Что такое Milvus?
Всё, что вам нужно знать о Milvus менее чем за 10 минут.
Что такое векторные вложения?
Векторные вложения — это числовые представления, полученные из моделей машинного обучения, которые заключают в себе семантическое значение неструктурированных данных. Эти вложения генерируются путем анализа сложных корреляций внутри данных нейронными сетями или трансформерными архитектурами, создавая плотное векторное пространство, где каждая точка соответствует "значению" объектов данных, таких как слова в документе.
Этот процесс преобразует текстовые или другие неструктурированные данные в векторы, которые отражают семантическое сходство — слова с близкими значениями располагаются ближе друг к другу в этом многомерном пространстве, облегчая тип поиска, известный как "плотный векторный поиск". Это контрастирует с традиционным поиском по ключевым словам, который полагается на точные совпадения и использует разреженные векторы. Разработка векторных вложений, часто происходящая от фундаментальных моделей, обученных интенсивно крупными технологическими компаниями, позволяет более нюансированные поиски, которые захватывают суть данных, выходя за рамки ограничений лексических или разреженных векторных методов поиска.
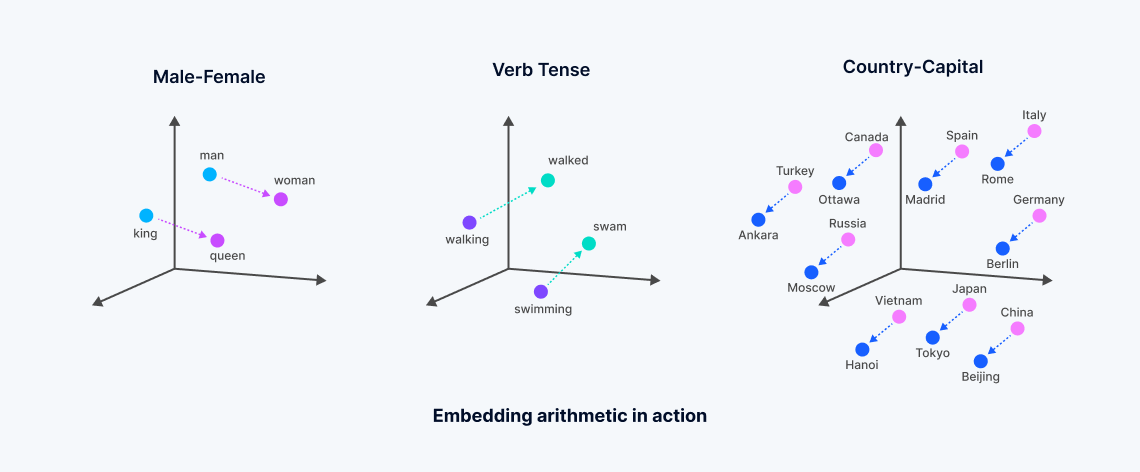
Для чего можно использовать векторные вложения?
Векторные вложения могут быть использованы в различных приложениях, повышая эффективность и точность различными способами. Вот некоторые из наиболее частых случаев использования:
Поиск похожих изображений, видео или аудиофайлов
Векторные вложения позволяют искать похожий мультимедийный контент по содержанию, а не только по ключевым словам, используя сверточные нейронные сети (CNN) для анализа изображений, кадров видео или аудиосегментов. Это позволяет проводить продвинутые поиски, такие как нахождение изображений по звуковым подсказкам или видео по запросам изображений, сравнивая вложенные представления, хранящиеся в векторных базах данных.
Ускорение открытия лекарств
В фармацевтической промышленности векторные вложения могут кодировать химические структуры соединений, облегчая идентификацию перспективных кандидатов на лекарства путем измерения их сходства с целевыми белками. Это ускоряет процесс открытия лекарств, экономя время и ресурсы, сосредотачиваясь на наиболее жизнеспособных зацепках.
Повышение релевантности поиска с помощью семантического поиска
Путем вложения внутренних документов в векторы организации могут использовать семантический поиск для улучшения релевантности результатов поиска. Этот метод использует концепцию Retrieval Augmented Generation (RAG) для понимания намерения за запросами, предоставляя ответы из данных компании через модели ИИ, такие как ChatGPT, тем самым уменьшая количество нерелевантных результатов и галлюцинаций ИИ.
