Loon을 구축한 이유: 끊임없이 변화하는 AI 데이터를 위한 스토리지 엔진.
이 블로그는 원래 zilliz.com에 게시되었으며 허가를 받아 다시 게시되었습니다.
주요 요점
이 블로그는 길고 심층적인 엔지니어링 내용을 다루고 있으므로 자세한 내용을 살펴보기 전에 핵심 사항을 먼저 설명합니다.
- AI 데이터 세트는 정적 테이블이 아닙니다. 팀이 임베딩 모델을 교체하고, 스파스 벡터를 추가하고, 캡션을 수정하고, 레이블을 다시 채우고, 인덱스를 다시 작성하고, 오프라인 분석을 실행하면 동일한 행이 계속 변경됩니다.
- 기존 스토리지 레이아웃은 긴 벡터 열로 인해 백필 비용이 많이 들고, 단일 파일 형식으로는 스캔과 포인트 읽기를 모두 제대로 지원할 수 없으며, 사설 데이터베이스 스토리지는 외부 파이프라인으로 인해 추가 복사본을 만들어야 합니다.
- Loon은 Milvus와 Zilliz 벡터 레이크베이스를 위한 새로운 스토리지 엔진입니다. 하이브리드 파일 형식, 행 ID 정렬, 데이터 세트의 버전 상태를 정의하는 매니페스트를 중심으로 구축되었습니다.
- 그 목표는 데이터를 지속적으로 복사, 재작성 또는 다시 가져오지 않고도 단일 벡터 데이터 세트가 온라인 검색, 오프라인 분석, 백필, 압축 및 외부 컴퓨팅을 지원할 수 있도록 하는 것입니다.
소개
한동안 벡터 데이터베이스를 반대하는 주장이 합리적으로 들리기도 했습니다.
기존 데이터베이스는 이미 정수, 문자열, JSON, 블롭, 인덱스를 저장하고 있습니다. _vector_ 유형을 추가하고 그 옆에 ANN 인덱스를 구축한 다음 하루를 끝내면 어떨까요?
초기 시맨틱 검색의 경우, 그것만으로도 충분히 잘 작동합니다. 벡터 열과 인덱스는 데모, 소규모 RAG 애플리케이션 또는 내부 검색 기능을 지원할 수 있습니다. 문제는 나중에 데이터 세트가 테이블처럼 작동하지 않고 AI 데이터 시스템처럼 작동하기 시작할 때 나타납니다.
프로덕션 벡터 데이터 세트에는 행, 기본 키, 스칼라 필드, 쿼리 가능한 열이 있습니다. 그런 의미에서 데이터베이스 테이블처럼 보입니다. 하지만 데이터 레이크의 규모와 워크플로우 형태도 가지고 있습니다. 데이터 레이크에는 수억 개의 레코드가 포함될 수 있습니다. 이 데이터 레이크는 Spark, Ray, DuckDB, 학습 파이프라인, 평가 작업, 데이터 품질 시스템에 의해 반복적으로 읽히고 다시 쓰여집니다.
또한 객체 스토리지에 따라 달라집니다. 소스 오브젝트는 비디오, 이미지, PDF, 오디오 파일 또는 웹 문서로 S3, GCS, OSS 또는 다른 오브젝트 저장소에 남아 있는 경우가 많습니다. 데이터베이스는 참조, 메타데이터, 파생된 기능, 인덱스를 저장합니다. 그런 다음 고밀도 임베딩, 스파스 벡터, 캡션, 벡터 인덱스, 텍스트 인덱스, 삭제 로그, 통계, 모델 버전, 파서 버전, 외부 블롭 참조 및 이들 간의 버전 관계 등 기존 스토리지 모델이 일급 객체로 관리하도록 구축되지 않은 것들을 추가합니다.
여기서부터 "벡터 열만 추가하면 된다"는 생각은 무너지기 시작합니다. 문제는 데이터베이스가 벡터 바이트를 저장할 수 있는지 여부가 아닙니다. 많은 시스템이 가능합니다. 더 어려운 문제는 스토리지 모델이 벡터 데이터가 변경되는 방식, 쿼리되는 방식, 그리고 AI 데이터 스택 전체에서 공유되는 방식을 처리할 수 있는지 여부입니다.
이것이 바로 Milvus와 Zilliz Vector Lakebase (Zilliz Cloud의 다음 진화 버전)를위한 새로운 스토리지 엔진인 Loon을 구축한 이유입니다 .
Loon은 세 가지 아이디어로 설계되었습니다:
- 다양한 종류의 열에 서로 다른 물리적 형식을 사용하세요.
- 공유 행 ID 공간을 통해 해당 열을 정렬합니다.
- 매니페스트를 사용하여 데이터 세트의 버전 관리 상태를 정의합니다.
이러한 요소들이 왜 중요한지 알아보려면 일반적인 멀티모달 워크플로부터 시작하겠습니다.
벡터 데이터 세트는 결코 완성된 것이 아닙니다.
멀티모달 학습을 위한 비디오 데이터세트를 구축하는 AI 팀을 상상해 보겠습니다.
긴 비디오가 오브젝트 스토리지에 업로드됩니다. 파이프라인이 장면 변경, 샷 경계 또는 시간 창을 기준으로 클립으로 잘라냅니다. 너무 길거나 너무 짧거나, 흐릿하거나, 중복되거나, 품질이 낮은 클립은 필터링됩니다. 나머지 클립은 미적 모델에 의해 점수를 매기고, 다른 모델에 의해 캡션을 붙이고, 비전 언어 모델에 의해 임베드되며, 검색, 중복 제거 및 학습 데이터 필터링을 위해 벡터 데이터베이스에 저장됩니다.
높은 수준에서 보면 워크플로는 간단해 보입니다:
video
→ clips
→ metadata
→ aesthetic_score
→ caption
→ embedding
→ search / dedup / training data filtering
하지만 데이터 세트가 완전히 완성된 상태로 도착하는 것은 아닙니다.
- 첫 주에는 테이블에
clip_id,video_id,start_offset,duration만 포함될 수 있습니다. - 두 번째 주에 팀은
aesthetic_score을 추가합니다. - 세 번째 주에는 캡션 모델이 실행되고 각 클립에
caption. - 넷째 주에는 첫 번째 임베딩 모델이 실행되고 각 클립에 768차원 CLIP 임베딩이 추가됩니다.
- 한 달 후, 팀은 모델을 바꾸고
embedding_v2을 1024 차원으로 다시 채웁니다. - 두 달 후, 하이브리드 검색이 요구사항이 되면서 팀은 스파스 벡터 열을 추가합니다.
- 3개월 후, 캡션은 사람의 검토를 거쳐 제자리에서 수정되어야 합니다.
데이터 세트는 결코 완성되지 않았습니다. 동일한 기본 행에 대한 새로운 해석이 계속 누적되었습니다.
이것이 벡터 데이터와 기존 비즈니스 데이터의 핵심적인 차이점 중 하나입니다. 같은 행이 계속해서 재처리됩니다. 멀티모달 데이터 세트는 수백만 개의 레코드가 아니라 수억 개 또는 수십억 개의 레코드인 경우가 많기 때문에 규모가 커지면 이러한 불편함이 스토리지 문제로 바뀝니다. LAION-5B는 메타데이터, 캡션, 임베딩이 각각 포함된 수십억 개의 이미지-텍스트 쌍으로 구성된 형태에 유용한 참조 자료입니다. 따라서 어려운 부분은 첫 번째 삽입이 아닙니다. 어려운 부분은 데이터 세트가 진화하기 시작한 이후에 일어나는 모든 일입니다. 이러한 진화에는 세 가지 문제가 있습니다.
첫 번째 문제: 긴 열은 쓰기 증폭을 비싸게 만듭니다.
Parquet과 같은 열 형식은 많은 분석 워크로드에 적합합니다. 스키마가 상당히 안정적이고, 데이터를 다시 쓰기보다 더 자주 읽고, 스캔이 열의 하위 집합에만 영향을 미치며, 압축이 중요한 경우에 잘 작동합니다. 이것이 바로 많은 분석 형식이 최적화된 세계입니다.
벡터 행은 분석 행보다 훨씬 넓습니다.
TPC-H lineitem 가 좋은 기준입니다. 여기에는 정수 키, 십진수 값, 날짜, 짧은 문자열, 작은 주석 필드 등 16개의 열이 있습니다. 압축되지 않은 하나의 행은 대략 150바이트입니다. 압축 후에는 훨씬 더 작아질 수 있습니다. 64MB 행 그룹을 사용하면 스토리지 시스템에서 수십만 개의 행을 하나의 그룹에 담을 수 있습니다.
벡터 데이터 세트는 그렇게 보이지 않습니다.
LAION 스타일의 이미지-텍스트 데이터 세트는 오늘날 많은 AI 파이프라인이 생성하는 것에 훨씬 더 가깝습니다. 각 행에는 여전히 URL, 캡션, 너비, 높이, 품질 점수, 레이블 등 일반적인 메타데이터가 있습니다. 하지만 임베딩이 추가되면 행의 물리적 모양이 바뀝니다.
768차원 CLIP 벡터는 fp16에서는 약 1.5KB, fp32에서는 3KB가 소요됩니다. 한 열이 전체 TPC-H lineitem 행보다 훨씬 클 수 있습니다.
그리고 768차원은 오늘날의 기준에서 볼 때 드물거나 크지 않습니다. 멀티모달 파이프라인에서는 1024 차원 또는 2048 차원 임베딩이 일반적입니다. OpenAI의 text-embedding-3-large 는 최대 3072 차원까지 올라가며, 이는 fp32에서 벡터당 약 12KB입니다.
