Perché abbiamo costruito Loon: un motore di archiviazione per i dati di intelligenza artificiale che non smettono di cambiare.
Questo blog è stato pubblicato originariamente su zilliz.com ed è stato ripubblicato con autorizzazione.
Punti chiave
Questa è un'immersione ingegneristica lunga e approfondita, quindi ecco i punti chiave prima di entrare nei dettagli.
- I dataset di intelligenza artificiale non sono tabelle statiche. Le stesse righe cambiano continuamente quando i team sostituiscono i modelli di incorporazione, aggiungono vettori sparsi, rivedono le didascalie, riempiono le etichette, ricostruiscono gli indici ed eseguono analisi offline.
- I layout di archiviazione tradizionali si rompono in tre modi: le lunghe colonne vettoriali rendono costosi i backfill, un unico formato di file non può servire bene sia le scansioni che le letture puntuali e l'archiviazione in database privati costringe le pipeline esterne a creare copie extra della verità.
- Loon è il nuovo motore di archiviazione per Milvus e Zilliz Vector Lakebase. Si basa su formati di file ibridi, sull'allineamento degli ID delle righe e su un Manifest che definisce lo stato di versione del set di dati.
- L'obiettivo è quello di consentire a un singolo set di dati vettoriali di supportare la ricerca online, l'analisi offline, i backfill, la compattazione e il calcolo esterno senza dover continuamente copiare, riscrivere o reimportare i dati.
Introduzione
Per un certo periodo, c'è stato un argomento ragionevole contro i database vettoriali.
I database tradizionali memorizzano già numeri interi, stringhe, JSON, blob e indici. Perché non aggiungere un tipo _vector_ , costruire un indice ANN accanto ad esso e chiudere la questione?
Per la ricerca semantica iniziale, questa soluzione funziona abbastanza bene. Una colonna vettoriale e un indice possono supportare una demo, una piccola applicazione RAG o una funzione di ricerca interna. Il problema si presenta più tardi, quando il dataset inizia a comportarsi meno come una tabella e più come un sistema di dati AI.
Un dataset vettoriale di produzione ha righe, chiavi primarie, campi scalari e colonne interrogabili. In questo senso, assomiglia a una tabella di database. Ma ha anche la scala e la forma del flusso di lavoro di un lago di dati. Può contenere centinaia di milioni di record. Viene letto e riscritto ripetutamente da Spark, Ray, DuckDB, pipeline di formazione, lavori di valutazione e sistemi di qualità dei dati.
Dipende anche dallo storage di oggetti. Gli oggetti di origine sono spesso video, immagini, PDF, file audio o documenti web che rimangono in S3, GCS, OSS o in un altro archivio di oggetti. Il database memorizza riferimenti, metadati, caratteristiche derivate e indici. Poi aggiunge cose che i modelli di archiviazione tradizionali non sono stati costruiti per gestire come oggetti di prima classe: embeddings densi, vettori sparsi, didascalie, indici vettoriali, indici di testo, registri di cancellazione, statistiche, versioni del modello, versioni del parser, riferimenti a blob esterni e le relazioni di versione tra tutti questi elementi.
È qui che l'idea di "aggiungere semplicemente una colonna vettoriale" comincia a non funzionare. Il problema non è se un database può memorizzare byte vettoriali. Molti sistemi possono farlo. La domanda più difficile è se il modello di archiviazione sia in grado di gestire le modifiche dei dati vettoriali, le interrogazioni e la loro condivisione nello stack di dati dell'intelligenza artificiale.
Ecco perché abbiamo costruito Loon, il nuovo motore di storage per Milvus e Zilliz Vector Lakebase (la prossima evoluzione di Zilliz Cloud).
Loon è stato progettato con tre idee:
- Utilizzare diversi formati fisici per diversi tipi di colonne.
- Allineare queste colonne attraverso uno spazio ID di riga condiviso.
- Utilizzare un Manifest per definire lo stato di versione del dataset.
Per capire perché questi elementi sono importanti, iniziamo con un comune flusso di lavoro multimodale.
Un set di dati vettoriali non è mai veramente finito.
Immaginiamo un team di AI che costruisce un set di dati video per l'addestramento multimodale.
Un lungo video viene caricato sullo storage a oggetti. Una pipeline lo taglia in clip in base ai cambi di scena, ai confini dell'inquadratura o alle finestre temporali. Le clip troppo lunghe o troppo corte, sfocate, duplicate o di bassa qualità vengono filtrate. I clip rimanenti vengono valutati da un modello estetico, sottotitolati da un altro modello, incorporati da un modello di linguaggio visivo e archiviati in un database vettoriale per la ricerca, la deduplicazione e il filtraggio dei dati di addestramento.
Ad alto livello, il flusso di lavoro sembra semplice:
video
→ clips
→ metadata
→ aesthetic_score
→ caption
→ embedding
→ search / dedup / training data filtering
Ma il set di dati non arriva completamente formato.
- Nella prima settimana, la tabella può contenere solo
clip_id,video_id,start_offseteduration. - Nella seconda settimana, il team aggiunge
aesthetic_score. - Nella terza settimana, viene eseguito un modello di didascalia e ogni clip riceve un
caption. - Nella quarta settimana, il primo modello di embedding viene messo online e ogni clip riceve un embedding CLIP a 768 dimensioni.
- Un mese dopo, il team cambia modello e riempie nuovamente
embedding_v2, ora con 1024 dimensioni. - Due mesi dopo, la ricerca ibrida diventa un requisito, quindi il team aggiunge una colonna vettoriale rada.
- Tre mesi dopo, le didascalie sono sottoposte a revisione umana e devono essere corrette sul posto.
Il set di dati non è mai stato completato. Continuava ad accumulare nuove interpretazioni delle stesse righe sottostanti.
Questa è una delle differenze fondamentali tra i dati vettoriali e i dati aziendali tradizionali. La stessa riga viene rielaborata più volte. E la scala trasforma questo inconveniente in un problema di archiviazione: i set di dati multimodali spesso non sono milioni di record, ma centinaia di milioni o miliardi. LAION-5B è un utile riferimento per la forma: miliardi di coppie immagine-testo, ciascuna con metadati, didascalie e incorporazioni. Quindi la parte difficile non è il primo inserimento. La parte difficile è tutto ciò che accade dopo che l'insieme di dati inizia a evolversi. L'evoluzione espone tre problemi.
Il primo problema: le colonne lunghe rendono costosa l'amplificazione della scrittura.
I formati colonnari come Parquet sono eccellenti per molti carichi di lavoro analitici. Funzionano bene quando gli schemi sono abbastanza stabili, i dati vengono letti più spesso che riscritti, le scansioni riguardano solo un sottoinsieme di colonne e la compressione è importante. Questo è il mondo per cui molti formati analitici sono stati ottimizzati.
Le righe vettoriali sono molto più larghe di quelle analitiche
TPC-H lineitem è una buona base di riferimento. Ha 16 colonne: chiavi intere, valori decimali, date, stringhe brevi e un piccolo campo di commento. Una riga non compressa è di circa 150 byte. Dopo la compressione, può essere molto più piccola. Con un gruppo di righe da 64 MB, un sistema di archiviazione può contenere centinaia di migliaia di righe in un unico gruppo.
I set di dati vettoriali non hanno questo aspetto.
Un set di dati immagine-testo in stile LAION è molto più vicino a ciò che molte pipeline di IA producono oggi. Ogni riga ha ancora i normali metadati: un URL, una didascalia, larghezza, altezza, punteggi di qualità, etichette e così via. Ma una volta aggiunto l'embedding, la forma fisica della riga cambia.
Un vettore CLIP a 768 dimensioni occupa circa 1,5 KB in fp16 o 3 KB in fp32. Una sola colonna può essere molto più grande di un'intera riga di TPC-H lineitem.
E 768 dimensioni non sono insolite o grandi per gli standard odierni. Un embedding a 1024 o 2048 dimensioni è comune nelle pipeline multimodali. text-embedding-3-large di OpenAI arriva a 3072 dimensioni, pari a circa 12 KB per vettore in fp32.
Il confronto è netto:
| Forma del set di dati | Dimensione approssimativa delle righe | Cosa domina la riga |
|---|---|---|
| TPC-H lineitem | ~150 byte non compressi | campi scalari e stringhe brevi |
| Riga in stile LAION con vettore fp16 di 768 dimensioni | ~1,5 KB+ | incorporazione |
| Riga in stile LAION con vettore fp32 a 768 dimensioni | ~3 KB+ | incorporazione |
| Riga con vettore fp32 a 3072-dim | ~12 KB+ per il solo vettore | incorporazione |
In molti set di dati AI, la colonna del vettore non è solo un altro campo. Fisicamente, è la maggior parte della riga. Questo cambia il costo dell'evoluzione dello schema.