Рекомендательные системы
Векторные вложения революционизируют рекомендательные системы, представляя пользователей и элементы как вложения для измерения сходства. Этот подход позволяет персонализированные рекомендации на основе индивидуальных предпочтений, повышая удовлетворенность пользователей и вовлеченность в онлайн-платформы.
Обнаружение аномалий
В таких областях, как обнаружение мошенничества, сетевая безопасность и промышленный мониторинг, векторные вложения играют ключевую роль в выявлении необычных паттернов. Точки данных, представленные как вложения, позволяют обнаруживать аномалии путем вычисления расстояний или различий, способствуя раннему выявлению и превентивным мерам против потенциальных проблем.
Что такое векторные базы данных?
Векторные базы данных — это специализированные системы, предназначенные для управления и извлечения неструктурированных данных через векторные вложения и числовые представления, которые захватывают суть элементов данных, таких как изображения, аудио, видео и текстовый контент. В отличие от традиционных реляционных баз данных, которые работают со структурированными данными с точными операциями поиска, векторные базы данных преуспевают в поисках семантического сходства с использованием таких техник, как алгоритм Approximate Nearest Neighbor (ANN). Эта возможность критически важна для разработки приложений в различных областях, включая рекомендательные системы, чат-боты и инструменты поиска мультимедийного контента, а также для решения проблем, поставленных ИИ и большими языковыми моделями, такими как ChatGPT, таких как понимание контекста и нюансов и галлюцинаций ИИ.
Появление векторных баз данных, таких как Milvus, трансформирует отрасли, позволяя поиск по содержанию в огромном массиве неструктурированных данных, выходя за рамки ограничений меток, созданных человеком. Ключевые особенности, которые выделяют векторные базы данных, включают
Масштабируемость и настраиваемость для обработки растущих объемов данных
Мультиарендность и изоляция данных для эффективного использования ресурсов и конфиденциальности
Комплексный набор API для различных языков программирования
Пользовательские интерфейсы, которые упрощают взаимодействие с комплексными данными.
Эти атрибуты обеспечивают, чтобы векторные базы данных могли удовлетворить требования современных приложений, предлагая мощные инструменты для исследования и использования неструктурированных данных способами, которые не могут традиционные базы данных.
Векторная база данных против библиотеки векторного поиска
Библиотеки векторного поиска, такие как FAISS, ScaNN и HNSW, предлагают базовые инструменты для создания прототипных систем, способных выполнять эффективные поиски сходства и кластеризацию плотных векторов. Эти библиотеки, хотя и мощные и с открытым исходным кодом, предназначены в основном для извлечения векторов и предлагают быструю настройку с возможностями, такими как обработка больших коллекций векторов и предоставление интерфейсов для оценки и настройки параметров. Однако они недостаточны в плане масштабируемости, мультиарендности и динамического изменения данных, что делает их менее подходящими для более крупных и сложных наборов данных и растущих пользовательских баз.
В отличие от этого, векторные базы данных выступают как более комплексное решение, предназначенное для хранения и извлечения в реальном времени миллионов и миллиардов векторов. Они предоставляют более высокий уровень абстракции, масштабируемости, облачности и пользовательских функций, которые превосходят базовые функции библиотек векторного поиска. Хотя библиотеки, такие как FAISS, являются важными компонентами, на которых могут строиться векторные базы данных, последние являются полноценными сервисами, которые упрощают операции, такие как вставка и управление данными, делая их более соответствующими требованиям крупномасштабных динамических приложений в области обработки неструктурированных данных.
Векторные базы данных против плагинов векторного поиска для традиционных баз данных
Векторные базы данных и плагины векторного поиска для традиционных баз данных выполняют разные роли в обработке векторных поисков. Плагины, такие как в Elasticsearch 8.0, предлагают возможности векторного поиска в рамках существующих архитектур баз данных, функционируя как улучшения, а не комплексные решения. Эти плагины не имеют полного подхода к управлению вложениями и векторному поиску, что приводит к ограничениям и неоптимальной производительности для приложений неструктурированных данных.