비교가 극명합니다:
| 데이터 세트 모양 | 대략적인 행 크기 | 행을 지배하는 요소 |
|---|---|---|
| TPC-H 라인 항목 | ~150바이트 비압축 | 스칼라 및 짧은 문자열 필드 |
| 768-dim fp16 벡터가 있는 LAION 스타일 행 | ~1.5KB+ | 임베딩 |
| 768-dim fp32 벡터가 포함된 LAION 스타일 행 | ~3KB+ | 임베딩 |
| 3072-dim fp32 벡터를 사용한 행 | 벡터만 ~12KB+ | 임베딩 |
많은 AI 데이터 세트에서 벡터 열은 단순한 필드가 아닙니다. 물리적으로는 행의 대부분을 차지합니다. 따라서 스키마 진화 비용이 달라집니다.
벡터 열 하나를 추가하는 것은 수백 기가바이트를 의미할 수 있습니다.
데이터 세트에 1억 개의 비디오 클립이 있다고 가정해 보겠습니다. 새로운 1024차원 fp32 임베딩 열을 추가하면 약 400GB의 원시 벡터 데이터를 작성해야 합니다. 여기에는 통계, 인덱스, 메타데이터 업데이트, 오브젝트 스토리지 오버헤드, 유효성 검사 또는 서비스 경로 통합은 포함되지 않습니다.

팀이 매달 한두 개의 벡터형 열(예: embedding_v2, sparse_vector, 또는 기능 순위 재조정)을 추가하는 경우, 스키마 진화는 수백 기가바이트 또는 테라바이트 단위로 측정되는 반복적인 다아타 엔지니어링 작업이 됩니다.
작은 논리적 업데이트가 대규모 물리적 재작업을 유발할 수 있음
업데이트도 마찬가지로 중요합니다.
컬럼형 시스템에서는 일반적으로 오래된 데이터는 제자리에서 업데이트되지 않습니다. 삭제 로그에는 변경된 내용이 기록되며, 압축은 나중에 라이브 행을 새 파일로 다시 씁니다. 이 모델은 행이 작을 때 관리하기 쉽습니다.
벡터 데이터의 경우, 작은 논리적 업데이트가 대규모의 물리적 재작성을 유발할 수 있습니다.
사람이 검토하는 작업은 캡션에서 몇 백 바이트만 수정할 수 있습니다. 하지만 캡션, 고밀도 벡터, 스파스 벡터 및 기타 파생된 특징이 동일한 물리적 파일 수명 주기를 공유하는 경우 시스템에서 벡터도 다시 작성하게 될 수 있습니다. 논리적 변경은 작습니다. 물리적 I/O는 엄청날 수 있습니다.
이것이 바로 벡터 스토리지의 쓰기 증폭 문제입니다. 비용이 많이 드는 부분은 벡터가 크다는 것뿐만이 아닙니다. 큰 파생 필드와 작은 가변 필드가 하나의 단위로 취급하는 스토리지 레이아웃에 의해 함께 묶이는 경우가 많다는 것입니다.
AI 데이터 세트의 경우, 백필은 일상적인 워크로드입니다.
기존 분석 테이블의 경우 스키마 진화는 가끔씩만 발생할 수 있습니다. AI 데이터 집합의 경우, 이는 일상적인 작업입니다. 캡션 모델이 업그레이드됩니다. 임베딩 모델이 교체됩니다. 스파스 벡터가 나중에 추가됩니다. 순위 재조정 기능이 나타납니다. 사람 레이블이 수정됩니다. 거버넌스 태그가 다시 채워집니다. 인덱스가 다시 빌드됩니다.
이러한 작업은 단순한 추가가 아닙니다. 기존 행을 수정하거나 확장하는 경우가 많습니다.
그렇기 때문에 벡터 스토리지는 스캔 처리량만 최적화할 수 없습니다. 또한 백필과 부분 업데이트를 더 저렴하게 수행해야 합니다.
두 번째 문제: 동일한 데이터가 스캔과 포인트 읽기를 지원해야 합니다.
데이터가 쓰여지면 읽기 경로가 분할됩니다. 동일한 벡터 데이터 세트에는 일반적으로 분석 스캔과 포인트 읽기의 두 가지 액세스 패턴이 있습니다.
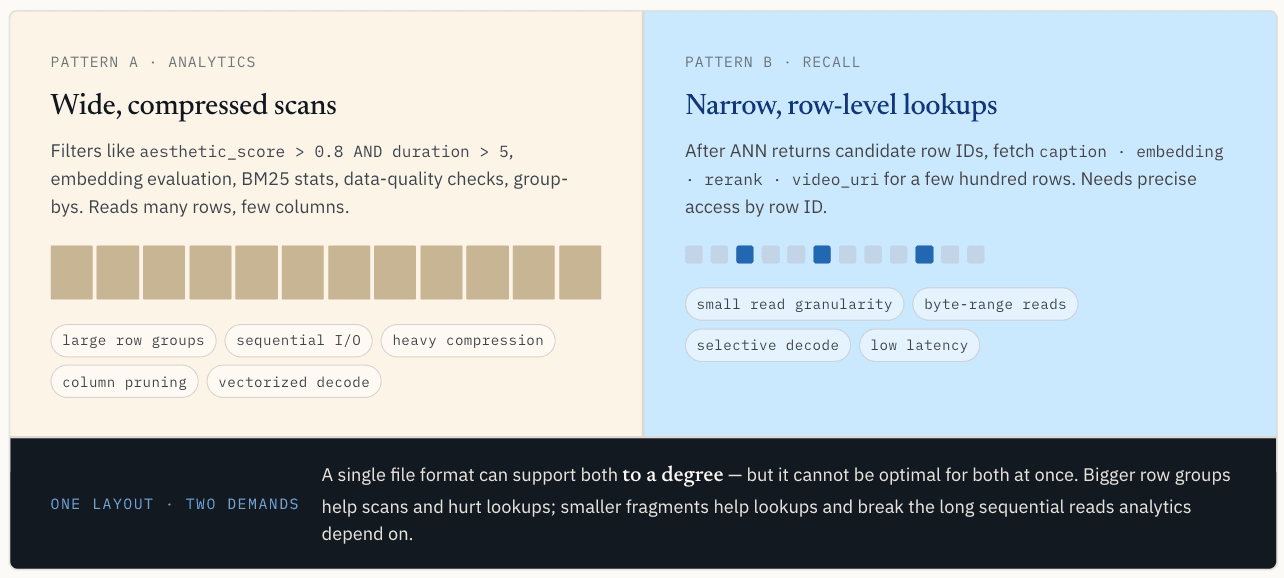
분석 워크로드는 광범위하고 압축된 스캔을 원합니다.
파이프라인은 다음과 같은 필터를 실행할 수 있습니다:
WHERE aesthetic_score > 0.8 AND duration > 5
또는 오프라인 분석, 전체 임베딩 평가, BM25 통계, 비트맵 구성, 데이터 품질 검사, 카운트, 그룹별 분석 등을 실행할 수 있습니다.
이 패턴은 많은 행을 읽지만 열은 몇 개만 읽습니다. 순차적 I/O, 큰 행 그룹, 압축, 열 가지치기, 일괄 디코딩, 벡터화된 실행을 좋아합니다.
여기서 큰 행 그룹이 도움이 됩니다. 하나의 I/O 요청으로 많은 양의 유용한 데이터를 가져오고, 압축 효율을 개선하며, 실행 엔진에 오버헤드를 상각할 수 있는 충분한 연속 데이터를 제공할 수 있습니다. 여러 열을 함께 읽는 경우, 스캔 처리량을 위해 열을 정리하면 벡터화된 실행 중에 캐시 누락을 줄이는 데 도움이 됩니다.
쪽모이 세공은 이 경로에 강합니다.
좁은 범위의 행 수준 조회가 필요한 ANN 결과
ANN 검색이 후보 행 ID를 반환한 후에는 시스템에서 다음과 같은 필드를 가져와야 하는 경우가 많습니다:
caption
embedding
rerank feature
video_uri
metadata
이 패턴은 수백 또는 수천 개의 행을 읽는 경우가 많지만, 행 ID로 정확하게 액세스해야 합니다. 특정 행과 열을 찾고, 필요한 바이트 범위만 가져오고, 몇 개의 레코드를 검색하기 위해 전체 행 그룹을 가져오는 것을 피하고 싶어합니다.
포인트 조회는 스캔과 거의 정반대의 선호도를 가지고 있습니다. 더 작은 읽기 세분성을 원합니다. 이상적으로는 스토리지 계층이 행 ID로 관련 세그먼트 또는 바이트 범위를 찾아 해당 범위만 읽고 결과에 필요한 데이터만 디코딩할 수 있어야 합니다.
압축에도 다른 장단점이 있습니다. 스캔의 경우, 시스템이 많은 데이터를 읽고 I/O를 절약하기 때문에 더 무거운 압축을 사용하는 것이 더 나은 경우가 많습니다. 포인트 조회의 경우, 한 행을 검색하는 데 훨씬 더 큰 압축 블록을 디코딩해야 하는 경우 압축이 문제가 될 수 있습니다.
하나의 레이아웃으로 두 경로를 모두 최적화할 수 없음
이것이 핵심적인 충돌입니다. 스칼라 필터링과 분석은 넓고 압축된 스캔 친화적인 레이아웃을 원합니다. 벡터 조회는 좁고 정밀하며 행 주소 지정이 가능한 레이아웃을 원합니다.
단일 파일 형식은 두 가지를 어느 정도 지원할 수 있지만, 두 가지를 동시에 최적으로 지원할 수는 없습니다.
