with Milvus, follow the get started guide.
- To understand Milvus in more detail, read the Documentation.
- Browse through the Use Cases to learn how other users in our worldwide community are getting value from Milvus.
Join a local Unstructured Data meetup and our Discord.