L'aggiunta di una colonna vettoriale può significare centinaia di gigabyte.
Supponiamo che un set di dati contenga 100 milioni di videoclip. Aggiungere una nuova colonna di incorporazione fp32 a 1024 dimensioni significa scrivere circa 400 GB di dati vettoriali grezzi. Questo dato non include le statistiche, gli indici, gli aggiornamenti dei metadati, l'overhead dello storage degli oggetti, la validazione o l'integrazione del percorso di servizio.

Se il team aggiunge ogni mese una o due colonne di tipo vettoriale, come le funzioni embedding_v2, sparse_vector o rerank, l'evoluzione dello schema diventa un lavoro di ingegneria daAta ricorrente, misurato in centinaia di gigabyte o terabyte.
Piccoli aggiornamenti logici possono innescare grandi riscritture fisiche
Gli aggiornamenti sono altrettanto importanti.
Nei sistemi colonnari, i vecchi dati di solito non vengono aggiornati sul posto. Un registro di cancellazione registra ciò che è cambiato e la compattazione riscrive successivamente le righe vive in nuovi file. Questo modello è gestibile quando le righe sono piccole.
Con i dati vettoriali, un piccolo aggiornamento logico può innescare una grande riscrittura fisica.
Un lavoro di revisione umano può correggere solo poche centinaia di byte in una didascalia. Ma se la didascalia, il vettore denso, il vettore rado e altre caratteristiche derivate condividono lo stesso ciclo di vita del file fisico, il sistema può finire per riscrivere anche i vettori. Il cambiamento logico è piccolo. L'I/O fisico può essere enorme.
Questo è il problema dell'amplificazione della scrittura nell'archiviazione vettoriale. La parte costosa non è solo che i vettori sono grandi. È che i campi derivati di grandi dimensioni e i campi mutabili di piccole dimensioni sono spesso legati insieme da un layout di archiviazione che li tratta come un'unica unità.
Per i dataset di intelligenza artificiale, il backfill è un carico di lavoro di routine.
Per le tabelle analitiche tradizionali, l'evoluzione dello schema può avvenire solo occasionalmente. Per gli insiemi di dati di intelligenza artificiale, è un'operazione di routine. I modelli di didascalia vengono aggiornati. I modelli di incorporamento vengono sostituiti. Vettori sparsi vengono aggiunti successivamente. Appaiono caratteristiche di reranking. Le etichette umane vengono corrette. I tag di governance vengono riempiti. Gli indici vengono ricostruiti.
Queste operazioni non sono semplici aggiunte. Spesso modificano o estendono le righe esistenti.
Ecco perché lo storage vettoriale non può limitarsi a ottimizzare la velocità di scansione. Deve anche rendere più economici i backfill e gli aggiornamenti parziali.
Il secondo problema: gli stessi dati devono supportare scansioni e letture puntuali.
Dopo la scrittura dei dati, il percorso di lettura si divide. Lo stesso set di dati vettoriali ha in genere due modelli di accesso distinti: la scansione analitica e la lettura puntuale.
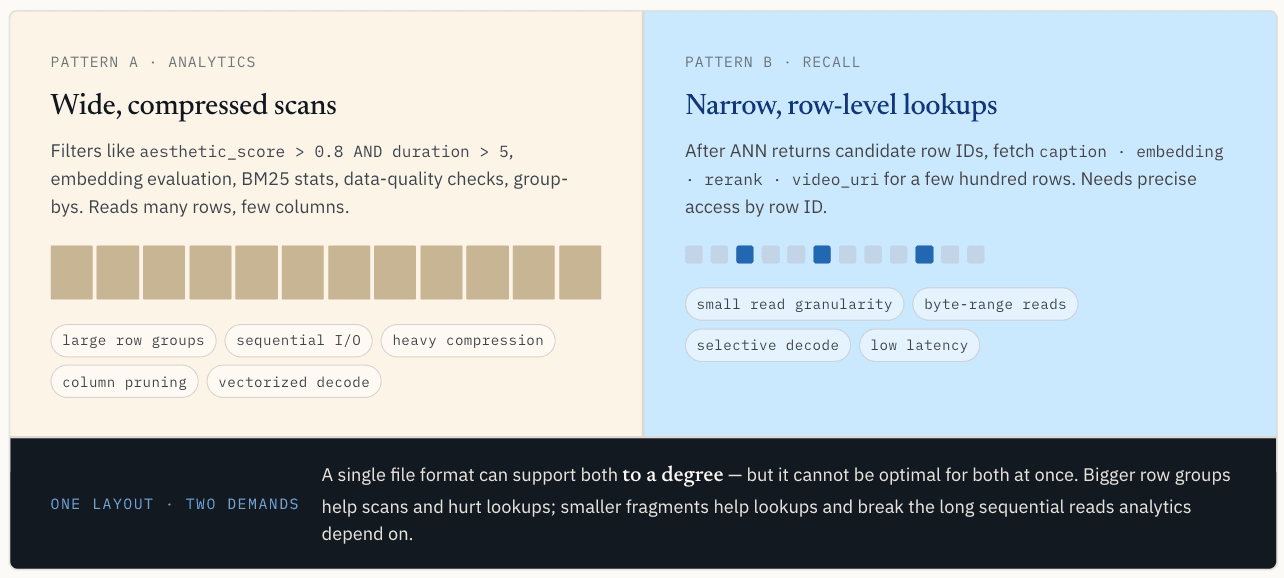
I carichi di lavoro analitici richiedono scansioni ampie e compresse.
Una pipeline può eseguire filtri come:
WHERE aesthetic_score > 0.8 AND duration > 5
Oppure può eseguire analisi offline, valutazione dell'incorporazione completa, statistiche BM25, costruzione di bitmap, controlli di qualità dei dati, conteggi e group-bys.
Questo schema legge molte righe ma solo poche colonne. Predilige l'I/O sequenziale, i gruppi di righe più grandi, la compressione, la riduzione delle colonne, la decodifica batch e l'esecuzione vettoriale.
I grandi gruppi di righe sono utili in questo caso. Permettono a una singola richiesta di I/O di prelevare una grande quantità di dati utili, migliorano l'efficienza della compressione e forniscono al motore di esecuzione una quantità di dati contigui sufficiente ad ammortizzare l'overhead. Quando più colonne vengono lette insieme, mantenerle organizzate per la velocità di scansione aiuta anche a ridurre le miss della cache durante l'esecuzione vettoriale.
Parquet è forte su questa strada.
I risultati di ANN necessitano di ricerche ristrette a livello di riga
Dopo che la ricerca ANN restituisce gli ID delle righe candidate, il sistema ha spesso bisogno di recuperare campi come:
caption
embedding
rerank feature
video_uri
metadata
Questo schema legge un numero inferiore di righe, spesso centinaia o migliaia, ma ha bisogno di un accesso preciso per ID di riga. Vuole individuare una riga e una colonna specifiche, recuperare solo l'intervallo di byte richiesto ed evitare di estrarre un intero gruppo di righe solo per recuperare alcuni record.
La ricerca per punti ha una preferenza quasi opposta rispetto alla scansione. Vuole una granularità di lettura più piccola. Idealmente, il livello di memorizzazione può trovare il segmento o l'intervallo di byte pertinente in base all'ID della riga, leggere solo quell'intervallo e decodificare solo i dati necessari per il risultato.
Anche la compressione ha un diverso compromesso. Per le scansioni, spesso vale la pena di utilizzare una compressione più pesante, perché il sistema legge molti dati e risparmia I/O. Per la ricerca di punti, la compressione può diventare un problema se il recupero di una riga richiede la decodifica di un blocco compresso molto più grande.
Un layout non può essere ottimizzato per entrambi i percorsi
Questo è il conflitto principale. Il filtraggio scalare e l'analisi vogliono layout ampi, compressi e facili da scansionare. La ricerca vettoriale vuole layout stretti, precisi e indirizzabili alle righe.
Un singolo formato di file può supportare entrambi in una certa misura, ma non può essere ottimale per entrambi contemporaneamente.