모든 열이 Parquet에 있는 경우 스칼라 스캔이 편합니다. 그러나 리콜 후 ANN 조회는 더 어려워집니다. 시스템에는 수백 개의 벡터, 캡션 또는 메타데이터 레코드만 필요할 수 있지만, 스토리지 계층에서는 대부분 관련 없는 행이 포함된 대규모 행 그룹을 읽어야 할 수도 있습니다.
로컬 SSD에서는 캐시 및 mmap을 통해 이 비용의 일부를 줄일 수 있습니다. 데이터가 오브젝트 스토리지에 저장되면 비용이 더 눈에 띄게 됩니다. 모든 캐시 누락은 원격 범위 읽기가 될 수 있습니다. 후보 행이 여러 행 그룹에 흩어져 있는 경우, 단일 쿼리가 여러 번의 읽기를 트리거하여 각각 쿼리에 필요한 것보다 더 많은 데이터를 가져올 수 있습니다. 레이아웃이 잘못 배치된 경우, 1,000개의 후보 행을 가져오면 수십 또는 수백 메가바이트의 불필요한 I/O가 발생하기 쉽고, 극단적인 경우에는 훨씬 더 많은 양의 I/O가 발생할 수 있습니다.
행 그룹을 작게 만들면 포인트 조회에는 도움이 되지만 스캔 속도가 저하됩니다. 작은 조각이 너무 많으면 압축 효율이 떨어지고 메타데이터 오버헤드가 증가하며 분석 엔진이 의존하는 긴 순차 읽기가 중단됩니다.
따라서 문제는 하나의 매직 행 그룹 크기를 찾는 것이 아닙니다. 문제는 동일한 데이터 세트가 두 개의 다른 스토리지 시스템처럼 작동하도록 요청받는다는 것입니다.
두 경로를 하나의 쿼리로 강제하는 하이브리드 검색
하이브리드 검색은 이러한 충돌을 무시하기 어렵게 만듭니다. 단일 쿼리는 먼저 스칼라 필터를 적용할 수 있습니다:
aesthetic_score > 0.8 AND duration > 5
그런 다음 ANN 검색을 실행합니다.
그런 다음 행 ID로 캡션, 벡터, 메타데이터를 가져옵니다.
사용자에게는 하나의 검색 요청입니다. 스토리지 계층에서는 분석적 스캔이자 지연 시간이 짧은 무작위 조회입니다.
그렇기 때문에 벡터 스토리지에는 더 나은 Parquet 설정 이상의 것이 필요합니다. 실제로 읽히는 방식에 따라 다른 열을 배치하는 방법이 필요합니다.
세 번째 문제: 데이터 세트가 하나의 엔진 내에 존재하지 않음
처음 두 가지 문제는 데이터베이스 내부에서 발생합니다. 세 번째 문제는 시스템 간의 경계에서 발생합니다.

여러 시스템에 걸쳐 있는 AI 데이터 파이프라인
비디오 워크플로우에서는 벡터 데이터베이스 자체 내에서 일어나는 일은 거의 없습니다.
원본 비디오는 오브젝트 스토리지에 저장됩니다. 클립 생성은 Spark 또는 Ray에서 실행될 수 있습니다. 미적 스코어링은 GPU 서비스에서 실행될 수 있습니다. 캡션은 LLM 추론 파이프라인에서 실행될 수 있습니다. 임베딩은 다른 GPU 작업에서 생성될 수 있습니다. 스파스 벡터는 SPLADE 서비스에서 제공될 수 있습니다. 오프라인 평가, 훈련 데이터 필터링, 휴먼 리뷰, 거버넌스 작업은 모두 다른 곳에서 실행될 수 있습니다.
벡터 데이터베이스는 온라인 검색을 제공하지만 데이터 세트는 많은 시스템에서 생성, 수정, 평가 및 확장됩니다.
비공개 저장 형식은 진실의 사본을 여러 개 생성합니다.
데이터베이스가 자신만 읽고 쓸 수 있는 비공개 물리적 형식을 사용하는 경우, 모든 외부 작업에는 내보내기, 변환, 복사, 가져오기가 필요합니다. 동일한 컬렉션이 데이터베이스, Spark 임시 디렉터리, 평가 출력 및 로컬 백필 디렉터리에 존재할 수 있습니다. 그러면 진짜 문제는 다음과 같습니다:
- 어느 사본이 진실의 소스일까요?
- 어느 것이 지난 달의 캡션 모델을 포함하고 있나요?
- 사람이 검토하여 이미 수정된 행은 어느 것입니까?
- 어떤 스파스 벡터 열이 어떤 모델에 의해 생성되었는가?
- 백필 후에도 여전히 유효한 벡터 인덱스는 무엇인가요?
- 이 행이 참조하는 원본 비디오 개체는 무엇인가요?
소규모 팀에서는 때때로 명명 규칙과 수동 점검으로 버틸 수 있습니다. 하지만 수억 개의 행과 테라바이트의 임베딩이 있는 경우 이는 일관성 문제가 됩니다.
벡터 데이터 세트에는 공유 버전이 필요한 상태
레이크하우스 시스템은 구조화된 데이터에 대해 이 문제를 해결했습니다. Iceberg, Delta Lake, Hudi는 단순히 파일을 저장하는 데 그치지 않습니다. 이 시스템의 핵심은 여러 엔진이 동일한 테이블 상태를 중심으로 조율할 수 있도록 하는 것입니다.
이제 벡터 데이터베이스에도 비슷한 기능이 필요하지만, 그 상태는 더 복잡합니다. 테이블 파일과 파티션뿐만 아니라 벡터 인덱스, 텍스트 인덱스, 스파스 피처, 삭제 로그, 통계, 행 ID 범위, 외부 블롭에 대한 참조도 포함해야 합니다.
문제는 단순히 "Spark가 Milvus 파일을 읽을 수 있는가?"가 아닙니다.
문제는 Spark가 희소 벡터 열을 다시 채운 후, 해당 열이 어느 버전에 속하는지, 어떤 행을 포함하는지, 어떤 모델이 그것을 생성했는지, 온라인 쿼리가 언제 안전하게 사용할 수 있는지 Milvus가 어떻게 알 수 있느냐는 것입니다.
그 해답은 스토리지 모델에 있어야 합니다.
패치로 충분하지 않은 이유
이를 세 가지 개별적인 엔지니어링 문제로 취급하고 싶은 유혹이 있습니다.
- 쓰기 증폭? 일괄 처리를 추가하세요.
- 포인트 읽기? 캐시를 추가하세요.
- 외부 시스템? 내보내기 및 가져오기 도구를 추가하세요.
이러한 패치는 도움이 될 수 있지만, 벡터 데이터 세트가 물리적으로 이질적이라는 근본적인 문제를 해결하지는 못합니다.

비디오 예제에서 clip_id, video_id, duration, aesthetic_score 은 짧은 스칼라 필드입니다. 필터링과 분석에 유용합니다.
caption는 텍스트입니다. BM25, 검토, 수정 및 백필에 사용할 수 있습니다.embedding는 길고 밀도가 높은 벡터입니다. ANN 리콜에 사용되며 나중에 행 수준 조회 또는 재랭크에 사용됩니다.embedding_v2는 새 모델 출력으로, 원본 데이터가 삽입된 지 오래 후에 다시 채워지는 경우가 많습니다.sparse_vector하이브리드 검색을 지원하며 자체적인 액세스 패턴이 있습니다.- 원시 비디오는 오브젝트 스토리지에 보관해야 합니다. 데이터베이스는 참조, 체크섬, MIME 유형, 파서 버전, 행 수준 관계를 저장해야 합니다.
- 벡터 인덱스, 텍스트 인덱스, 통계 및 삭제 로그는 고유한 버전 의미를 가진 파생된 개체입니다.
이러한 객체는 논리적 행을 공유하지만 모두 동일한 물리적 레이아웃이나 수명 주기를 공유해서는 안 됩니다.
- 하나의 일반적인 테이블 레이아웃에 강제로 넣으면 업데이트 비용이 많이 듭니다.
- 하나의 열 형식의 파일 형식으로 강제되면 포인트 읽기가 비용이 많이 듭니다.
- 서로 관련이 없는 객체 파일로 취급되면 버전 관리가 취약해집니다.
따라서 스토리지 모델은 데이터 세트가 이질적이라는 사실에서 출발해야 합니다.
이는 세 가지 설계 요구 사항으로 이어집니다:
- 첫째, 서로 다른 컬럼 그룹은 서로 다른 물리적 형식으로 저장되어야 합니다.
- 둘째, 이러한 열 그룹은 하나의 논리적 테이블처럼 작동할 수 있도록 공유 행 ID 공간이 필요합니다.
- 셋째, 데이터 세트에는 현재 보기에 속하는 파일, 인덱스, 로그, 통계 및 개체 참조를 선언하는 버전이 지정된 매니페스트가 필요합니다.
이것이 바로 Milvus와 Zilliz Cloud의 새로운 스토리지 엔진인 Loon의 설계입니다.
Loon: 진화하는 벡터 데이터 세트를 위한 Milvus와 Zilliz Cloud의 스토리지 엔진
위의 모든 문제를 해결하기 위해, 저희는 진화하는 벡터 데이터 세트를 위해 설계된 Milvus와 Zilliz Vector Lakebase (Zilliz Cloud의 차세대 버전)의 새로운 스토리지 엔진인 Loon을 구축했습니다.