Ключевые функции, такие как настраиваемость и удобные API/SDK, необходимые для эффективной работы векторной базы данных, отсутствуют в плагинах векторного поиска. Например, движок ANN Elasticsearch, хотя и поддерживает базовое хранение и запросы векторов, ограничен своим алгоритмом индексации и опциями метрик расстояния, предлагая меньшую гибкость по сравнению с посвященной векторной базой данных, такой как Milvus. Milvus, разработанный изначально как векторная база данных, предоставляет более интуитивно понятный API, более широкую поддержку методов индексации и метрик расстояния, а также потенциал для подобных SQL запросов, подчеркивая его превосходство в управлении и запросах неструктурированных данных. Это фундаментальное различие подчеркивает, почему векторные базы данных с их комплексными наборами функций и архитектурой, адаптированной для неструктурированных данных, предпочтительны по сравнению с плагинами векторного поиска для достижения оптимального поиска и управления векторными вложениями.
Чем Milvus отличается от других векторных баз данных?
Milvus выделяется как векторная база данных с масштабируемой архитектурой и разнообразными возможностями, предназначенными для ускорения и унификации поискового опыта в различных приложениях. Ключевые особенности включают:
Масштабируемая и эластичная архитектура
Milvus разработан для исключительной масштабируемости и эластичности, соответствуя динамическим требованиям современных приложений. Это достигается за счет ориентированного на сервисы дизайна, отделяющего хранение, координаторы и рабочие узлы, позволяя масштабирование по компонентам. Этот модульный подход обеспечивает, чтобы различные вычислительные задачи могли масштабироваться независимо в соответствии с изменяющимися нагрузками, обеспечивая точное распределение и изоляцию ресурсов.
Разнообразная поддержка индексов
Milvus поддерживает широкий спектр более 10 типов индексов, включая широко используемые, такие как HNSW, IVF, Product Quantization и индексация на основе GPU. Это разнообразие позволяет разработчикам оптимизировать поиски в соответствии с конкретными требованиями к производительности и точности, обеспечивая, чтобы база данных могла адаптироваться к широкому спектру приложений и характеристик данных. Непрерывное расширение индексных предложений, например, GPU-индекс, еще больше повышает адаптивность и эффективность Milvus в обработке сложных задач поиска.
Разнообразные возможности поиска
Milvus предлагает широкий спектр типов поиска, включая top-K Approximate Nearest Neighbor (ANN), Range ANN и поиск с фильтрацией метаданных, а также предстоящий гибридный плотный и разреженный векторный поиск. Это разнообразие обеспечивает непревзойденную гибкость и точность запросов, предоставляя разработчикам возможность настраивать стратегии извлечения данных для удовлетворения конкретных требований приложений, тем самым оптимизируя как релевантность, так и эффективность результатов поиска.
Настраиваемая согласованность
Milvus предлагает модель дельта-согласованности, которая позволяет пользователям указывать "допуск устаревания" для данных запросов, обеспечивая настраиваемый баланс между производительностью запросов и актуальностью данных. Эта гибкость критически важна для приложений, требующих актуальных результатов без ущерба для времени отклика, эффективно поддерживая как сильную, так и конечную согласованность в зависимости от потребностей приложения.
Поддержка аппаратного ускорения вычислений
Milvus разработан для использования различных типов вычислительных возможностей, таких как AVX512 и Neon для выполнения SIMD, а также квантования, оптимизаций с учетом кэша и поддержки GPU. Этот подход обеспечивает эффективное использование конкретных аппаратных возможностей, обеспечивая быструю обработку и экономичную масштабируемость. Адаптируя использование ресурсов к уникальным требованиям различных приложений, Milvus повышает как скорость, так и эффективность управления векторными данными и операций поиска.
Как работает Milvus вкратце?