Se tutte le colonne vivono in Parquet, le scansioni scalari sono comode. Ma la ricerca di RNA dopo il richiamo diventa più difficile. Il sistema potrebbe aver bisogno solo di qualche centinaio di vettori, didascalie o record di metadati, mentre il livello di memorizzazione potrebbe dover leggere grandi gruppi di righe che contengono per lo più righe irrilevanti.
Su un'unità SSD locale, cache e mmap possono nascondere parte di questo costo. Una volta che i dati sono archiviati nello storage a oggetti, il costo diventa più visibile. Ogni miss della cache può diventare una lettura di un intervallo remoto. Se le righe candidate sono sparse in molti gruppi di righe, una singola query può innescare più letture, ognuna delle quali estrae più dati di quelli necessari alla query. In un layout mal strutturato, il recupero di 1.000 righe candidate può facilmente comportare decine o centinaia di megabyte di I/O non necessari e, in casi estremi, molto di più.
La riduzione dei gruppi di righe aiuta la ricerca dei punti, ma danneggia le scansioni. Troppi piccoli frammenti riducono l'efficienza della compressione, aumentano l'overhead dei metadati e interrompono le lunghe letture sequenziali da cui dipendono i motori analitici.
Il problema non è quindi trovare una singola dimensione magica per i gruppi di righe. Il problema è che allo stesso set di dati viene chiesto di comportarsi come due sistemi di archiviazione diversi.
La ricerca ibrida costringe entrambi i percorsi in un'unica query
La ricerca ibrida rende il conflitto più difficile da ignorare. Una singola query può prima applicare filtri scalari:
aesthetic_score > 0.8 AND duration > 5
Poi esegue la ricerca ANN.
Poi recupera didascalie, vettori e metadati per ID riga.
Per l'utente, questa è una richiesta di ricerca. Per il livello di archiviazione, si tratta di una scansione analitica e di una ricerca casuale a bassa latenza.
Ecco perché l'archiviazione vettoriale ha bisogno di qualcosa di più di una migliore impostazione di Parquet. Ha bisogno di un modo per posizionare le diverse colonne in base a come vengono effettivamente lette.
Il terzo problema: il set di dati non vive all'interno di un unico motore
I primi due problemi si verificano all'interno del database. Il terzo si verifica al confine tra i sistemi.

Le pipeline di dati dell'intelligenza artificiale si estendono su più sistemi
Nel flusso di lavoro dei video, molto poco avviene all'interno del database vettoriale.
I video grezzi vivono in un archivio di oggetti. La generazione di clip può essere eseguita in Spark o Ray. La valutazione estetica può essere eseguita in un servizio GPU. Le didascalie possono essere eseguite in una pipeline di inferenza LLM. Gli embeddings possono essere generati da un altro lavoro su GPU. I vettori sparsi possono provenire da un servizio SPLADE. La valutazione offline, il filtraggio dei dati di formazione, la revisione umana e i lavori di governance possono essere eseguiti altrove.
Il database dei vettori serve per la ricerca online, ma il set di dati viene prodotto, corretto, valutato ed esteso da molti sistemi.
I formati di archiviazione privati creano più copie della verità
Se il database utilizza un formato fisico privato che solo lui può leggere e scrivere, ogni lavoro esterno necessita di un'esportazione, una conversione, una copia e un'importazione. La stessa collezione può esistere nel database, in una directory temporanea di Spark, in un output di valutazione e in una directory di backfill locale. Allora la vera domanda diventa:
- Quale copia è la fonte della verità?
- Quale contiene il modello di didascalia del mese scorso?
- Quali righe sono già state corrette dalla revisione umana?
- Quale colonna vettoriale rada è stata generata da quale modello?
- Quale indice vettoriale è ancora valido dopo il backfill?
- A quale oggetto video originale si riferisce questa riga?
Su piccola scala, i team possono talvolta sopravvivere con convenzioni di denominazione e controlli manuali. Con centinaia di milioni di righe e terabyte di incorporazioni, questo diventa un problema di coerenza.
Gli insiemi di dati vettoriali hanno bisogno di uno stato versionato condiviso
I sistemi Lakehouse hanno affrontato una versione di questo problema per i dati strutturati. Iceberg, Delta Lake e Hudi non si limitano a memorizzare i file. Il loro contributo principale consiste nel permettere a più motori di coordinarsi intorno allo stesso stato della tabella.
I database vettoriali hanno bisogno di una capacità simile, ma lo stato è più complesso. Deve includere non solo i file delle tabelle e le partizioni, ma anche gli indici vettoriali, gli indici di testo, le caratteristiche sparse, i registri delle cancellazioni, le statistiche, gli intervalli di ID delle righe e i riferimenti a blob esterni.
La domanda non è semplicemente: "Spark può leggere i file Milvus?".
La domanda è: dopo che Spark riempie una colonna vettoriale rada, come fa Milvus a sapere a quale versione appartiene quella colonna, quali righe copre, quale modello l'ha prodotta e quando le query online possono usarla in modo sicuro?
La risposta deve risiedere nel modello di memorizzazione.
Perché le patch non sono sufficienti
Si è tentati di trattare questi problemi come tre problemi ingegneristici separati.
- Amplificazione della scrittura? Aggiungere il batching.
- Letture puntuali? Aggiungere una cache.
- Sistemi esterni? Aggiungere strumenti di esportazione e importazione.
Queste patch possono aiutare, ma non risolvono il problema di fondo: un set di dati vettoriali è fisicamente eterogeneo.

Nell'esempio del video, clip_id, video_id, duration e aesthetic_score sono campi scalari brevi. Sono utili per il filtraggio e l'analisi.
captionè un testo. Può essere usato per BM25, revisione, correzione e riempimento.embeddingè un vettore lungo e denso. Viene utilizzato per il richiamo della RNA e successivamente per il lookup o il reranking a livello di riga.embedding_v2è un nuovo output del modello, spesso riempito molto tempo dopo l'inserimento dei dati originali.sparse_vectorsupporta la ricerca ibrida e ha un proprio modello di accesso.- Il video grezzo deve rimanere nell'archivio oggetti. Il database deve memorizzare un riferimento, un checksum, un tipo MIME, una versione del parser e una relazione a livello di riga.
- Gli indici vettoriali, gli indici di testo, le statistiche e i registri delle cancellazioni sono oggetti derivati con una propria semantica di versione.
Questi oggetti condividono una riga logica, ma non dovrebbero condividere lo stesso layout fisico o lo stesso ciclo di vita.
- Se sono costretti in un layout di tabella ordinario, gli aggiornamenti diventano costosi.
- Se sono costretti in un unico formato di file colonnare, la lettura dei punti diventa costosa.
- Se vengono trattati come file oggetto non correlati, la gestione delle versioni diventa fragile.
Il modello di archiviazione deve quindi partire dal fatto che il set di dati è eterogeneo.
Questo porta a tre requisiti di progettazione:
- Primo, i diversi gruppi di colonne devono essere memorizzati in formati fisici diversi.
- In secondo luogo, questi gruppi di colonne hanno bisogno di uno spazio ID riga condiviso, in modo da potersi comportare come un'unica tabella logica.
- In terzo luogo, il set di dati ha bisogno di un Manifest versionato che dichiari quali file, indici, log, statistiche e riferimenti agli oggetti appartengono alla vista corrente.
Questo è il progetto alla base di Loon, il nostro nuovo motore di archiviazione alla base di Milvus e Zilliz Cloud.
Loon: un motore di archiviazione dietro Milvus e Zilliz Cloud per insiemi di dati vettoriali in evoluzione
Per risolvere tutti questi problemi, abbiamo creato Loon, il nuovo motore di storage per Milvus e Zilliz Vector Lakebase (la prossima evoluzione di Zilliz Cloud), progettato per i dataset vettoriali in evoluzione.
Il nome segue la tradizione di Zilliz di dare un nome agli uccelli. Un loon è un uccello subacqueo che vive sui laghi, il che si adatta bene all'obiettivo del sistema: un database vettoriale non deve spostare, scansionare o riscrivere un intero lago di dati ogni volta che esegue una query, riempie una colonna o costruisce un indice. Dovrebbe prima comprendere la versione corrente del dataset, comprese le colonne, gli indici, le statistiche, i registri delle cancellazioni e i riferimenti agli oggetti, quindi leggere solo la parte di cui ha effettivamente bisogno.
I formati di file ibridi, l'allineamento degli ID di riga e il Manifest non sono tre caratteristiche separate. Esse derivano dallo stesso presupposto progettuale: un set di dati vettoriali è intrinsecamente eterogeneo.
