لماذا صممنا Loon: محرك تخزين لبيانات الذكاء الاصطناعي لا يتوقف عن التغير أبداً.
نُشرت هذه المدونة في الأصل على موقع zilliz.com وأعيد نشرها بإذن.
النقاط الرئيسية
هذا بحث هندسي طويل ومتعمق، لذا إليك النقاط الرئيسية قبل الدخول في التفاصيل.
- مجموعات بيانات الذكاء الاصطناعي ليست جداول ثابتة. فالصفوف نفسها تتغير باستمرار حيث تقوم الفرق باستبدال نماذج التضمين وإضافة متجهات متفرقة ومراجعة التسميات التوضيحية وإعادة ملء التسميات وإعادة بناء الفهارس وإجراء تحليلات دون اتصال بالإنترنت.
- تنهار تخطيطات التخزين التقليدية بثلاث طرق: أعمدة المتجهات الطويلة تجعل عمليات الردم مكلفة، ولا يمكن لتنسيق ملف واحد أن يخدم كلاً من عمليات المسح والقراءات النقطية بشكل جيد، كما أن تخزين قاعدة البيانات الخاصة يجبر خطوط الأنابيب الخارجية على إنشاء نسخ إضافية من الحقيقة.
- Loon هو محرك التخزين الجديد لقاعدة بيانات Milvus و Zilliz Vector Lakebase. وهو مبني حول تنسيقات الملفات الهجينة، ومحاذاة معرّف الصف، وبيان يحدد حالة الإصدار الخاص بمجموعة البيانات.
- الهدف من ذلك هو تمكين مجموعة بيانات متجهة واحدة لدعم البحث عبر الإنترنت والتحليل دون اتصال بالإنترنت، والتعبئة الرجعية، والضغط، والحساب الخارجي دون نسخ البيانات أو إعادة كتابتها أو إعادة استيرادها باستمرار.
مقدمة
لفترة من الوقت، كانت هناك حجة واحدة ضد قواعد البيانات المتجهة تبدو معقولة.
فقواعد البيانات التقليدية تخزن بالفعل الأعداد الصحيحة والسلاسل وJSON والنقاط والفهارس. لماذا لا نضيف نوع _vector_ ، وننشئ فهرسًا خاصًا بـ ANN بجانبه، وننتهي من الأمر؟
بالنسبة للبحث الدلالي المبكر، يعمل ذلك بشكل جيد بما فيه الكفاية. يمكن أن يدعم عمود متجه بالإضافة إلى فهرس عرضًا توضيحيًا أو تطبيق RAG صغيرًا أو ميزة بحث داخلي. تظهر المشكلة في وقت لاحق، عندما تبدأ مجموعة البيانات في التصرف بشكل أقل كجدول وأكثر كنظام بيانات ذكاء اصطناعي.
تحتوي مجموعة بيانات متجه الإنتاج على صفوف ومفاتيح أساسية وحقول قياسية وأعمدة قابلة للاستعلام. وبهذا المعنى، تبدو مثل جدول قاعدة بيانات. ولكن لها أيضًا حجم وشكل سير العمل لبحيرة بيانات. قد يحتوي على مئات الملايين من السجلات. يتم قراءتها وإعادة كتابتها بشكل متكرر بواسطة Spark وRay وDuckDB وخطوط أنابيب التدريب ومهام التقييم وأنظمة جودة البيانات.
كما يعتمد أيضًا على تخزين الكائنات. وغالبًا ما تكون كائنات المصدر عبارة عن مقاطع فيديو أو صور أو ملفات PDF أو ملفات صوتية أو مستندات ويب تبقى في S3 أو GCS أو OSS أو مخزن كائنات آخر. تخزن قاعدة البيانات المراجع والبيانات الوصفية والميزات المشتقة والفهارس. ثم تضيف بعد ذلك أشياء لم تُصمم نماذج التخزين التقليدية لإدارتها ككائنات من الدرجة الأولى: التضمينات الكثيفة، والمتجهات المتناثرة، والتعليقات التوضيحية، وفهارس المتجهات، وفهارس النصوص، وسجلات الحذف، والإحصائيات، وإصدارات النماذج، وإصدارات المحلل، ومراجع النقط الخارجية، وعلاقات الإصدار بينها جميعًا.