새의 이름을 딴 질리즈의 전통을 따르는 이름입니다. 물오리는 호수에 사는 잠수하는 새로, 쿼리를 실행하거나 열을 다시 채우거나 인덱스를 구축할 때마다 전체 데이터 호수를 이동, 스캔 또는 다시 작성할 필요가 없어야 한다는 시스템의 목표에 잘 부합합니다. 먼저 열, 인덱스, 통계, 삭제 로그 및 개체 참조를 포함한 현재 데이터 세트 버전을 파악한 다음 실제로 필요한 부분만 읽어야 합니다.
하이브리드 파일 형식, 행 ID 정렬, 매니페스트는 서로 다른 세 가지 기능이 아닙니다. 이들은 벡터 데이터 세트가 본질적으로 이질적이라는 동일한 설계 가정에서 비롯된 것입니다.
세 가지 조각, 하나의 스토리지 모델
하이브리드 파일 형식은 열마다 액세스 패턴이 다르다는 것을 인정합니다. 스칼라 필드는 스캔과 필터에 적합합니다. 벡터 필드는 효율적인 행 수준 조회가 필요합니다. 동영상, PDF, 이미지, 오디오 파일과 같은 원시 개체는 데이터베이스 데이터 파일이 아닌 개체 스토리지에 속합니다.
행 ID 정렬은 이러한 열이 물리적으로 분리되어 있을 수 있지만 여전히 동일한 논리적 행을 설명한다는 것을 인정합니다. 캡션, 임베딩, 스파스 벡터, 동영상 URI는 서로 다른 파일과 형식에 존재할 수 있지만 여전히 하나의 결과로 다시 합쳐져야 합니다.
매니페스트는 데이터 세트가 한 번 작성된 후 그대로 방치되지 않음을 인정합니다. 여러 작업을 위해 여러 버전에 걸쳐 여러 시스템에서 수정됩니다. 인덱스, 통계, 삭제 로그, 외부 개체 참조, 열 그룹은 모두 동일한 버전의 보기에 표시되어야 합니다.
이것이 바로 Loon이 단순히 더 빠른 벡터 파일 형식이 아닌 이유입니다. 더 빠른 형식은 포인트 조회에는 도움이 되지만 스키마 진화나 다중 엔진 조정을 해결하지는 못합니다. 행 ID 정렬을 사용하면 분할된 열이 단일 테이블처럼 작동하지만 현재 버전에 속하는 파일을 지정하지는 않습니다. 매니페스트는 데이터 세트 상태를 설명할 수 있지만, 열 그룹과 행 ID 정렬이 없으면 하나의 논리적 컬렉션 내에서 서로 다른 물리적 레이아웃을 깔끔하게 나타낼 수 없습니다.
스토리지 모델에는 열 그룹마다 다른 형식, 행을 재구성하기 위한 공유 행 ID 공간, 모든 독자와 작성자에게 데이터 세트의 현재 상태를 알려주는 버전 관리된 매니페스트 등 이 세 가지가 모두 필요합니다.
Milvus와 Zilliz 벡터 레이크베이스에서 Loon이 적합한 위치
Milvus에서는 기존 세그먼트 빈로그 스토리지 계층을 매니페스트, ColumnGroup, 파일 형식 및 파일 시스템 추상화를 중심으로 구축된 모델로 대체합니다. 질리즈 클라우드의 다음 진화 버전인 질리즈 벡터 레이크베이스에서는 벡터 데이터베이스 서비스 경로를 빠르게 유지하면서 기본 데이터를 더 쉽게 진화, 분석, 외부 시스템과 조정할 수 있도록 하는 벡터 레이크베이스 아키텍처에도 동일한 방향이 적용됩니다.
상위 수준의 Milvus 구성 요소는 여전히 익숙한 역할을 유지합니다. 프록시는 라우팅을 처리합니다. 쿼리코드와 데이터코드는 스케줄링을 처리합니다. IndexNode는 인덱스를 빌드합니다. 컬렉션, 삽입, 검색 및 하이브리드 검색을 위한 애플리케이션 대면 API는 매니페스트 파일이나 ColumnGroups를 노출할 필요가 없습니다.
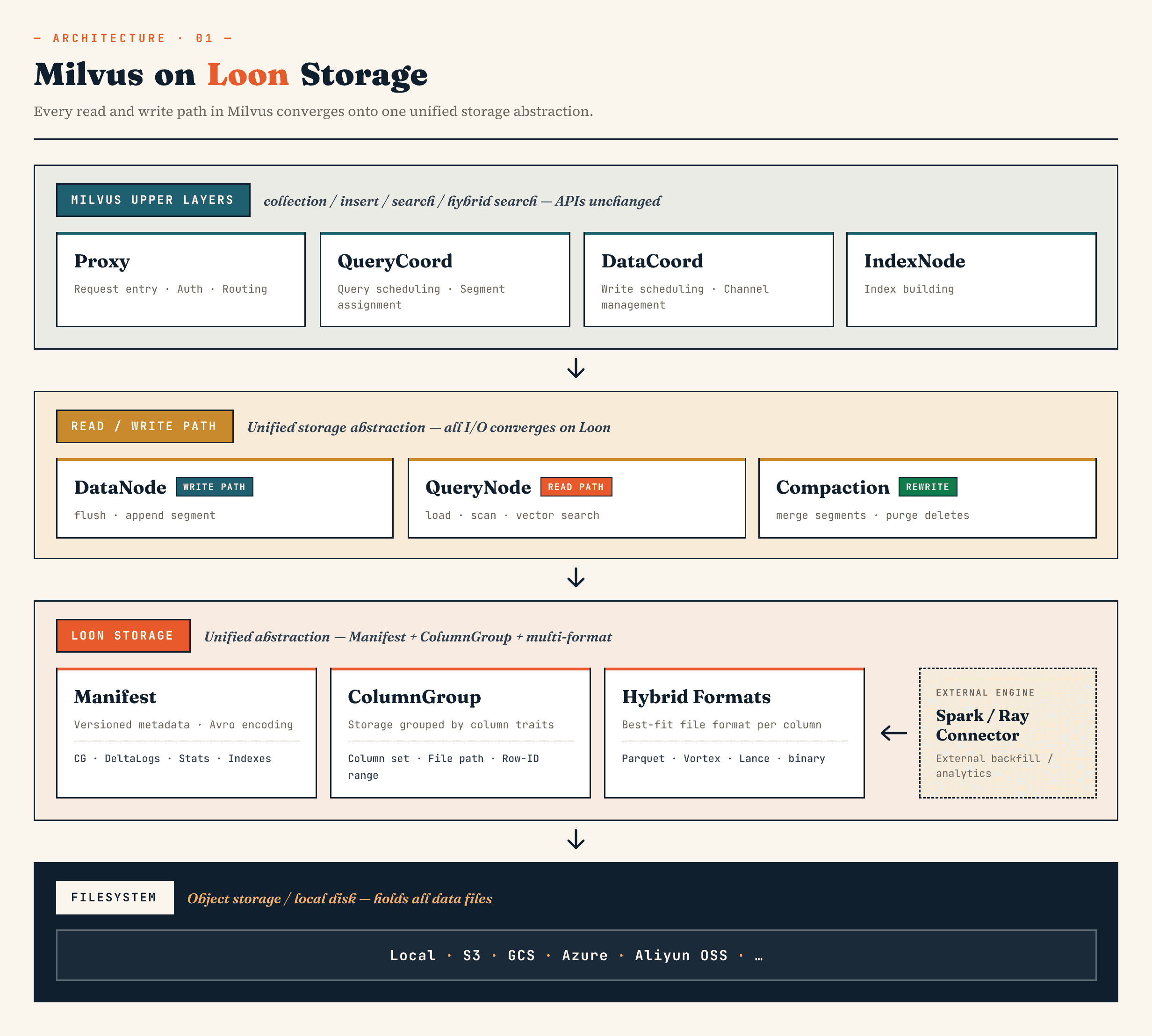
변경 사항은 아래에 있습니다.
데이터 노드, 쿼리 노드, 세그코어, 압축 및 외부 커넥터는 동일한 스토리지 추상화를 통해 작동할 수 있습니다. 이는 데이터 세트가 더 이상 데이터베이스에 의해서만 쓰여지고 읽혀지지 않기 때문에 중요합니다. 외부 컴퓨팅 시스템에 의해 확장되고 동시에 온라인 검색에 의해 소비될 수 있습니다.
높은 수준에서 계층은 다음과 같이 보입니다:
Manifest
→ ColumnGroup
→ file format layer
→ filesystem abstraction
매니페스트는 데이터 세트의 버전이 지정된 상태를 설명합니다. ColumnGroups는 논리적 컬렉션을 물리적 열 그룹으로 매핑합니다. 파일 형식 계층에서는 각 ColumnGroup이 적절한 형식을 선택할 수 있습니다. 파일 시스템 추상화는 객체 스토리지와 로컬 스토리지에서 작동합니다.
중요한 점은 하이브리드 파일 형식, 행 ID 정렬, 매니페스트가 별도의 기능이 아니라는 점입니다. 이들은 함께 스토리지 모델을 정의합니다.
이 모델을 바탕으로 Loon이 서로 다른 ColumnGroup을 저장하는 방법, 이를 다시 행으로 정렬하는 방법, 매니페스트가 해당 파일을 버전화된 데이터 세트로 변환하는 방법 등 세 가지 설계를 하나씩 살펴볼 수 있습니다.
디자인 1: 올바른 컬럼 그룹에 적합한 파일 형식 사용
열마다 액세스 패턴이 다릅니다. 동일한 파일 형식으로 강제해서는 안 됩니다.