Tre pezzi, un modello di archiviazione
I formati di file ibridi riconoscono che colonne diverse hanno modelli di accesso diversi. I campi scalari sono adatti a scansioni e filtri. I campi vettoriali necessitano di una ricerca efficiente a livello di riga. Gli oggetti grezzi come i video, i PDF, le immagini e i file audio devono essere memorizzati negli oggetti, non nei file di dati dei database.
L'allineamento dell'ID riga riconosce che queste colonne possono essere fisicamente separate, ma descrivono comunque le stesse righe logiche. Una didascalia, un incorporamento, un vettore sparso e un URI video possono risiedere in file e formati diversi, ma devono comunque essere riuniti in un unico risultato.
Il Manifesto riconosce che il set di dati non viene scritto una volta sola e lasciato in pace. Sarà modificato da più sistemi, in più versioni e per più compiti. Gli indici, le statistiche, i registri delle cancellazioni, i riferimenti a oggetti esterni e i gruppi di colonne devono apparire tutti nella stessa vista versionata.
Ecco perché Loon non è solo un formato di file vettoriale più veloce. Un formato più veloce aiuta la ricerca dei punti, ma non risolve l'evoluzione dello schema o il coordinamento tra più motori. L'allineamento dell'ID di riga consente alle colonne divise di comportarsi come una singola tabella, ma non specifica quali file appartengono alla versione corrente. Un Manifest può descrivere lo stato di un set di dati, ma senza gruppi di colonne e allineamento degli ID di riga, non può rappresentare in modo pulito diversi layout fisici all'interno di una raccolta logica.
Il modello di archiviazione ha bisogno di tutte e tre le cose: formati diversi per i diversi gruppi di colonne, uno spazio ID di riga condiviso per ricostruire le righe e un Manifest versionato che indichi a ogni lettore e scrittore qual è il dataset attuale.
Dove si inserisce Loon in Milvus e Zilliz Vector Lakebase
In Milvus, sostituisce il vecchio livello di archiviazione binlog a segmenti con un modello costruito intorno a Manifest, ColumnGroup, formato di file e astrazioni di filesystem. In Zilliz Vector Lakebase (la prossima evoluzione di Zilliz Cloud), la stessa direzione si applica all'architettura di Vector Lakebase: mantenere il percorso di servizio del database vettoriale veloce e rendere i dati sottostanti più facili da evolvere, analizzare e coordinare con sistemi esterni.
I componenti Milvus di livello superiore mantengono i loro ruoli familiari. Proxy gestisce l'instradamento. QueryCoord e DataCoord gestiscono la programmazione. IndexNode costruisce gli indici. Le API rivolte alle applicazioni per le raccolte, gli inserimenti, le ricerche e le ricerche ibride non hanno bisogno di esporre file Manifest o ColumnGroup.
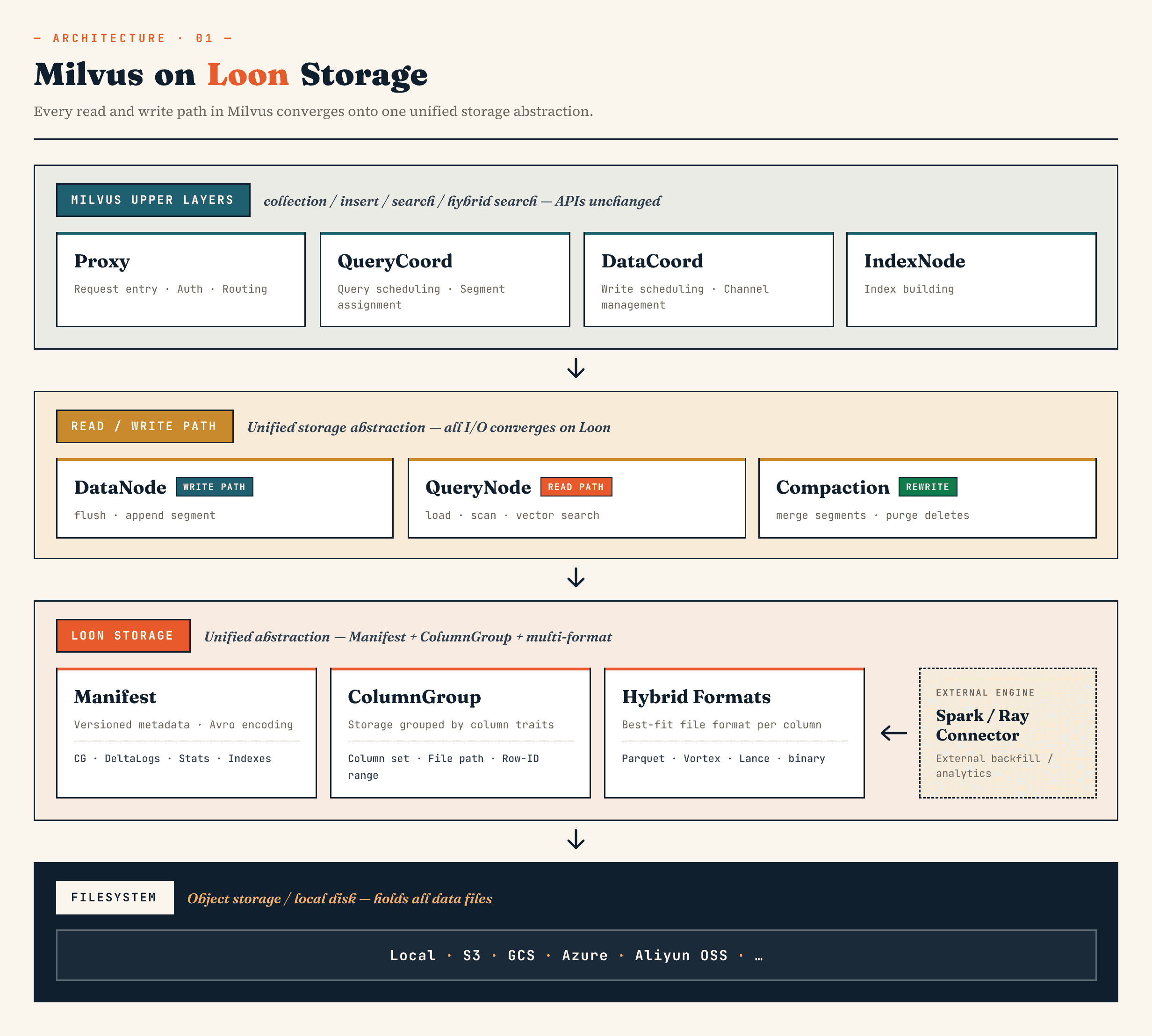
Il cambiamento è sotto gli occhi di tutti.
DataNode, QueryNode, segcore, compattazione e connettori esterni possono operare attraverso la stessa astrazione di storage. Questo è importante perché l'insieme di dati non è più scritto e letto solo dal database. Può essere esteso da sistemi di calcolo esterni e consumato simultaneamente dalla ricerca online.