هذا هو المكان الذي يبدأ فيه "مجرد إضافة عمود متجه" في الانهيار. لا تكمن المشكلة في ما إذا كان بإمكان قاعدة البيانات تخزين البايتات المتجهة. فالعديد من الأنظمة يمكنها ذلك. السؤال الأصعب هو ما إذا كان نموذج التخزين يمكنه التعامل مع كيفية تغير بيانات المتجهات، وكيفية الاستعلام عنها، وكيفية مشاركتها عبر مكدس بيانات الذكاء الاصطناعي.
لهذا السبب قمنا ببناء Loon، وهو محرك التخزين الجديد لـ Milvus و Zilliz Vector Lakebase (التطور التالي لـ Zilliz Cloud).
تم تصميم Loon بثلاث أفكار:
- استخدام تنسيقات مادية مختلفة لأنواع مختلفة من الأعمدة.
- محاذاة تلك الأعمدة من خلال مساحة معرف صف مشترك.
- استخدام بيان لتحديد حالة الإصدار لمجموعة البيانات.
لمعرفة سبب أهمية هذه الأجزاء، لنبدأ بسير عمل شائع متعدد الوسائط.
مجموعة البيانات المتجهة لا تنتهي أبدًا.
تخيل أن يقوم فريق الذكاء الاصطناعي بإنشاء مجموعة بيانات فيديو للتدريب متعدد الوسائط.
يتم تحميل مقطع فيديو طويل إلى مخزن الكائنات. يقوم خط أنابيب بتقطيعه إلى مقاطع بناءً على تغييرات المشهد أو حدود اللقطة أو النوافذ الزمنية. يتم تصفية المقاطع الطويلة جدًا أو القصيرة جدًا أو الضبابية أو المكررة أو منخفضة الجودة. يتم تسجيل المقاطع المتبقية بواسطة نموذج جمالي، ويتم تصنيفها بواسطة نموذج آخر، ويتم تضمينها بواسطة نموذج لغة الرؤية، ويتم تخزينها في قاعدة بيانات متجهة للبحث، واستخلاص البيانات المكررة وتصفية بيانات التدريب.
على مستوى عالٍ، يبدو سير العمل بسيطًا:
video
→ clips
→ metadata
→ aesthetic_score
→ caption
→ embedding
→ search / dedup / training data filtering
لكن مجموعة البيانات لا تصل مكتملة التكوين.
- في الأسبوع الأول، قد يحتوي الجدول فقط على
clip_idوvideo_idوstart_offsetوduration. - في الأسبوع الثاني، يضيف الفريق
aesthetic_score. - في الأسبوع الثالث، يتم تشغيل نموذج التضمين، ويحصل كل مقطع على
caption. - في الأسبوع الرابع، يتم تشغيل نموذج التضمين الأول، ويحصل كل مقطع على تضمين 768 بُعدًا من CLIP.
- وبعد مرور شهر، يقوم الفريق بتبديل النماذج وإعادة ملء
embedding_v2، والآن بأبعاد 1024. - بعد شهرين، يصبح البحث الهجين متطلبًا، لذا يضيف الفريق عمود متجه متناثر.
- بعد ثلاثة أشهر، تخضع التسميات التوضيحية للمراجعة البشرية ويجب تصحيحها في مكانها.
لم تكتمل مجموعة البيانات أبداً. وظلت تتراكم تفسيرات جديدة لنفس الصفوف الأساسية.