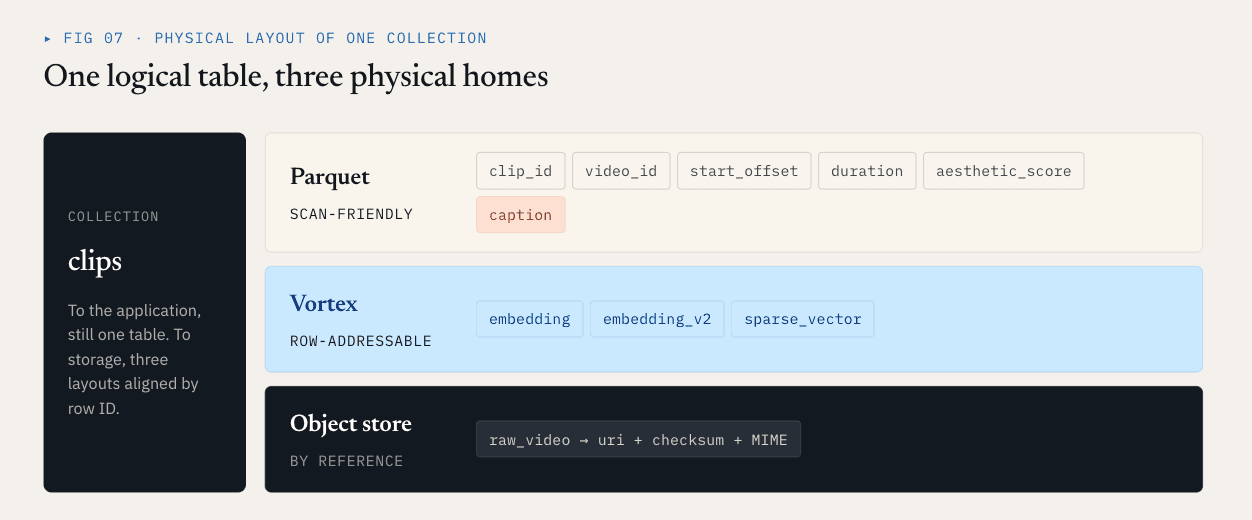
Loon은 논리적 컬렉션을 컬럼 그룹으로 분리합니다.
- 스칼라 필드, 필터 필드, 비즈니스 키, 통계 필드는 종종 스캔, 필터링, 집계 또는 쿼리 계획에 사용됩니다. 이러한 필드들은 압축, 열 가지치기, 에코시스템 호환성의 이점을 누릴 수 있습니다. Parquet은 이러한 열에 적합합니다.
- 고밀도 벡터, 희소 벡터 및 재순위 기능은 종종 행 ID로 ANN이 리콜한 후에 읽습니다. 이러한 기능에는 지연 시간이 짧은 랜덤 액세스, 정확한 바이트 범위 읽기, 선택적 디코딩이 필요합니다. 세그먼트 지향 레이아웃이 더 적합합니다. Loon은 이 방향에서 Vortex를 사용합니다.
- 비디오, PDF, 이미지, 오디오 파일과 같은 원시 객체는 벡터 데이터베이스의 데이터 파일에 포함되지 않아야 합니다. 객체 저장소에 남아 있어야 합니다. 데이터베이스는 참조, 체크섬, MIME 유형, 파서 버전, 행 수준 관계를 기록합니다.
비디오 예제에서 물리적 레이아웃은 다음과 같이 보일 수 있습니다:
Parquet ColumnGroup:
clip_id / video_id / start_offset / duration / aesthetic_score / caption
Vortex ColumnGroups:
embedding
embedding_v2
sparse_vector
Object storage:
raw video objects
애플리케이션의 경우, 이것은 여전히 하나의 컬렉션입니다. 스토리지 계층에서는 해당 컬렉션의 다른 부분이 서로 다른 물리적 형식을 사용합니다. 이렇게 하면 불필요한 재작성이 직접적으로 줄어듭니다. embedding_v2 을 추가하면 새로운 벡터 ColumnGroup과 매니페스트 커밋이 될 수 있습니다. 캡션 열, 스칼라 메타데이터 또는 기존 임베딩 열을 다시 작성할 필요가 없습니다.
스파스 벡터, 재랭크 기능 또는 기타 파생된 필드에도 동일한 아이디어가 적용됩니다. 새 열이 물리적으로 독립적이고 행 ID를 기준으로 정렬될 수 있다면, 동일한 재작성 경로를 통해 관련 없는 열을 끌어다 놓을 필요가 없습니다.
Loon은 파일 형식 사용도 조정합니다.
Parquet의 경우, 기본 설정이 벡터가 많은 데이터에 항상 이상적인 것은 아닙니다. 64MB 행 그룹은 작은 무작위 읽기가 필요 이상으로 많은 데이터를 가져올 수 있기 때문에 포인트 조회에 너무 클 수 있습니다. Loon은 관련 경로에서 행 그룹을 1MB로 좁히고 벡터 열의 사전 인코딩과 같은 인코딩이 무작위로 보이는 벡터 데이터에 도움이 되지 않는 경우 이를 비활성화합니다.
Vortex에서 더 중요한 작업은 레이아웃입니다. Loon은 스캔 효율성과 포인트 룩업의 균형을 맞추는 레이아웃을 사용합니다. 행 그룹 내에서 관련 열의 세그먼트를 서로 가깝게 배치하여 스캔을 지원할 수 있습니다. 작업을 수행하기 위해 하위 세그먼트 읽기를 사용하면 시스템에서 전체 세그먼트를 가져오는 대신 관련 바이트만 가져올 수 있습니다.
Loon은 또한 읽기 전용 Lance 통합을 지원하므로 호환성이 중요한 경우 기존 Lance 데이터세트를 ColumnGroup으로 마운트할 수 있습니다.
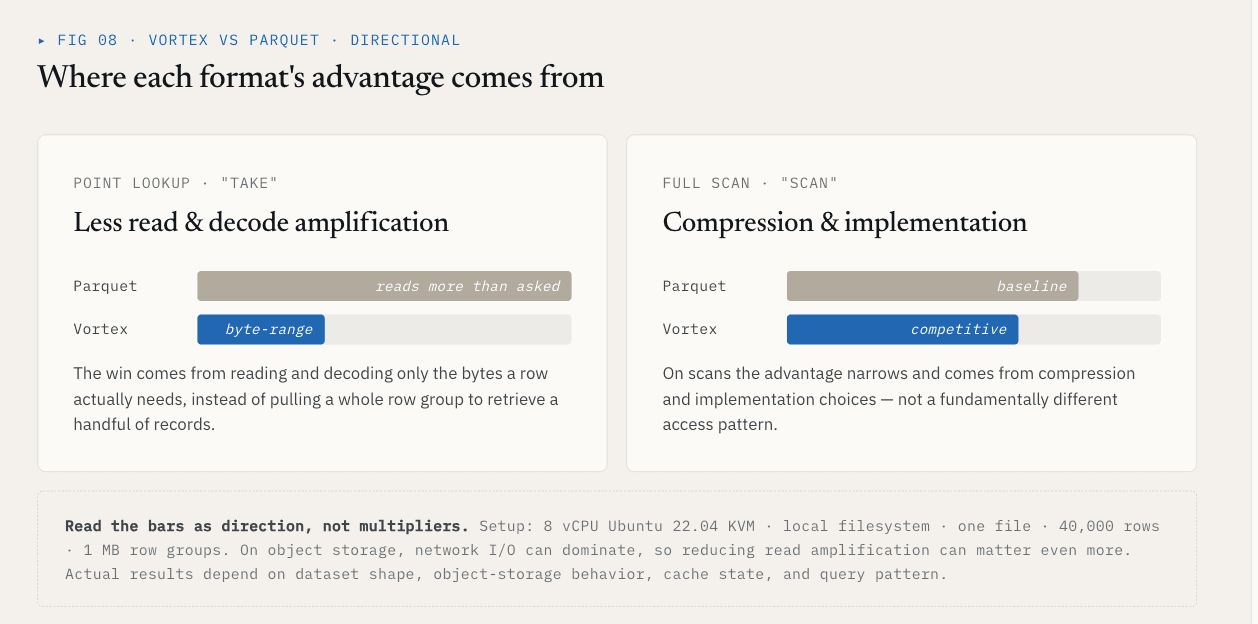
벤치마크 결과
40,000개의 행이 있는 단일 파일과 스키마 {id: int64, name: utf8, value: float64, vector: list<float32>[128]} 를 사용한 한 로컬 테스트에서 Vortex는 1MB 행 그룹이 있는 Parquet에 대해 이러한 결과를 보여주었습니다:
| 작업 | Vortex | Parquet | 차이 |
|---|---|---|---|
| 소요 시간, K=1000개의 임의 행 | 5.8ms | 144ms | 25배 빨라짐 |
| 전체 벡터 열 스캔 | 21ms | 142ms | 6.76배 빨라짐 |
| 파일 크기, ~21MB 원시 데이터 | 6.62 MB | 7.16 MB | 7% 더 작아짐 |
take 결과는 읽고 디코딩해야 하는 관련 없는 데이터의 양을 줄임으로써 얻을 수 있습니다. 스캔 결과는 압축 및 구현 선택에 따라 달라집니다.
이 수치는 설정에 그대로 유지해야 합니다: 8개의 vCPU 우분투 22.04 KVM, 로컬 파일 시스템, 하나의 파일, 40,000개의 행, 1MB 행 그룹, 그리고 위의 스키마. 오브젝트 스토리지에서는 네트워크 I/O가 압도적일 수 있으므로 읽기 증폭을 줄이는 것이 훨씬 더 중요할 수 있습니다. 실제 결과는 데이터 세트 형태, 객체 저장소 동작, 캐시 상태 및 쿼리 패턴에 따라 달라집니다.
요점은 모든 열이 Vortex를 사용해야 한다는 것이 아닙니다.