Ad alto livello, i livelli appaiono come segue:
Manifest
→ ColumnGroup
→ file format layer
→ filesystem abstraction
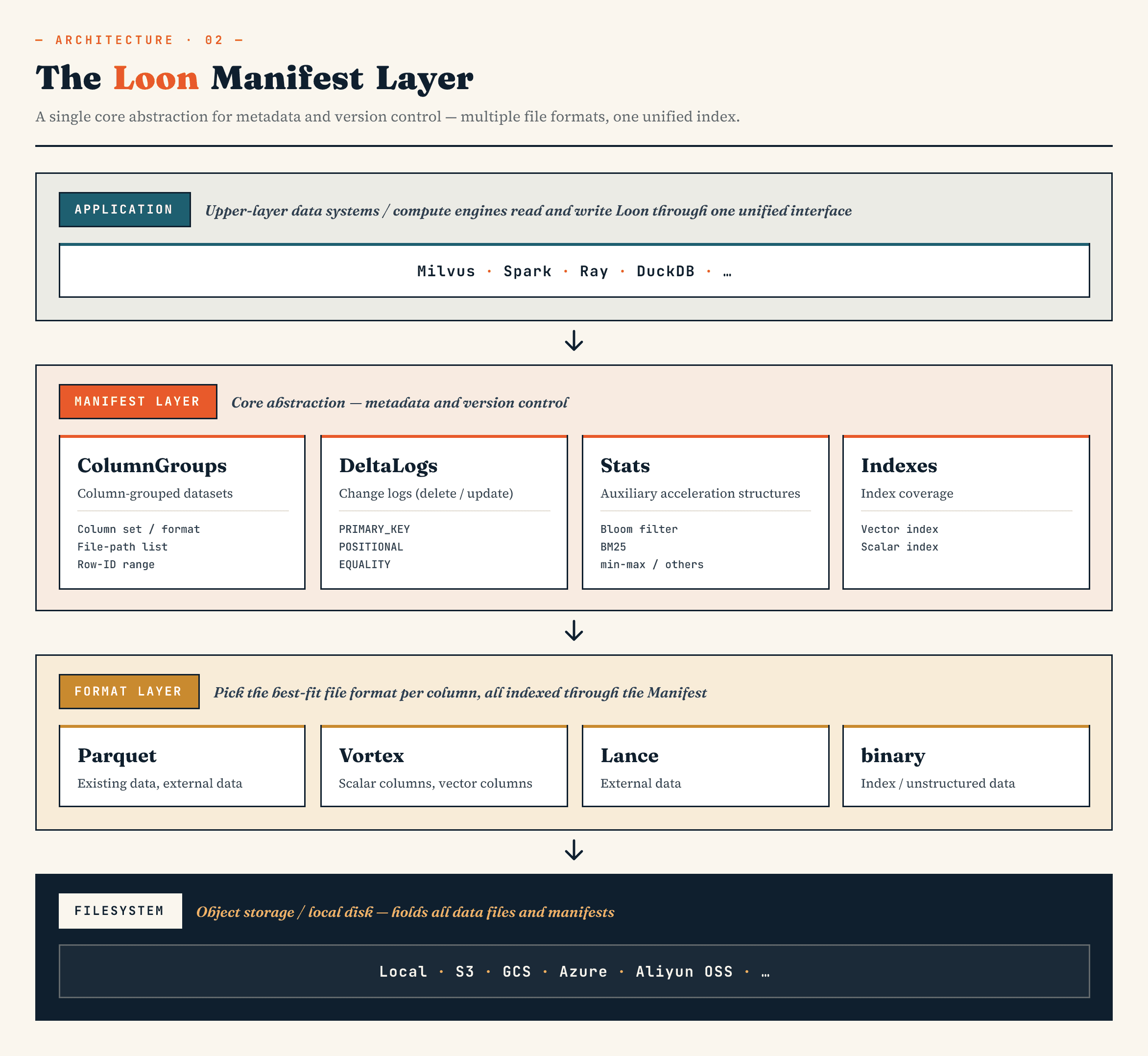
Il Manifest descrive lo stato di versione del set di dati. I gruppi di colonne mappano un insieme logico in gruppi fisici di colonne. Il livello del formato dei file consente a ogni ColumnGroup di scegliere un formato appropriato. L'astrazione del filesystem funziona sia con l'archiviazione a oggetti che con l'archiviazione locale.
Il punto importante è che i formati di file ibridi, l'allineamento degli ID di riga e il Manifest non sono caratteristiche separate. Insieme, definiscono il modello di memorizzazione.
Una volta definito questo modello, possiamo esaminare una per una le tre scelte progettuali: come Loon memorizza i diversi gruppi di colonne, come li allinea in righe e come il Manifest trasforma questi file in un set di dati con versioni.
Progettazione 1: utilizzare il formato di file giusto per il gruppo di colonne giusto
Colonne diverse hanno modelli di accesso diversi. Non devono essere costrette nello stesso formato di file.
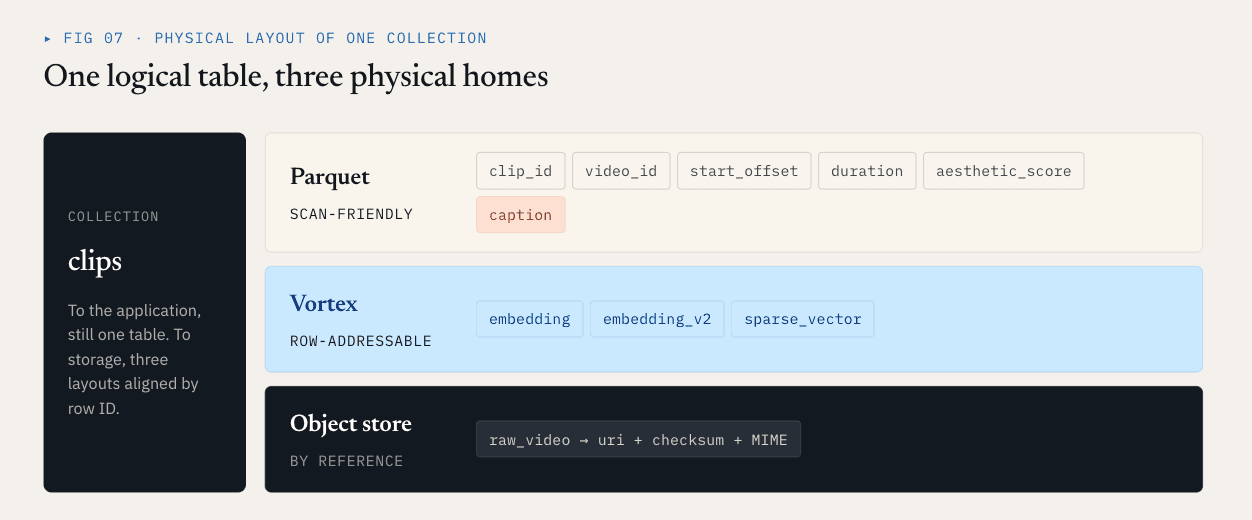
Loon separa una collezione logica in gruppi di colonne.
- I campi scalari, i campi filtro, le business key e i campi statistici vengono spesso scansionati, filtrati, aggregati o utilizzati per la pianificazione delle query. Questi campi beneficiano della compressione, della riduzione delle colonne e della compatibilità con l'ecosistema. Parquet è adatto a queste colonne.
- I vettori densi, i vettori radi e le caratteristiche rerank sono spesso letti dopo il richiamo di RNA per ID riga. Hanno bisogno di un accesso casuale a bassa latenza, di una lettura precisa dell'intervallo di byte e di una decodifica selettiva. Un layout orientato ai segmenti è più adatto. Loon utilizza Vortex in questa direzione.
- Gli oggetti grezzi come video, PDF, immagini e file audio non devono essere incorporati nei file di dati del database vettoriale. Devono rimanere nella memoria degli oggetti. Il database registra riferimenti, checksum, tipi MIME, versioni del parser e relazioni a livello di riga.
Per l'esempio del video, un layout fisico potrebbe apparire come questo:
Parquet ColumnGroup:
clip_id / video_id / start_offset / duration / aesthetic_score / caption
Vortex ColumnGroups:
embedding
embedding_v2
sparse_vector
Object storage:
raw video objects
Per l'applicazione, si tratta ancora di una raccolta. Per il livello di archiviazione, le diverse parti di tale raccolta utilizzano formati fisici diversi. Questo riduce direttamente le riscritture non necessarie. L'aggiunta di embedding_v2 può diventare un nuovo vettore ColumnGroup più un commit di Manifest. Non richiede la riscrittura della colonna caption, dei metadati scalari o della colonna embedding esistente.
La stessa idea si applica ai vettori sparsi, alle caratteristiche rerank o ad altri campi derivati. Se una nuova colonna può essere fisicamente indipendente e allineata in base all'ID della riga, non deve trascinare colonne non correlate nello stesso percorso di riscrittura.
Loon adatta anche l'uso dei formati di file.
Per Parquet, le impostazioni predefinite non sono sempre ideali per i dati vettoriali. Un gruppo di righe da 64 MB può essere troppo grande per la ricerca di punti, perché una piccola lettura casuale può estrarre molti più dati del necessario. Loon restringe i gruppi di righe a 1 MB nei percorsi rilevanti e disabilita le codifiche, come la codifica a dizionario sulle colonne dei vettori, quando non aiutano i dati vettoriali dall'aspetto casuale.
Per Vortex, il lavoro più importante è il layout. Loon utilizza un layout che bilancia l'efficienza della scansione e la ricerca dei punti. All'interno di un gruppo di righe, i segmenti di colonne correlate possono essere posizionati vicini per supportare la scansione. Per eseguire le operazioni, la lettura dei sotto-segmenti consente al sistema di recuperare solo i byte rilevanti, anziché estrarre un intero segmento.