هذا هو أحد الاختلافات الأساسية بين بيانات المتجهات وبيانات الأعمال التقليدية. تتم إعادة معالجة الصف نفسه مرارًا وتكرارًا. ويحول الحجم هذا الأمر من مجرد إزعاج إلى مشكلة تخزين: فمجموعات البيانات متعددة الوسائط لا تكون في الغالب ملايين السجلات بل مئات الملايين أو المليارات. يُعتبر LAION-5B مرجعًا مفيدًا للشكل - مليارات من أزواج الصور والنصوص، كل منها مع بيانات وصفية وتعليقات توضيحية وتسميات توضيحية وتضمينات. لذا فإن الجزء الصعب ليس الإدراج الأول. الجزء الصعب هو كل ما يحدث بعد أن تبدأ مجموعة البيانات في التطور. هذا التطور يكشف ثلاث مشاكل.
المشكلة الأولى: الأعمدة الطويلة تجعل تضخيم الكتابة مكلفًا
تعتبر التنسيقات العمودية مثل Parquet ممتازة للعديد من أعباء العمل التحليلية. فهي تعمل بشكل جيد عندما تكون المخططات مستقرة إلى حد ما، وتتم قراءة البيانات أكثر من إعادة كتابتها، ولا تمس عمليات المسح إلا مجموعة فرعية من الأعمدة، ويكون الضغط مهمًا. هذا هو العالم الذي تم تحسين العديد من التنسيقات التحليلية من أجله.
صفوف المتجهات أوسع بكثير من الصفوف التحليلية
TPC-H lineitem هو خط أساس جيد. فهو يحتوي على 16 عمودًا: مفاتيح صحيحة وقيم عشرية وتواريخ وسلاسل قصيرة وحقل تعليق صغير. يبلغ حجم الصف الواحد غير المضغوط 150 بايت تقريبًا. بعد الضغط، قد يكون أصغر بكثير. مع مجموعة صفوف بسعة 64 ميغابايت، يمكن لنظام التخزين أن يحزم مئات الآلاف من الصفوف في مجموعة واحدة.
لا تبدو مجموعات البيانات المتجهة بهذا الشكل.
فمجموعة بيانات نص الصور على غرار LAION أقرب بكثير إلى ما تنتجه العديد من خطوط أنابيب الذكاء الاصطناعي اليوم. لا يزال كل صف يحتوي على بيانات وصفية عادية: عنوان URL، وتعليق، وعرض، وارتفاع، ودرجات جودة، وتسميات، وما إلى ذلك. ولكن بمجرد إضافة التضمين، يتغير الشكل المادي للصف.
يأخذ متجه CLIP ذو 768 بُعدًا حوالي 1.5 كيلوبايت في fp16 أو 3 كيلوبايت في fp32. يمكن أن يكون هذا العمود الواحد أكبر بكثير من صف TPC-H lineitem بأكمله.
وأبعاد 768 ليست غير عادية أو كبيرة بمعايير اليوم. يعد التضمين 1024 أو 2048 بعدًا شائعًا في خطوط الأنابيب متعددة الوسائط. أما OpenAI text-embedding-3-large الخاص بـ OpenAI فيرتفع إلى 3072 بُعدًا، أي حوالي 12 كيلوبايت لكل متجه في fp32.
المقارنة صارخة:
| شكل مجموعة البيانات | حجم الصف التقريبي | ما يهيمن على الصف |
|---|---|---|
| عنصر خط TPC-H | ~حوالي 150 بايت غير مضغوطة | الحقول العددية وحقول السلاسل القصيرة |
| صف على غرار صف LAION مع متجه fp16 بحجم 768 مليمتر | ~1.5 كيلوبايت تقريبًا | التضمين |
| صف بنمط LAION مع متجه fp32 بعمق 768 مليمتر | ~حوالي 3 كيلوبايت+ | التضمين |
| صف يحتوي على متجه fp32 بحجم 3072 مليمترًا | ~حوالي 12 كيلوبايت + للمتجه وحده | التضمين |
في العديد من مجموعات بيانات الذكاء الاصطناعي، لا يكون عمود المتجه مجرد حقل آخر. فيزيائيًا، هو معظم الصف. وهذا يغير تكلفة تطور المخطط.