요점은 벡터 데이터 세트는 ColumnGroup 수준에서 파일 형식을 선택해야 한다는 것입니다.
설계 2: 행 ID를 통해 실제 파일 정렬
하이브리드 파일 형식은 한 가지 문제를 해결합니다. 이제 서로 다른 열을 가장 적합한 형식으로 저장할 수 있습니다.
하지만 이는 두 번째 문제를 야기합니다. 스칼라 필드는 Parquet에, 벡터는 Vortex에, 원시 객체는 객체 스토리지에 저장되어 있는 경우, 시스템에서 이를 어떻게 하나의 컬렉션으로 취급할 수 있을까요?
Loon은 행 ID 정렬을 통해 이 문제를 해결합니다.
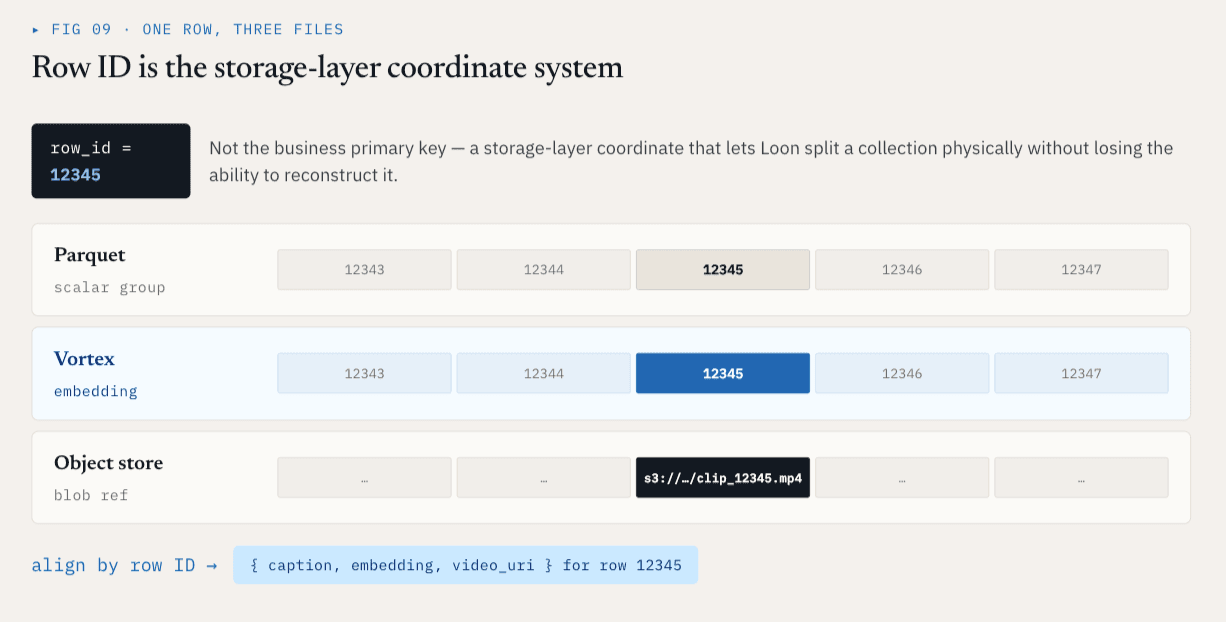
행 ID는 스토리지 레이어 좌표계입니다.
각각의 물리적 ColumnGroupFile은 파일 경로와 해당 파일에 포함된 행 ID 범위를 기록합니다:
path
start_index
end_index
서로 다른 컬럼그룹이 서로 다른 파일과 형식에 존재하더라도 동일한 행 ID 공간을 커버할 수 있습니다.
행 ID 12345 의 경우, 스칼라 메타데이터는 Parquet ColumnGroup에, 임베딩은 Vortex ColumnGroup에, 원본 비디오는 오브젝트 스토리지 참조로 표현될 수 있습니다. 논리적으로는 여전히 하나의 행입니다. 이렇게 하면 스토리지 계층에 안정적인 좌표계가 제공됩니다.
행 ID는 비즈니스 기본 키가 아닙니다. 이는 Loon이 논리적으로 재구성하는 기능을 잃지 않고 물리적으로 컬렉션을 분할할 수 있게 해주는 스토리지 레이어 좌표계입니다.
새 열은 이전 열을 다시 작성할 필요가 없습니다.
embedding_v2 을 추가해도 원래 캡션, 메타데이터 또는 embedding_v1 ColumnGroups을 다시 작성할 필요가 없습니다. Loon은 새로운 벡터 ColumnGroup을 작성하고, 해당 행 ID 범위를 기록하고, 매니페스트를 통해 해당 변경 사항을 커밋할 수 있습니다.
나중에 도착하는 스파스 벡터, 재랭크 기능 또는 기타 파생된 필드에도 동일하게 적용됩니다.
새 ColumnGroup이 올바른 행 ID 범위를 포함하는 한, 관련 없는 데이터를 강제로 이동시키지 않고도 동일한 논리적 컬렉션에 조인할 수 있습니다.
삭제 및 압축을 보다 구체적으로 지정할 수 있습니다.
행 ID 정렬은 삭제에도 도움이 됩니다.
삭제는 먼저 삭제 로그를 통해 표현할 수 있습니다. 행은 논리적 수준에서 보이지 않게 되고, 물리적 정리는 압축이 실행될 때까지 지연됩니다. 결국 압축이 실행되면 영향을 받는 행에 연결된 모든 ColumnGroup을 항상 다시 작성할 필요는 없습니다. 정리가 필요한 컬럼그룹에 집중할 수 있습니다.
이는 모든 열의 비용 프로필이 동일하지 않기 때문에 중요합니다. 짧은 스칼라 ColumnGroup을 다시 작성하는 것은 수백 기가바이트의 고밀도 벡터를 다시 작성하는 것과는 매우 다릅니다.
하이브리드 검색은 필요한 열만 가져올 수 있습니다.
행 ID 정렬은 하이브리드 파일 형식에서 하이브리드 검색을 실용적으로 만드는 요소이기도 합니다.
ANN 검색이 후보 행 ID를 반환한 후, 시스템은 캡션, 메타데이터, 벡터, 재순위 기능 또는 개체 참조 등 최종 결과에 필요한 필드만 가져올 수 있습니다.
예를 들어 쿼리가 필요할 수 있습니다:
caption
embedding
video_uri
이러한 필드는 서로 다른 ColumnGroups에 존재할 수 있습니다. Loon은 행 ID 범위로 관련 파일을 찾고, 필요한 바이트 범위를 읽어 결과를 조합할 수 있습니다.
행 ID 정렬이 없다면 하이브리드 형식은 나란히 놓인 별도의 파일일 뿐입니다. 행 ID 정렬을 사용하면 하나의 논리적 컬렉션처럼 작동합니다.
패킹된 리더는 상위 계층에서 분할을 숨깁니다.
이를 사용할 수 있게 해주는 런타임 컴포넌트가 바로 패킹된 리더입니다.
상위 계층에서는 통합된 Arrow RecordBatch 스트림을 볼 수 있습니다. 그 아래에는 서로 다른 파일 형식의 여러 ColumnGroup에서 데이터가 들어올 수 있습니다. Packed Reader는 이러한 차이를 숨기고, 행 ID 범위별로 데이터를 정렬하며, 제어된 메모리 사용량으로 다중 파일 I/O를 예약합니다.
또한 행 ID로 직접 take 을 지원합니다. 행 ID 집합이 주어지면 관련 ColumnGroupFiles를 찾고, 범위 읽기를 실행하고, 요청된 필드를 반환합니다.
비디오 워크플로우의 경우, ANN 쿼리에는 caption, embedding, video_uri 이 필요할 수 있습니다. Packed Reader는 관련 없는 열을 건드리지 않고 스칼라 ColumnGroup과 벡터 ColumnGroup을 가져올 수 있습니다.
이것이 "별도의 파일"과 "여러 물리적 레이아웃이 있는 테이블"의 차이점입니다.
디자인 3: 매니페스트를 진실의 원천으로 만들기
하이브리드 파일 형식은 데이터가 물리적으로 저장되는 방식을 정의합니다. 행 ID 정렬은 분리된 열 그룹이 여전히 하나의 논리적 테이블을 형성하는 방법을 결정합니다. 하지만 시스템은 여전히 어떤 파일, 로그, 통계, 인덱스 및 개체 참조가 현재 버전의 데이터 집합에 속하는가라는 더 큰 질문에 답해야 합니다. 이것이 바로 매니페스트의 역할입니다.

오브젝트 저장소 디렉터리로는 충분하지 않습니다.
오브젝트 저장소는 데이터베이스 카탈로그가 아닙니다. 디렉터리에는 오래된 파일, 새 파일, 실패한 작업 결과물, 임시 파일, 삭제 로그, 이전 스냅샷에서 여전히 참조하는 파일, 정리를 기다리는 파일 등이 포함될 수 있습니다. 파일이 존재한다고 해서 그 파일이 현재 데이터 세트 버전에 속한다는 의미는 아닙니다.
Loon 데이터 세트는 다음과 같은 디렉터리로 구성될 수 있습니다:
_metadata/
_data/
_delta/
_stats/
_index/
그러나 디렉토리 구조가 진실의 원천은 아닙니다. 매니페스트가 진실의 원천입니다. 독자는 디렉터리를 나열하고 존재하는 파일로부터 상태를 유추해서는 안 됩니다. 현재 매니페스트를 읽고 선언된 버전 보기를 따라야 합니다.
매니페스트는 데이터 집합의 버전이 지정된 하나의 보기를 정의합니다.