Loon supporta anche l'integrazione con Lance in sola lettura, per cui i dataset Lance esistenti possono essere montati come gruppi di colonne quando la compatibilità è importante.
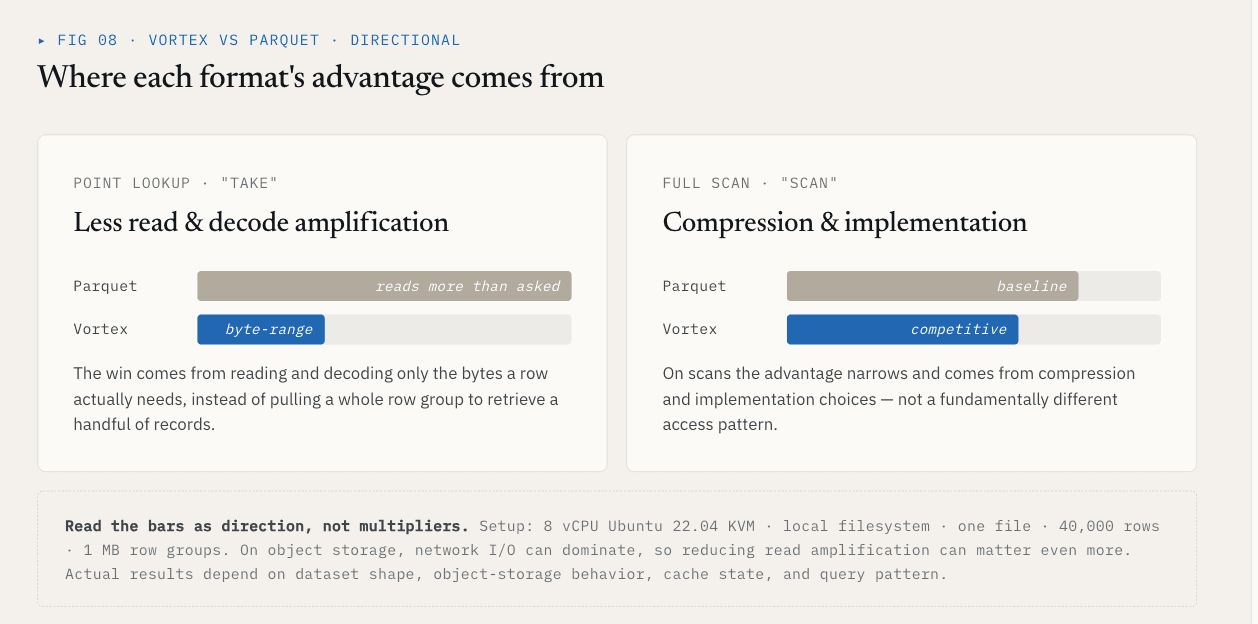
Cosa mostra il benchmark
In un test locale, utilizzando un singolo file con 40.000 righe e lo schema {id: int64, name: utf8, value: float64, vector: list<float32>[128]}, Vortex ha ottenuto questi risultati rispetto a Parquet con gruppi di righe da 1 MB:
| Operazione | Vortex | Parquet | Differenza |
|---|---|---|---|
| Take, K=1000 righe casuali | 5,8 ms | 144 ms | 25 volte più veloce |
| Scansione vettoriale completa delle colonne | 21 ms | 142 ms | 6,76x più veloce |
| Dimensioni del file, ~21 MB di dati grezzi | 6,62 MB | 7,16 MB | 7% più piccolo |
Il risultato di take deriva dalla riduzione della quantità di dati irrilevanti che devono essere letti e decodificati. Il risultato della scansione deriva dalle scelte di compressione e di implementazione.
Questi numeri dovrebbero rimanere legati alla loro configurazione: 8 vCPU Ubuntu 22.04 KVM, filesystem locale, un file, 40.000 righe, gruppi di righe da 1 MB e lo schema di cui sopra. Sullo storage a oggetti, l'I/O di rete può dominare, quindi la riduzione dell'amplificazione in lettura può essere ancora più importante. I risultati effettivi dipendono dalla forma del set di dati, dal comportamento dello storage a oggetti, dallo stato della cache e dal modello di query.
Il punto più generale non è che ogni colonna dovrebbe usare Vortex.
Il punto è che i set di dati vettoriali necessitano di una scelta del formato di file a livello di gruppo di colonne.
Progetto 2: allineare i file fisici tramite gli ID di riga
I formati di file ibridi risolvono un problema: le diverse colonne possono ora vivere nei formati più adatti a loro.
Ma questo crea un secondo problema. Se i campi scalari vivono in Parquet, i vettori in Vortex e gli oggetti grezzi in Object Storage, come fa il sistema a trattarli come un'unica collezione?
Loon risolve questo problema con l'allineamento dell'ID di riga.
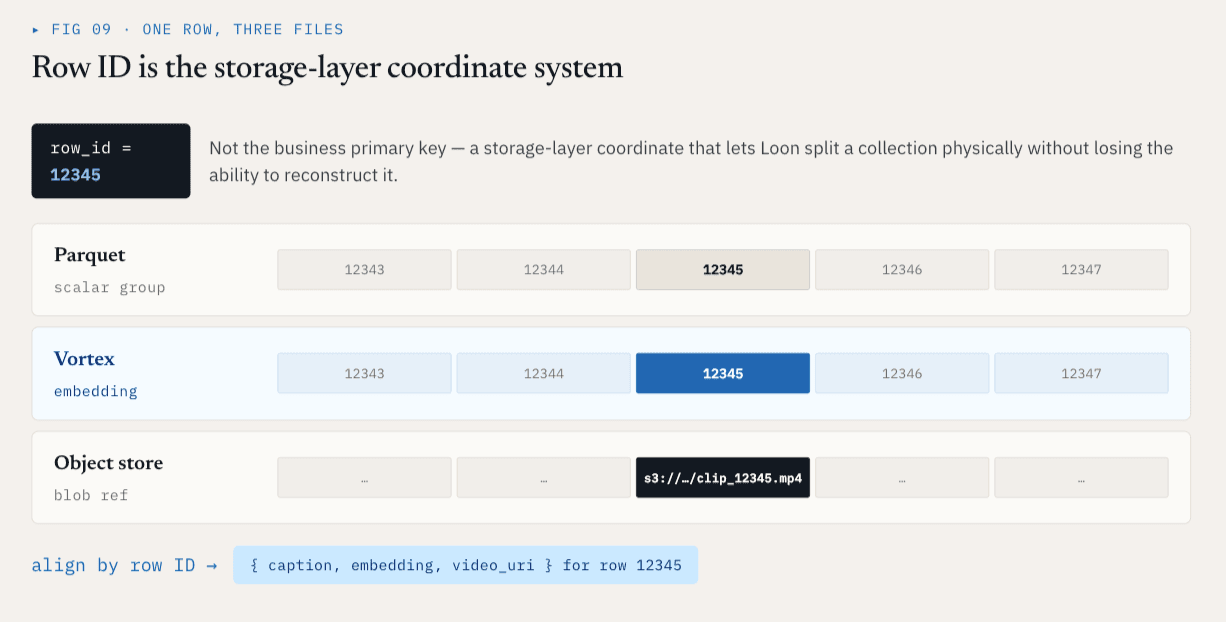
L'ID riga è il sistema di coordinate del livello di memorizzazione
Ogni ColumnGroupFile fisico registra il percorso del file e l'intervallo di ID riga che copre:
path
start_index
end_index
ColumnGroup diversi possono coprire lo stesso spazio di ID riga anche se si trovano in file e formati diversi.
Per l'ID riga 12345, i metadati scalari possono trovarsi in un ColumnGroup Parquet, l'embedding in un ColumnGroup Vortex e il video grezzo può essere rappresentato da un riferimento di memorizzazione di oggetti. Logicamente, si tratta sempre di un'unica riga. In questo modo il livello di memorizzazione ha un sistema di coordinate stabile.
L'ID riga non è la chiave primaria dell'azienda. È il sistema di coordinate del livello di archiviazione che consente a Loon di dividere fisicamente una raccolta senza perdere la capacità di ricostruirla logicamente.
Le nuove colonne non devono riscrivere le vecchie colonne
L'aggiunta di embedding_v2 non richiede la riscrittura della didascalia, dei metadati o dei gruppi di colonne embedding_v1 originali. Loon può scrivere un nuovo ColumnGroup vettoriale, registrare l'intervallo di ID di riga che copre e fare il commit di questa modifica attraverso il Manifest.
Lo stesso vale per i vettori sparsi, le caratteristiche rerank o altri campi derivati che arrivano in seguito.