يمكن أن تعني إضافة عمود متجه واحد مئات الجيجابايتات
لنفترض أن مجموعة البيانات تحتوي على 100 مليون مقطع فيديو. تعني إضافة عمود تضمين fp32 جديد بـ 1024 بُعدًا جديدًا كتابة ما يقرب من 400 جيجابايت من بيانات المتجهات الخام. لا يشمل ذلك الإحصائيات أو الفهارس أو تحديثات البيانات الوصفية أو نفقات تخزين الكائنات أو التحقق من الصحة أو تكامل مسار العرض.

إذا قام الفريق بإضافة عمود أو عمودين شبيهين بالمتجهات كل شهر، مثل embedding_v2 أو sparse_vector أو ميزات إعادة الترتيب، يصبح تطوير المخطط مهمة هندسة دايتا متكررة تقاس بمئات الجيجابايت أو التيرابايت.
يمكن أن تؤدي التحديثات المنطقية الصغيرة إلى عمليات إعادة كتابة مادية كبيرة
التحديثات بنفس القدر من الأهمية.
في الأنظمة العمودية، عادةً لا يتم تحديث البيانات القديمة في مكانها. يقوم سجل الحذف بتسجيل ما تم تغييره، ثم يقوم الضغط لاحقًا بإعادة كتابة الصفوف الحية في ملفات جديدة. يمكن إدارة هذا النموذج عندما تكون الصفوف صغيرة.
مع البيانات المتجهة، يمكن أن يؤدي التحديث المنطقي الصغير إلى إعادة كتابة فعلية كبيرة.
قد تقوم مهمة مراجعة بشرية بتصحيح بضع مئات البايت فقط في التسمية التوضيحية. ولكن إذا كانت التسمية التوضيحية والمتجه الكثيف والمتجه المتناثر والميزات المشتقة الأخرى تشترك في نفس دورة حياة الملف المادية، فقد ينتهي الأمر بالنظام إلى إعادة كتابة المتجهات أيضًا. التغيير المنطقي صغير. يمكن أن يكون الإدخال/الإخراج الفعلي ضخمًا.
هذه هي مشكلة تضخيم الكتابة في التخزين المتجه. الجزء المكلف ليس فقط أن المتجهات كبيرة. بل هو أن الحقول المشتقة الكبيرة والحقول الصغيرة القابلة للتغيير غالبًا ما يتم ربطها معًا من خلال تخطيط التخزين الذي يعاملها كوحدة واحدة.
بالنسبة لمجموعات بيانات الذكاء الاصطناعي، فإن الردم هو عبء عمل روتيني
بالنسبة للجداول التحليلية التقليدية، قد يحدث تطور المخطط من حين لآخر فقط. أما بالنسبة لمجموعات بيانات الذكاء الاصطناعي، فهو أمر روتيني. تتم ترقية نماذج التسمية التوضيحية. يتم استبدال نماذج التضمين. تتم إضافة متجهات متفرقة في وقت لاحق. تظهر ميزات إعادة التصنيف. يتم تصحيح التسميات البشرية. يتم ردم علامات الحكم. يتم إعادة بناء الفهارس.
هذه العمليات ليست إلحاقات بسيطة. فهي في كثير من الأحيان تعدل أو توسع الصفوف الموجودة.
هذا هو السبب في أن التخزين المتجه لا يمكنه تحسين إنتاجية المسح الضوئي فقط. يجب أيضًا أن يجعل عمليات الردم والتحديثات الجزئية أرخص.
المشكلة الثانية: يجب أن تدعم البيانات نفسها عمليات المسح والقراءات النقطية
بعد كتابة البيانات، ينقسم مسار القراءة. تحتوي مجموعة البيانات المتجهة نفسها عادةً على نمطي وصول متميزين: المسح التحليلي والقراءات النقطية.