매니페스트는 데이터 집합을 특정 버전으로 정의합니다. 그것은 기록합니다:
- 어떤 열 그룹이 존재하는지
- 어떤 행 ID 범위가 포함되는지
- 각 ColumnGroup이 사용하는 물리적 형식
- 파일이 있는 위치
- 어떤 삭제 로그가 활성화되어 있는지
- 사용 가능한 통계
- 어떤 인덱스가 존재하는지
- 어떤 외부 블롭이 참조되는지
- 해당 통계 또는 인덱스가 다루는 열 및 행 범위
각 업데이트는 새로운 매니페스트 버전을 작성합니다. 버전 N을 여는 독자는 버전 N에서 데이터 집합의 안정적인 보기를 볼 수 있습니다. 작성자는 버전 N을 계속 사용하고 있는 독자를 방해하지 않고 버전 N+1을 준비할 수 있습니다.
매니페스트는 테이블 파일 이상의 것을 추적합니다.
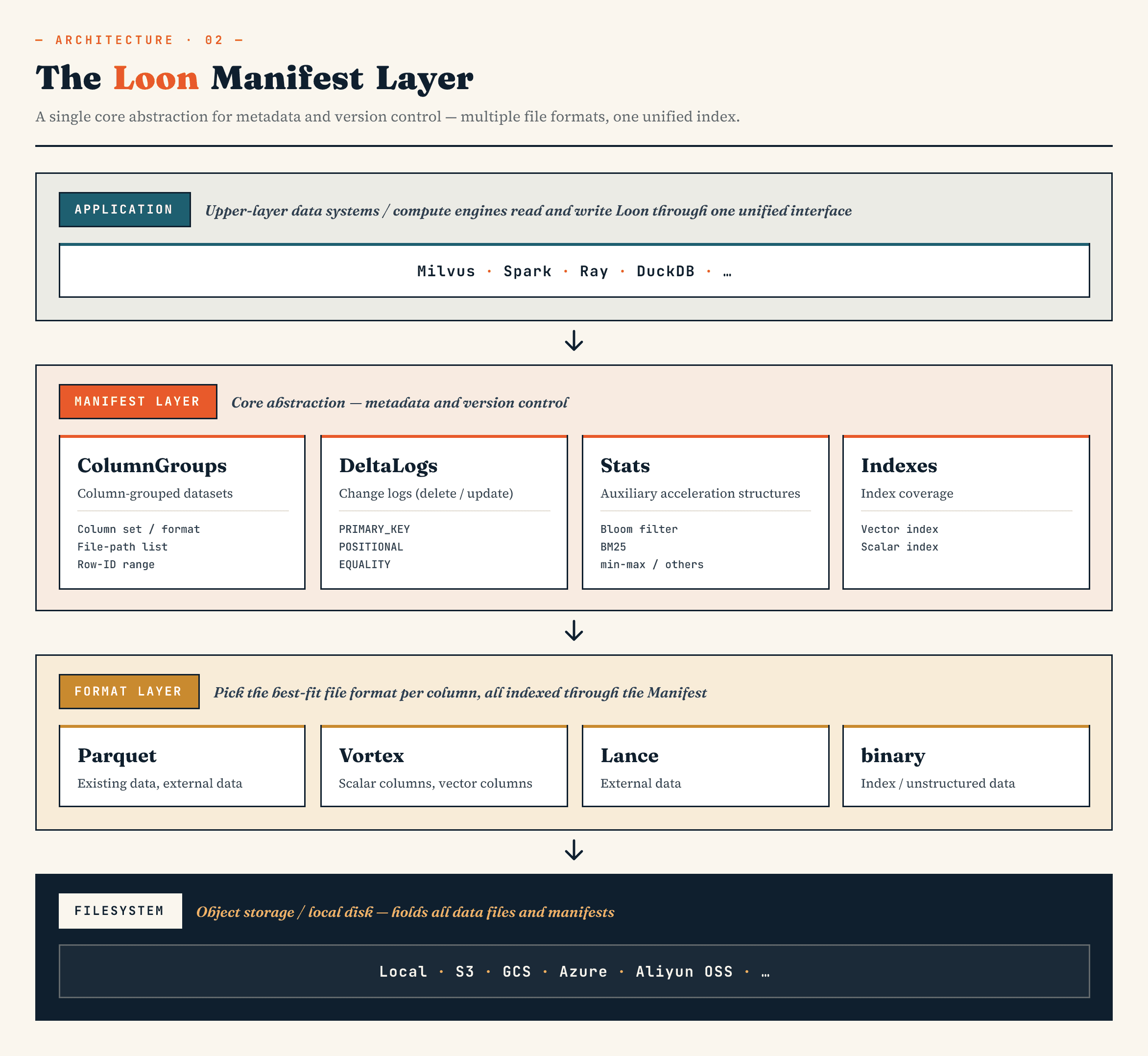
Loon에서 매니페스트 본문은 Apache Avro로 인코딩되며 네 가지 주요 섹션으로 구성됩니다.
- ColumnGroups는 열, 형식, 파일, 행 ID 범위를 설명합니다.
- 델타로그는 삭제를 설명합니다. 삭제 유형에 따라 클라이언트의 기본 키 삭제, 내부 압축의 위치 삭제, 외부 엔진의 동일성 삭제 등 다양한 변경 소스를 다룹니다.
- 통계에는 블룸 필터, BM25 통계, 최소/최대 값과 같은 계획 메타데이터가 포함됩니다.
- 인덱스는 인덱스 유형, 매개변수, 대상 열 및 행 ID 범위를 설명합니다. 여기에는 HNSW 또는 IVF와 같은 벡터 인덱스, 텍스트 인덱스, 반전 인덱스, 비트맵 인덱스 및 관련 구조가 포함될 수 있습니다.
이 점이 Loon이 기존의 테이블 매니페스트와 다른 점입니다.
벡터 데이터 세트는 데이터 파일과 파티션만 추적해야 하는 것이 아닙니다. 또한 벡터 인덱스, 텍스트 인덱스, 스파스 피처, 삭제 로그, 통계, 외부 개체 참조, 그리고 이들을 연결하는 행 ID 범위도 추적해야 합니다.
매니페스트는 데이터베이스 이상의 사용자가 쓸 수 있어야 합니다.
가장 중요한 부분은 매니페스트에 포함된 내용뿐만이 아닙니다. 누가 작성할 수 있는가입니다.
- 데이터베이스만 매니페스트를 쓸 수 있으면 내부 메타데이터로 남게 됩니다. 메타데이터는 더 깔끔해지지만 여전히 하나의 엔진에만 비공개로 남습니다.
- 외부 엔진이 새로운 ColumnGroups, 통계, 매니페스트 항목을 생성할 수 있는 경우, 매니페스트는 조정 인터페이스가 됩니다.
- 예를 들어 Spark 작업은 희소 벡터 열을 다시 채울 수 있습니다. 이 작업은 새 ColumnGroup을 작성하고, 행 범위와 통계를 기록하고, 새 Manifest를 커밋합니다. 온라인 쿼리는 작업 중에 이전 버전을 계속 읽을 수 있습니다. 커밋이 성공하면 새 버전이 표시됩니다.
이것은 빙산 및 델타 레이크와 비슷한 정신이지만 객체 모델이 더 광범위합니다. 벡터 데이터 세트는 테이블 파일과 파티션뿐만 아니라 벡터 인덱스, 텍스트 인덱스, 스파스 피처, 삭제 로그, 통계, 블롭 참조 및 행 ID 범위도 추적해야 합니다.
버전 업데이트를 단순하게 유지하는 낙관적 커밋
각 커밋은 새로운 매니페스트 버전을 작성합니다. 작성자는 버전 N을 기반으로 새 콘텐츠를 빌드한 다음 manifest-{N+1}.avro 에 쓰기를 시도할 수 있습니다. 오브젝트 저장소 조건부 쓰기 또는 생성 일치 의미론은 해당 버전이 이미 존재하는 경우 커밋을 실패하게 만들 수 있습니다. 그러면 작성자는 최신 버전에 대해 다시 시도할 수 있습니다.
이렇게 하면 모든 업데이트를 강력하고 일관성 있는 조정 경로를 통해 강제하지 않고도 Loon의 동시성을 최적화할 수 있습니다. 매니페스트가 없으면, 다중 형식과 다중 엔진 스토리지는 결국 명명 규칙과 수동 조정으로 바뀝니다. 이는 소규모 데이터 세트에서는 효과가 있을 수 있습니다. TB 규모의 벡터 데이터에는 작동하지 않습니다.
매니페스트는 이기종 파일을 여러 시스템에서 안전하게 읽고 업데이트할 수 있는 데이터 집합으로 바꿔줍니다.
스토리지에 버전이 지정되면 사용자에게 어떤 변화가 있나요?
애플리케이션 개발자에게는 Loon이 새로운 API의 부담이 되어서는 안 됩니다.
사용자들은 여전히 컬렉션, 삽입, 검색, 하이브리드 검색 등 익숙한 Milvus의 개념으로 작업해야 합니다. 일반적인 애플리케이션 개발 중에 매니페스트 파일, ColumnGroups, 행 ID 범위 또는 파일 레이아웃에 대해 생각할 필요가 없어야 합니다.
변화는 바로 그 아래에 있습니다. 스토리지가 AI 데이터 세트가 실제로 어떻게 진화하는지를 더 잘 인식하게 됩니다.
새 임베딩을 추가해도 기존 데이터가 이동하지 않아야 합니다.
이전에는 기존 컬렉션에 embedding_v2 을 추가하려면 데이터를 내보내고, 새 모델을 학습시키고, 벡터를 생성한 다음, SDK를 통해 컬렉션을 다시 가져오거나 대량 업데이트해야 하는 경우가 많았습니다. 이 경로에서는 버전 추적, 작업 재시도 실패, 인덱스 재구축, 서비스 영향, 일관성 검사 등 많은 운영 작업이 발생하게 됩니다.