Finché il nuovo ColumnGroup copre il giusto intervallo di ID riga, può unirsi alla stessa collezione logica senza forzare lo spostamento di dati non correlati.
Le cancellazioni e la compattazione possono essere più mirate
L'allineamento dell'ID riga è utile anche per le cancellazioni.
Una cancellazione può essere espressa prima attraverso un registro di cancellazione. La riga diventa invisibile a livello logico, mentre la pulizia fisica viene rimandata fino alla compattazione. Quando la compattazione viene eseguita, non è sempre necessario riscrivere tutti i gruppi di colonne legati alle righe interessate. Può concentrarsi sui gruppi di colonne che necessitano di una pulizia.
Questo è importante perché non tutte le colonne hanno lo stesso profilo di costo. Riscrivere un breve gruppo di colonne scalare è molto diverso dal riscrivere centinaia di gigabyte di vettori densi.
La ricerca ibrida può recuperare solo le colonne di cui ha bisogno
L'allineamento dell'ID di riga è anche ciò che rende la ricerca ibrida pratica su formati di file ibridi.
Dopo che la ricerca ANN restituisce gli ID di riga candidati, il sistema può recuperare solo i campi necessari per il risultato finale: didascalie, metadati, vettori, caratteristiche di rerank o riferimenti agli oggetti.
Ad esempio, una query può richiedere:
caption
embedding
video_uri
Questi campi possono trovarsi in diversi gruppi di colonne. Loon può individuare i file pertinenti in base all'intervallo di ID riga, leggere gli intervalli di byte necessari e assemblare il risultato.
Senza l'allineamento dell'ID riga, i formati ibridi sarebbero solo file separati affiancati. Con l'allineamento dell'ID riga, si comportano come un'unica raccolta logica.
Packed Reader nasconde la suddivisione al livello superiore
Il componente di runtime che rende tutto ciò utilizzabile è il Packed Reader.
Il livello superiore vede un flusso unificato Arrow RecordBatch. Al di sotto, i dati possono provenire da più gruppi di colonne in diversi formati di file. Il Packed Reader nasconde queste differenze, allinea i dati per intervalli di ID riga e pianifica l'I/O di più file con un utilizzo controllato della memoria.
Supporta anche take diretto per ID riga. Dato un insieme di ID riga, individua i ColumnGroupFiles pertinenti, esegue la lettura dell'intervallo e restituisce i campi richiesti.
Per il flusso di lavoro video, una query ANN può richiedere caption, embedding e video_uri. Il Packed Reader può recuperare il ColumnGroup scalare e il ColumnGroup vettoriale senza toccare colonne non correlate.
Questa è la differenza tra "file separati" e "una tabella con più layout fisici".
Progetto 3: fare del Manifest la fonte della verità
I formati di file ibridi definiscono il modo in cui i dati sono fisicamente memorizzati. L'allineamento dell'ID riga determina il modo in cui i gruppi di colonne separati formano ancora un'unica tabella logica. Ma il sistema deve ancora rispondere a una domanda più grande: quali file, registri, statistiche, indici e riferimenti a oggetti appartengono alla versione corrente del dataset? Questo è il compito del Manifest.

Le directory di archiviazione degli oggetti non sono sufficienti
L'archiviazione degli oggetti non è un catalogo di database. Una directory può contenere vecchi file, nuovi file, risultati di lavori falliti, file temporanei, registri di cancellazione, file ancora referenziati da vecchie istantanee e file in attesa di pulizia. Il fatto che un file esista non significa che appartenga alla versione corrente del dataset.
Un set di dati Loon può essere organizzato in directory come:
_metadata/
_data/
_delta/
_stats/
_index/
Ma la struttura delle directory non è la fonte della verità. Lo è il Manifesto. I lettori non dovrebbero elencare le directory e dedurre lo stato da qualsiasi file esistente. Dovrebbero leggere il Manifesto corrente e seguire la vista versionata che dichiara.
Il Manifesto definisce una vista versionata dell'insieme di dati
Il Manifesto definisce il set di dati in una determinata versione. Registra:
- quali gruppi di colonne esistono
- quali intervalli di ID riga coprono
- quale formato fisico utilizza ciascun gruppo di colonne
- dove risiedono i file
- quali registri di cancellazione sono attivi
- quali statistiche sono disponibili
- quali indici esistono
- a quali blob esterni si fa riferimento
- quali colonne e intervalli di righe coprono le statistiche o gli indici.
Ogni aggiornamento scrive una nuova versione del Manifest. Un lettore che apre la versione N vede una visione stabile del set di dati alla versione N. Uno scrittore può preparare la versione N+1 senza disturbare i lettori che stanno ancora usando la versione N.
Il Manifest non tiene traccia solo dei file di tabella
In Loon, il corpo del Manifest è codificato con Apache Avro e organizzato in quattro sezioni principali.
- ColumnGroups descrive le colonne, i formati, i file e gli intervalli di ID delle righe.
- DeltaLogs descrive le cancellazioni. I diversi tipi di cancellazione coprono diverse fonti di cambiamento, come le cancellazioni di chiavi primarie dai client, le cancellazioni posizionali dalla compattazione interna o le cancellazioni di uguaglianza dai motori esterni.
- Le statistiche includono metadati di pianificazione come i filtri bloom, le statistiche BM25 e i valori min/max.
- Gli indici descrivono il tipo di indice, i parametri, le colonne coperte e gli intervalli di ID riga. Possono includere indici vettoriali come HNSW o IVF, indici di testo, indici invertiti, indici bitmap e strutture correlate.
È qui che Loon si differenzia da un manifesto tabellare tradizionale.
Un set di dati vettoriali deve tenere traccia non solo dei file di dati e delle partizioni. Deve anche tenere traccia degli indici vettoriali, degli indici di testo, delle caratteristiche sparse, dei registri di cancellazione, delle statistiche, dei riferimenti a oggetti esterni e degli intervalli di ID riga che li collegano.
Il Manifest deve essere scrivibile da più di un database
La parte più importante non è solo ciò che contiene il Manifest. È chi può scriverlo.
- Se solo il database può scrivere il Manifest, esso rimane un metadato interno. Metadati più puliti, ma comunque privati di un motore.
- Se i motori esterni possono generare nuovi ColumnGroup, statistiche e voci del Manifest, quest'ultimo diventa un'interfaccia di coordinamento.
- Un lavoro Spark, per esempio, può riempire una colonna vettoriale sparsa. Scrive un nuovo ColumnGroup, registra la copertura delle righe e le statistiche e invia un nuovo Manifest. Le query online possono continuare a leggere la vecchia versione durante il lavoro. Quando il commit ha successo, la nuova versione diventa visibile.
Lo spirito è simile a quello di Iceberg e Delta Lake, ma il modello degli oggetti è più ampio. Un set di dati vettoriali deve tenere traccia degli indici vettoriali, degli indici testuali, delle caratteristiche sparse, dei registri di cancellazione, delle statistiche, dei riferimenti ai blob e degli intervalli di ID delle righe, non solo dei file delle tabelle e delle partizioni.
I commit ottimistici semplificano gli aggiornamenti di versione
Ogni commit scrive una nuova versione del Manifest. Uno scrittore può creare nuovi contenuti basati sulla versione N, quindi tentare di scrivere manifest-{N+1}.avro. Le semantiche di scrittura condizionale dell'Object Storage o di corrispondenza generazionale possono far fallire il commit se la versione esiste già. Lo scrittore può quindi riprovare con la versione più recente.
In questo modo Loon offre una concorrenza ottimistica senza costringere ogni aggiornamento a un percorso di coordinamento pesante e fortemente coerente. Senza un manifesto, l'archiviazione multiformato e multimotore si trasforma in convenzioni di denominazione e riconciliazione manuale. Questo può funzionare per piccoli insiemi di dati. Non funziona per i dati vettoriali su scala TB.
Il Manifest è l'elemento che trasforma i file eterogenei in un set di dati che più sistemi possono leggere e aggiornare in modo sicuro.
Cosa cambia per gli utenti quando lo storage diventa versionato
Per gli sviluppatori di applicazioni, Loon non dovrebbe diventare un nuovo onere per le API.
Gli utenti dovrebbero continuare a lavorare con i concetti familiari di Milvus: collezioni, inserimenti, ricerca e ricerca ibrida. Non dovranno pensare ai file Manifest, ai gruppi di colonne, agli intervalli di ID delle righe o al layout dei file durante il normale sviluppo delle applicazioni.