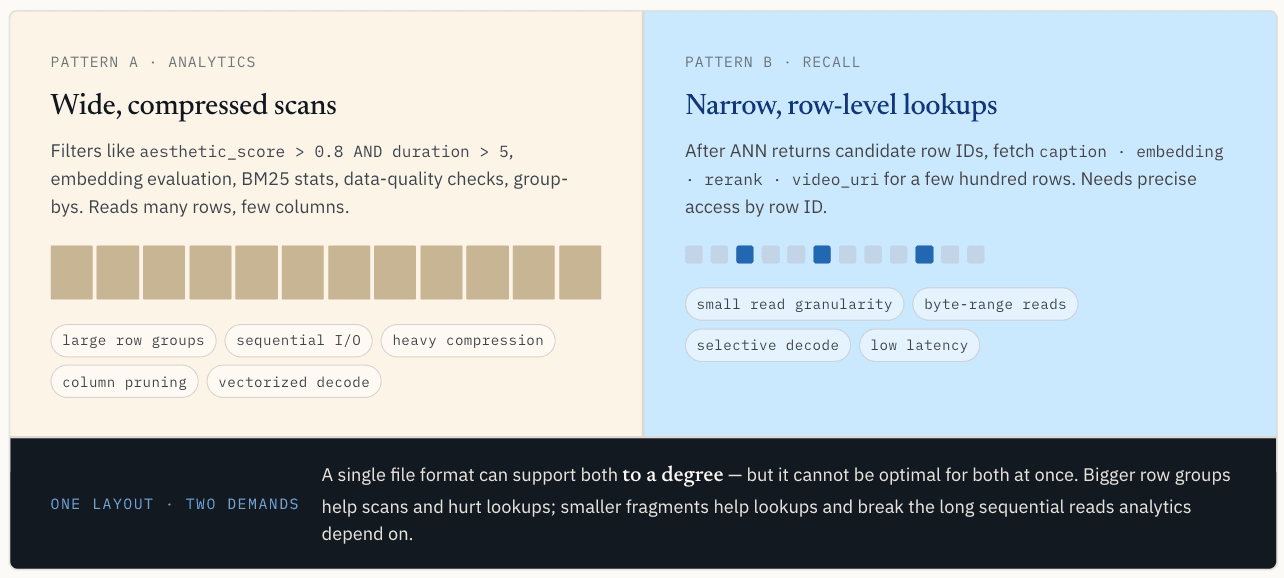
تريد أحمال العمل التحليلية عمليات مسح واسعة ومضغوطة
قد يقوم خط أنابيب بتشغيل مرشحات مثل:
WHERE aesthetic_score > 0.8 AND duration > 5
أو قد يقوم بتشغيل تحليل غير متصل بالإنترنت، وتقييم التضمين الكامل، وإحصائيات BM25، وبناء الصور النقطية، وفحص جودة البيانات، والتعداد، والتجميع.
يقرأ هذا النمط العديد من الصفوف ولكن أعمدة قليلة فقط. إنه يحب الإدخال/الإخراج المتسلسل، ومجموعات الصفوف الكبيرة، والضغط، وتشذيب الأعمدة، وفك التشفير على دفعات، والتنفيذ المتجه.
تساعد مجموعات الصفوف الكبيرة هنا. فهي تسمح لطلب إدخال/إخراج واحد بسحب كمية كبيرة من البيانات المفيدة، وتحسين كفاءة الضغط، وتزويد محرك التنفيذ ببيانات متجاورة كافية لاستهلاك النفقات العامة. عندما تتم قراءة أعمدة متعددة معًا، فإن الاحتفاظ بها منظمة من أجل إنتاجية المسح يساعد أيضًا في تقليل أخطاء ذاكرة التخزين المؤقت أثناء التنفيذ المتجه.
الباركيه قوي في هذا المسار.
تحتاج نتائج ANN إلى عمليات بحث ضيقة على مستوى الصفوف
بعد أن يُرجع بحث ANN معرّفات الصفوف المرشحة، يحتاج النظام غالبًا إلى جلب حقول مثل:
caption
embedding
rerank feature
video_uri
metadata
يقرأ هذا النمط عددًا أقل من الصفوف، غالبًا ما يكون بالمئات أو الآلاف، لكنه يحتاج إلى وصول دقيق حسب معرّف الصف. إنه يريد تحديد موقع صف وعمود محدد، وجلب نطاق البايت المطلوب فقط، وتجنب سحب مجموعة صفوف كاملة لمجرد استرداد عدد قليل من السجلات.