Loon을 사용하면 스키마 진화와 새로운 ColumnGroup 커밋이 추가될 수 있습니다. 새로운 임베딩 컬럼은 자체적인 물리적 ColumnGroup으로 작성되고, 행 ID로 정렬되며, 매니페스트를 통해 표시될 수 있습니다. 이전 캡션 열, 스칼라 메타데이터 열 및 원래 임베딩 열은 이동할 필요가 없습니다.
백필에는 클라이언트 측 업데이트 루프가 필요하지 않아야 합니다.
많은 AI 데이터 업데이트는 백필입니다. 하이브리드 검색이 중요해진 후에 스파스 벡터를 추가할 수 있습니다. 새 모델이 학습된 후 재순위 기능을 추가할 수도 있습니다. 사람이 검토한 후 캡션을 수정할 수 있습니다. 정책 업데이트 후 거버넌스 태그를 추가할 수 있습니다.
기존 레이아웃에서는 데이터가 Spark, Ray 또는 다른 외부 엔진에서 생성된 경우에도 클라이언트 SDK 업데이트나 데이터베이스 전용 쓰기 경로를 통해 이러한 변경이 발생하는 경우가 많습니다.
Loon을 사용하면 외부 컴퓨팅 시스템에서 새로운 ColumnGroup을 생성하고 매니페스트를 통해 커밋할 수 있습니다. 더 이상 데이터베이스가 모든 재작성을 위한 유일한 진입점이 될 필요는 없습니다.
오프라인 분석에 또 다른 사본이 필요하지 않아야 합니다.
이전에는 팀에서 오프라인 평가나 분석을 위해 온라인 컬렉션을 Parquet에 덤프하는 경우가 많았습니다. 이렇게 하면 동일한 데이터 집합의 두 가지 버전, 즉 온라인 컬렉션과 분석 사본이 만들어집니다. 캡션이 수정되거나, 임베딩이 다시 생성되거나, 삭제 로그가 적용되거나, 인덱스가 다시 구축되면 팀은 어떤 사본이 최신 버전인지 물어봐야 했습니다.
매니페스트 기반 저장소 모델을 사용하면 분석 엔진은 서비스 시스템과 동일한 버전의 데이터 세트 보기를 읽을 수 있습니다. 필요한 열만 투영하고, 관련 행 범위만 스캔하고, 수동으로 내보낸 스냅샷 대신 선언된 데이터 세트 버전에 대해 작업할 수 있습니다.
삭제 및 수정은 변경된 항목만 건드려야 합니다.
삭제, 캡션 수정, 레이블 수정 및 거버넌스 업데이트는 AI 데이터 세트에서 일상적인 작업입니다. 모든 긴 벡터 열을 동일한 재작성 경로를 통해 강제로 재작성해서는 안 됩니다.
Loon에서는 로그 삭제를 먼저 논리적 삭제로 처리할 수 있습니다. 나중에 압축을 하면 관련 없는 데이터를 다시 쓰지 않고도 영향을 받는 ColumnGroups를 정리할 수 있습니다. 짧은 텍스트 필드가 변경되는 경우, 동일한 논리적 행을 공유한다고 해서 스토리지 계층에서 수백 기가바이트의 고밀도 벡터를 다시 작성할 필요는 없습니다.
외부 엔진은 탈출구가 아닌 워크플로우의 일부가 됩니다.
더 큰 변화는 외부 엔진이 더 이상 벡터 데이터베이스 외부의 시스템으로 취급되지 않는다는 것입니다.
Spark, Ray, 평가 작업, 라벨링 시스템, 거버넌스 파이프라인은 이미 많은 데이터를 생성하고 수정하고 있습니다. 스토리지 계층은 이들이 끊임없이 내보내기, 복사, 다시 가져오기를 반복하는 대신 단일 소스를 중심으로 협업할 수 있도록 지원해야 합니다.
이것이 바로 매니페스트 버전이 가능하게 하는 것입니다. 온라인 서비스, 오프라인 분석, 백필 작업, 압축 작업에서 데이터 세트에 대한 공유 보기를 제공합니다.
이러한 기능은 내부 저장소 세부 정보처럼 들릴 수 있지만, 팀이 AI 데이터 세트를 얼마나 빠르게 반복할 수 있는지에 영향을 미칩니다. 모든 모델 변경, 기능 백필, 캡션 수정, 품질 필터 및 인덱스 재구축은 "시스템이 이동할 필요가 없는 데이터를 이동하지 않고 데이터 세트를 업데이트할 수 있는가?"라는 동일한 질문에 따라 달라집니다.
이것이 바로 스토리지 모델의 실질적인 가치입니다.
Loon은 Milvus 3.0 베타 및 Zilliz Vector Lakebase에서 사용할 수 있습니다.
Loon은 Milvus 3.0 베타 버전에서 사용할 수 있으며, 질리즈 클라우드의 차세대 버전인 질리즈 벡터 레이크베이스의 스토리지 계층의 일부이기도 합니다. 이번 릴리스는 세 가지 핵심 영역에 중점을 두고 있습니다:
- 매니페스트. 쓰기, 다시 채우기, 삭제, 통계 및 인덱스 업데이트가 독자가 일관되게 열 수 있는 버전화된 데이터 세트 보기를 생성하는 것이 목표입니다. 독자의 경우, 이는 쿼리가 특정 매니페스트 버전을 열고 데이터 세트의 안정적인 보기를 볼 수 있다는 것을 의미합니다. 작성자의 경우, 이는 새 데이터 파일, 삭제 로그, 통계 또는 인덱스 파일을 먼저 준비한 다음 버전이 지정된 커밋을 통해 볼 수 있다는 것을 의미합니다.
- ColumnGroup 및 형식 지원. Parquet은 스칼라 및 에코시스템 친화적인 열을 지원합니다. Vortex는 벡터 중심의 액세스 패턴을 지원합니다. Lance는 읽기 전용 모드로 통합되어 기존 Lance 데이터 세트와의 호환성을 유지할 수 있습니다.
- Lake의 인덱스. 스칼라 통계, 필터링 인덱스, 텍스트 반전 인덱스는 행 범위별로 매니페스트 기반 계획에 참여할 수 있습니다. 레이크 네이티브 벡터 인덱스는 더 많이 관여합니다. HNSW와 IVF는 객체 스토리지에 대한 동작이 다르며, 특히 HNSW는 랜덤 액세스 및 캐시 위치에 민감합니다. 단순히 로컬 SSD용으로 설계된 레이아웃을 재사용하고 동일한 결과를 기대할 수는 없습니다.
아직 해결해야 할 과제
- 외부 쓰기 경로는 Spark와 Ray가 클라이언트 SDK 루프를 통해 모든 백필을 강제하지 않고도 ColumnGroups 및 Manifest 커밋을 생성할 수 있어야 하기 때문에 중요합니다.
- 많은 팀에서 이미 Iceberg, Delta Lake, Trino, DuckDB, Athena 등의 카탈로그와 쿼리 엔진을 사용하고 있기 때문에Lakehouse 상호 운용성이 중요합니다 . 벡터 데이터는 벡터 검색 성능의 저하 없이 이러한 에코시스템에 참여할 수 있어야 합니다.
- 그래프 인덱스와 반전 구조는 객체 스토리지에서 서로 다른 액세스 패턴을 갖기 때문에인덱스 레이아웃이 중요합니다.
- 원시 비디오, PDF, 이미지, 오디오 파일은 파생된 벡터 데이터 세트와 일치하는 참조 관리, 버전 관리, 삭제 동작이 필요하기 때문에대용량 객체 의미론이 중요합니다.
정확한 릴리스 동작, 기본 설정, 마이그레이션 경로는 관련 Milvus 및 Zilliz Cloud 릴리스 노트를 따라야 합니다. 그러나 스토리지 방향은 분명합니다. 벡터 데이터베이스는 서비스 레이어 아래에 버전이 관리되는 레이크 네이티브 기반이 필요합니다.
질리즈 벡터 레이크베이스에서 Loon 사용해보기
현재 스택이 온라인 서빙, 오프라인 분석, 백필, 외부 데이터 레이크 워크플로우를 서로 다른 시스템으로 분리하고 있다면, Zilliz Vector Lakebase를 고려해 볼 가치가 있습니다. 질리즈 클라우드에서 체험해 볼 수 있습니다. 신규 업무용 이메일 가입자에게는 $100 무료 크레딧이 제공됩니다. 사용 사례에 대해 문의하실 수도 있습니다.
Milvus 3.0 릴리스를 팔로우하여 오픈 소스 엔진에서 Loon이 어떻게 발전하는지 확인할 수도 있습니다.
질리즈 벡터 레이크베이스가 함께합니다:
- 다양한 실시간 성능과 비용 절충을 위한 계층화된 서비스 제공
- 상시 가동 컴퓨팅 없이 대규모 또는 탐색적 워크로드를 위한 온디맨드 검색
- 외부 데이터 레이크 검색을 통해 기존 레이크 데이터를 직접 색인하고 검색할 수 있습니다.
- 하이브리드 검색 및 순위 재지정을 통해 벡터, 텍스트, JSON, 위치 기반 데이터 전반에 걸친 전체 스펙트럼 검색 가능
- 벡터가 많은 데이터에 대해 더 빠르고 저렴한 비용으로 무작위 읽기를 할 수 있도록 설계된 개방형 포맷인 Vortex에 구축된 통합 레이크 네이티브 스토리지
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word