Il cambiamento è sotto gli occhi di tutti. L'archiviazione diventa più consapevole di come si evolvono effettivamente i set di dati AI.
L'aggiunta di un nuovo incorporamento non deve spostare i vecchi dati
In precedenza, l'aggiunta di embedding_v2 a una raccolta esistente richiedeva spesso l'esportazione dei dati, l'addestramento di un nuovo modello, la generazione di vettori e quindi la reimportazione o l'aggiornamento della raccolta tramite l'SDK. Questo percorso comporta una grande quantità di lavoro operativo: tracciamento delle versioni, tentativi di lavoro falliti, ricostruzione degli indici, impatto del servizio e controlli di coerenza.
Con Loon, questo può diventare un'evoluzione dello schema più un commit di un nuovo gruppo di colonne. La nuova colonna embedding può essere scritta come un proprio ColumnGroup fisico, allineato per ID riga e reso visibile attraverso il Manifest. La vecchia colonna caption, la colonna dei metadati scalari e la colonna di incorporamento originale non devono essere spostate.
I backfill non dovrebbero richiedere un ciclo di aggiornamento lato client
Molti aggiornamenti dei dati AI sono backfill. Un team può aggiungere vettori sparsi dopo che la ricerca ibrida diventa importante. Può aggiungere caratteristiche di rerank dopo l'addestramento di un nuovo modello. Può correggere le didascalie dopo la revisione umana. Può aggiungere tag di governance dopo un aggiornamento dei criteri.
In un layout tradizionale, queste modifiche avvengono spesso tramite aggiornamenti dell'SDK del client o percorsi di scrittura solo per il database, anche quando i dati sono prodotti da Spark, Ray o un altro motore esterno.
Con Loon, i sistemi di calcolo esterni possono produrre nuovi ColumnGroup e impegnarli attraverso il Manifest. Il database non deve più essere l'unico punto di ingresso per ogni riscrittura.
L'analisi offline non deve richiedere un'altra copia della verità
In precedenza, i team spesso scaricavano una raccolta online in Parquet per la valutazione o l'analisi offline. Questo crea due versioni dello stesso set di dati: la raccolta online e la copia di analisi. Una volta corrette le didascalie, rigenerate le incorporazioni, applicati i log di cancellazione o ricostruiti gli indici, il team deve chiedersi quale sia la copia corrente.
Con un modello di archiviazione basato su Manifest, i motori di analisi possono leggere la stessa vista versionata del dataset del sistema di distribuzione. Possono proiettare solo le colonne di cui hanno bisogno, scansionare solo gli intervalli di righe rilevanti e lavorare su una versione dichiarata del dataset invece che su un'istantanea esportata manualmente.
Le cancellazioni e le correzioni devono riguardare solo ciò che è stato modificato
Le cancellazioni, le correzioni delle didascalie, le correzioni delle etichette e gli aggiornamenti della governance sono operazioni di routine nei dataset AI. Non dovrebbero costringere ogni colonna del vettore lungo a seguire lo stesso percorso di riscrittura.
Con Loon, la cancellazione dei registri può essere trattata prima come una cancellazione logica. La successiva compattazione può ripulire i gruppi di colonne interessati senza riscrivere i dati non correlati. Se un breve campo di testo cambia, il livello di archiviazione non deve riscrivere centinaia di gigabyte di vettori densi solo perché condividono la stessa riga logica.
I motori esterni diventano parte del flusso di lavoro, non una via di fuga
Il cambiamento più importante è che i motori esterni non sono più trattati come sistemi esterni al database vettoriale.
Spark, Ray, i lavori di valutazione, i sistemi di etichettatura e le pipeline di governance producono e modificano già gran parte dei dati. Il livello di archiviazione dovrebbe consentire loro di collaborare attorno a un'unica fonte di verità, anziché esportare, copiare e reimportare continuamente.
Questo è ciò che rende possibile una versione di Manifest. Fornisce al servizio online, all'analisi offline, ai lavori di backfill e alla compattazione una visione condivisa del set di dati.
Questi possono sembrare dettagli di archiviazione interna, ma influenzano la velocità con cui i team possono iterare sui set di dati AI. Ogni modifica del modello, backfill delle funzionalità, correzione delle didascalie, filtro di qualità e ricostruzione dell'indice dipende dalla stessa domanda: "Il sistema può aggiornare il dataset senza spostare dati che non è necessario spostare?".
Questo è il valore pratico del modello di archiviazione.
Loon è disponibile in Milvus 3.0 beta e Zilliz Vector Lakebase
Loon è disponibile in Milvus 3.0 beta e fa anche parte del livello di storage di Zilliz Vector Lakebase, la prossima evoluzione di Zilliz Cloud. Questa release si concentra su tre aree principali:
- Il Manifesto. L'obiettivo è che le scritture, i backfill, le cancellazioni, le statistiche e gli aggiornamenti dell'indice producano visualizzazioni del dataset in versione che i lettori possano aprire in modo coerente. Per i lettori, questo significa che una query può aprire una versione specifica del Manifest e vedere una vista stabile del dataset. Per gli autori, questo significa che i nuovi file di dati, i registri delle cancellazioni, le statistiche o i file degli indici possono essere preparati prima e poi resi visibili attraverso un commit con versione.
- Il gruppo di colonne e il supporto del formato. Parquet supporta colonne scalari ed ecosistemiche. Vortex supporta modelli di accesso vettoriali. Lance può essere integrato in modalità di sola lettura per la compatibilità con i set di dati Lance esistenti.
- L'indice su Lake. Gli indici scalari, gli indici di filtraggio e gli indici invertiti di testo possono partecipare alla pianificazione basata su Manifest per intervallo di righe. Gli indici vettoriali nativi di Lake sono più coinvolti. HNSW e IVF hanno un comportamento diverso sullo storage degli oggetti e HNSW in particolare è sensibile all'accesso casuale e alla localizzazione della cache. Non è possibile riutilizzare semplicemente un layout progettato per un SSD locale e aspettarsi lo stesso risultato.
C'è ancora del lavoro da fare
- Ipercorsi di scrittura esterni sono importanti perché Spark e Ray dovrebbero essere in grado di produrre ColumnGroups e Manifest commits senza forzare ogni backfill attraverso un ciclo SDK client.
- L'interoperabilità di Lakehouse è importante perché molti team utilizzano già cataloghi e motori di interrogazione come Iceberg, Delta Lake, Trino, DuckDB e Athena. I dati vettoriali devono poter partecipare a questo ecosistema senza perdere le prestazioni della ricerca vettoriale.
- Illayout degli indici è importante perché gli indici a grafo e le strutture invertite hanno schemi di accesso diversi sullo storage degli oggetti.
- La semantica degli oggetti di grandi dimensioni è importante perché i video, i PDF, le immagini e i file audio grezzi richiedono un comportamento di gestione dei riferimenti, di versionamento e di cancellazione in linea con il set di dati vettoriale derivato.
L'esatto comportamento di rilascio, le impostazioni predefinite e il percorso di migrazione dovrebbero seguire le note di rilascio di Milvus e Zilliz Cloud. La direzione dello storage, tuttavia, è chiara: i database vettoriali hanno bisogno di una base versionata e nativa del lago sotto il livello di servizio.
Provate Loon sotto Zilliz Vector Lakebase
Se il vostro stack attuale separa il servizio online, l'analisi offline, i backfill e i flussi di lavoro esterni del data lake in sistemi diversi, vale la pena dare un'occhiata a Zilliz Vector Lakebase. È possibile provarlo in Zilliz Cloud. Le nuove iscrizioni via e-mail ricevono 100 dollari di crediti gratuiti. Siete inoltre invitati a parlarci del vostro caso d'uso.
Potete anche seguire il rilascio di Milvus 3.0 per vedere come Loon si evolve nel motore open-source.
Zilliz Vector Lakebase riunisce:
- Servizio a livelli per diversi compromessi in termini di prestazioni e costi in tempo reale
- Ricerca on-demand per carichi di lavoro su larga scala o esplorativi senza calcoli sempre disponibili
- Ricerca esterna al data lake, in modo da poter indicizzare e ricercare direttamente sui dati del lake esistente
- Ricerca a tutto campo su vettori, testo, JSON e dati geospaziali, con recupero ibrido e reranking
- Storage unificato nativo del lago basato su Vortex, un formato aperto progettato per letture casuali più veloci e a basso costo su dati vettoriali.
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word