البحث النقطي لديه تفضيل معاكس تقريبًا للمسح الضوئي. فهو يريد دقة قراءة أصغر للقراءة. من الناحية المثالية، يمكن لطبقة التخزين العثور على المقطع أو نطاق البايت ذي الصلة حسب معرف الصف، وقراءة هذا النطاق فقط، وفك تشفير البيانات اللازمة للنتيجة فقط.
للضغط أيضًا مقايضة مختلفة. بالنسبة لعمليات المسح الضوئي، غالبًا ما يكون الضغط الثقيل يستحق العناء لأن النظام يقرأ الكثير من البيانات ويحفظ الإدخال/الإخراج. بالنسبة للبحث عن النقاط، يمكن أن يصبح الضغط عائقًا إذا كان استرداد صف واحد يتطلب فك تشفير كتلة مضغوطة أكبر بكثير.
لا يمكن تحسين تخطيط واحد لكلا المسارين
هذا هو التعارض الأساسي. تريد التصفية والتحليلات العددية تخطيطات عريضة ومضغوطة وملائمة للمسح الضوئي. أما البحث عن المتجهات فيريد تخطيطات ضيقة ودقيقة وقابلة للعنونة للصفوف.
يمكن أن يدعم تنسيق ملف واحد كلاهما إلى حد ما، ولكن لا يمكن أن يكون الأمثل لكليهما في وقت واحد.
إذا كانت جميع الأعمدة تعيش في Parquet، فإن عمليات المسح القياسي مريحة. ولكن يصبح البحث عن ANN بعد الاستدعاء أصعب. قد يحتاج النظام إلى بضع مئات من المتجهات أو التسميات التوضيحية أو سجلات البيانات الوصفية فقط، بينما قد تضطر طبقة التخزين إلى قراءة مجموعات صفوف كبيرة تحتوي في الغالب على صفوف غير ذات صلة.
على SSD المحلي، يمكن أن تخفي ذاكرة التخزين المؤقت و mmap جزءًا من هذه التكلفة. بمجرد تخزين البيانات في تخزين الكائنات، تصبح التكلفة أكثر وضوحًا. يمكن أن تصبح كل عملية تفويت لذاكرة التخزين المؤقت قراءة نطاق بعيد. إذا كانت الصفوف المرشحة مبعثرة عبر العديد من مجموعات الصفوف، يمكن أن يؤدي استعلام واحد إلى قراءات متعددة، كل منها يسحب بيانات أكثر مما يحتاجه الاستعلام. في تخطيط رديء التصميم، يمكن أن يؤدي جلب 1000 صف مرشح بسهولة إلى عشرات أو مئات الميغابايت من الإدخال/الإخراج غير الضروري، وفي الحالات القصوى، أكثر من ذلك بكثير.
جعل مجموعات الصفوف أصغر يساعد في البحث عن النقاط، لكنه يضر بعمليات المسح. فالكثير من الأجزاء الصغيرة جدًا تقلل من كفاءة الضغط، وتزيد من عبء البيانات الوصفية الزائد، وتكسر القراءات المتسلسلة الطويلة التي تعتمد عليها المحركات التحليلية.
لذا فإن المشكلة لا تتعلق بإيجاد حجم مجموعة صفية سحرية واحدة. المشكلة هي أنه يُطلب من نفس مجموعة البيانات أن تتصرف مثل نظامي تخزين مختلفين.
يفرض البحث الهجين كلا المسارين في استعلام واحد
البحث الهجين يجعل من الصعب تجاهل التعارض. قد يطبق استعلام واحد أولاً مرشحات قياسية:
aesthetic_score > 0.8 AND duration > 5
ثم يقوم بتشغيل بحث ANN.
ثم يجلب التسمية التوضيحية والمتجه والبيانات الوصفية حسب معرف الصف.