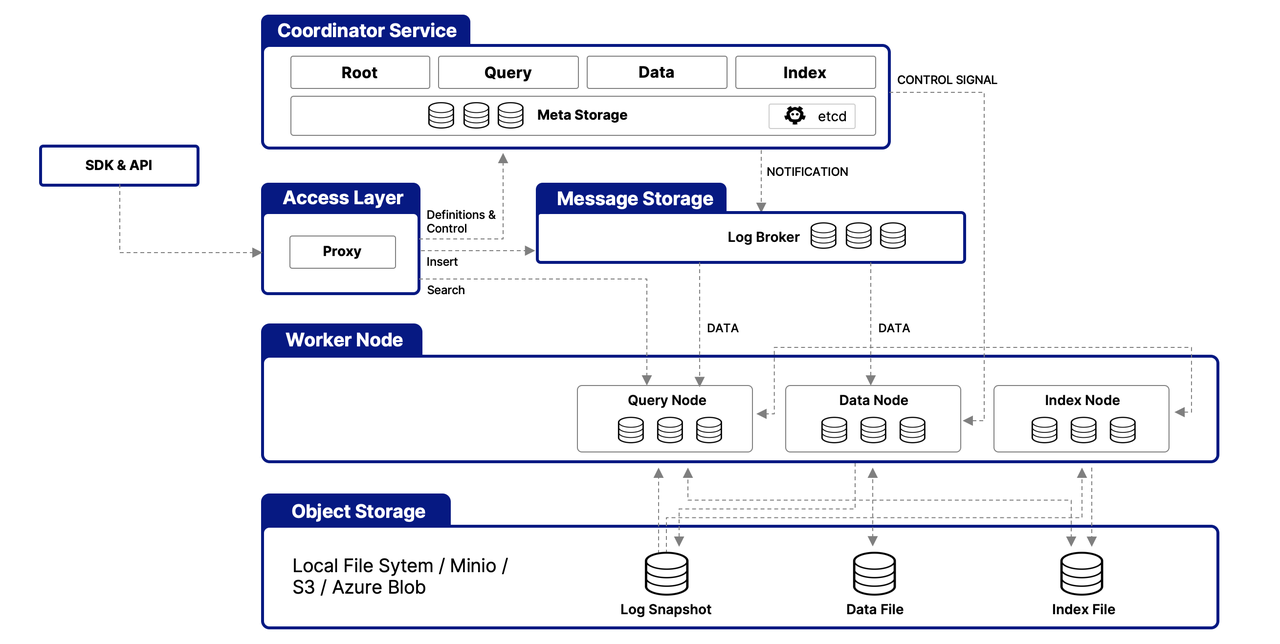
Milvus построен вокруг многослойной архитектуры, предназначенной для эффективной обработки и обработки векторных данных, обеспечивая масштабируемость, настраиваемость и изоляцию данных. Вот упрощенный обзор его архитектуры:
Уровень доступа
Этот уровень служит первоначальной точкой контакта для внешних запросов, используя бессостоятельные прокси для управления подключениями клиентов, статической верификации и динамических проверок. Эти прокси также обрабатывают балансировку нагрузки и являются ключевыми для реализации комплексного набора API Milvus. Как только нижестоящая служба обрабатывает запрос, уровень доступа маршрутизирует ответ обратно пользователю.
Сервис координатора
Выступая в роли центрального командования, эта служба оркестрирует балансировку нагрузки и управление данными через четыре координатора, которые обеспечивают эффективное управление данными, запросами и индексами.
The Root Coordinator: managing data-related tasks and global timestamps
The Query Coordinator: overseeing query nodes for search operations
The Data Coordinator: handling data nodes and metadata
The Index Coordinator: maintaining index nodes and metadata
Рабочие узлы
Ответственные за фактическое выполнение задач, рабочие узлы представляют собой масштабируемые поды, которые выполняют команды от координаторов. Они позволяют Milvus динамически адаптироваться к изменениям данных, запросов и индексации, поддерживая масштабируемость и настраиваемость системы.
Уровень хранения объектов
Основной для сохранения данных, этот уровень состоит из
Meta store: using etcd for metadata snapshots and system health checks
Log broker: for streaming data persistence and recovery, utilizing Pulsar or RocksDB
Object storage: storing log snapshots, index files, and query results, with support for services like AWS S3, Azure Blob Storage, and MinIO
Куда идти дальше?
- To get hands-on experience with Milvus, follow the get started guide.
- To understand Milvus in more detail, read the Documentation.
- Browse through the Use Cases to learn how other users in our worldwide community are getting value from Milvus.
Join a local Unstructured Data meetup and our Discord.