بالنسبة للمستخدم، يعد هذا طلب بحث واحد. أما بالنسبة لطبقة التخزين، فهو عبارة عن مسح تحليلي وبحث عشوائي منخفض الكمون.
لهذا السبب يحتاج تخزين المتجهات إلى أكثر من إعداد باركيه أفضل. فهو يحتاج إلى طريقة لوضع الأعمدة المختلفة وفقًا لكيفية قراءتها فعليًا.
المشكلة الثالثة: مجموعة البيانات لا تعيش داخل محرك واحد
تحدث المشكلتان الأوليان داخل قاعدة البيانات. أما الثالثة فتحدث عند الحدود بين الأنظمة.

تمتد خطوط أنابيب بيانات الذكاء الاصطناعي عبر العديد من الأنظمة
في سير عمل الفيديو، يحدث القليل جدًا داخل قاعدة بيانات المتجهات نفسها.
تعيش مقاطع الفيديو الخام في تخزين الكائنات. قد يعمل توليد المقاطع في Spark أو Ray. قد يتم تشغيل التسجيل الجمالي في خدمة وحدة معالجة الرسومات. قد يتم تشغيل التسميات التوضيحية في خط استدلال LLM. قد يتم إنشاء التضمينات بواسطة مهمة وحدة معالجة رسومات أخرى. قد تأتي المتجهات المتفرقة من خدمة SPLADE. قد يتم تشغيل كل من التقييم دون اتصال بالإنترنت، وتصفية بيانات التدريب، والمراجعة البشرية، ووظائف الحوكمة في مكان آخر.
تخدم قاعدة بيانات المتجهات البحث عبر الإنترنت، ولكن يتم إنتاج مجموعة البيانات وتصحيحها وتقييمها وتوسيعها بواسطة العديد من الأنظمة.
تنشئ تنسيقات التخزين الخاصة نسخًا متعددة من الحقيقة
إذا كانت قاعدة البيانات تستخدم تنسيقًا ماديًا خاصًا لا يمكن لغيرها قراءته وكتابته، فإن كل مهمة خارجية تحتاج إلى تصدير وتحويل ونسخة واستيراد. قد توجد نفس المجموعة في قاعدة البيانات، وفي دليل Spark المؤقت، وفي مخرجات التقييم، وفي دليل الردم المحلي. ثم يصبح السؤال الحقيقي
- أي نسخة هي مصدر الحقيقة؟
- أيهما يحتوي على نموذج التسمية التوضيحية من الشهر الماضي؟
- ما هي الصفوف التي تم تصحيحها بالفعل عن طريق المراجعة البشرية؟
- أي عمود متجه متناثر تم إنشاؤه بواسطة أي نموذج؟
- ما مؤشر المتجه الذي لا يزال صالحًا بعد الردم؟
- ما هو كائن الفيديو الأصلي الذي يشير إليه هذا الصف؟
على نطاق صغير، يمكن للفرق في بعض الأحيان البقاء على قيد الحياة مع اصطلاحات التسمية والمراجعات اليدوية. مع وجود مئات الملايين من الصفوف وتيرابايت من التضمينات، يصبح هذا مشكلة اتساق.
تحتاج مجموعات البيانات المتجهة إلى حالة إصدار مشتركة
عالجت أنظمة ليكهاوس نسخة من هذه المشكلة للبيانات المهيكلة. لا تتعلق أنظمة Iceberg و Delta Lake و Hudi بتخزين الملفات فقط. مساهمتهم الأساسية هي السماح لمحركات متعددة بالتنسيق حول نفس حالة الجدول.
تحتاج قواعد البيانات المتجهة الآن إلى قدرة مماثلة، لكن الحالة أكثر تعقيدًا. يجب أن تتضمن ليس فقط ملفات الجداول والأقسام، ولكن أيضًا فهارس المتجهات، والفهارس النصية، والميزات المتفرقة، وسجلات الحذف، والإحصائيات، ونطاقات معرفات الصفوف، والمراجع إلى النقط الخارجية.
السؤال ليس ببساطة "هل يمكن لسبارك قراءة ملفات ميلفوس؟
السؤال هو، بعد أن يقوم Spark بإعادة ملء عمود متجه متناثر، كيف يعرف Milvus الإصدار الذي ينتمي إليه هذا العمود، والصفوف التي يغطيها، والنموذج الذي أنتجه، ومتى يمكن للاستعلامات عبر الإنترنت استخدامه بأمان؟
يجب أن تكون الإجابة موجودة في نموذج التخزين.
لماذا لا تكفي التصحيحات
من المغري أن نتعامل مع هذه المشاكل على أنها ثلاث مشاكل هندسية منفصلة.
- تضخيم الكتابة؟ إضافة التجميع.
- قراءة النقاط؟ أضف ذاكرة تخزين مؤقت.
- أنظمة خارجية؟ أضف أدوات التصدير والاستيراد.
يمكن لهذه التصحيحات أن تساعد، لكنها لا تعالج المشكلة الأساسية: مجموعة البيانات المتجهة غير متجانسة ماديًا.

في مثال الفيديو، clip_id و video_id و duration و aesthetic_score هي حقول قياسية قصيرة. وهي مفيدة للتصفية والتحليل.
captionهو نص. يمكن استخدامها في BM25 والمراجعة والتصحيح والردم.embeddingهو متجه طويل وكثيف. يتم استخدامه لاستدعاء الشبكة العصبية الاصطناعية ولاحقًا للبحث على مستوى الصف أو إعادة الترتيب.embedding_v2هو ناتج نموذج جديد، وغالبًا ما يتم ردمه بعد فترة طويلة من إدراج البيانات الأصلية.sparse_vectorيدعم البحث الهجين وله نمط وصول خاص به.- يجب أن يبقى الفيديو الخام في مخزن الكائنات. يجب أن تخزّن قاعدة البيانات مرجعًا، ومجموعًا اختباريًا، ونوع MIME، وإصدارًا للمحلل وعلاقة على مستوى الصف.
- فهارس المتجهات، والفهارس النصية، والإحصائيات، وسجلات الحذف هي كائنات مشتقة لها دلالات الإصدار الخاصة بها.
تشترك هذه الكائنات في صف منطقي، ولكن لا ينبغي أن تشترك جميعها في نفس التخطيط المادي أو دورة الحياة.
- إذا تم إجبارهم على تخطيط جدول عادي واحد، تصبح التحديثات مكلفة.
- إذا تم إجبارهم على تنسيق ملف عمودي واحد، تصبح قراءات النقاط مكلفة.
- إذا تم التعامل معها كملفات كائنات غير مرتبطة، تصبح إدارة الإصدارات هشة.
لذا يجب أن يبدأ نموذج التخزين من حقيقة أن مجموعة البيانات غير متجانسة.
وهذا يؤدي إلى ثلاثة متطلبات تصميم:
- أولاً، يجب تخزين مجموعات الأعمدة المختلفة في تنسيقات مادية مختلفة.
- ثانيًا، تحتاج مجموعات الأعمدة هذه إلى مساحة معرف صف مشترك، بحيث يمكن أن تظل تتصرف كجدول منطقي واحد.
- ثالثًا، تحتاج مجموعة البيانات إلى بيان إصداري يوضح الملفات والفهارس والسجلات والإحصائيات ومراجع الكائنات التي تنتمي إلى طريقة العرض الحالية.
هذا هو التصميم الكامن وراء Loon، محرك التخزين الجديد وراء Milvus وZilliz Cloud.
Loon: محرك تخزين وراء Milvus وZilliz Cloud لمجموعات البيانات المتجهة المتطورة
لحل جميع المشاكل المذكورة أعلاه، قمنا ببناء Loon، وهو محرك التخزين الجديد لميلفوس وزيليز فيكتور ليكبيز (التطور التالي لزيليز كلاود)، المصمم لمجموعات البيانات المتجهة المتطورة.
يتبع الاسم تقليد تسمية الطيور في زيليز. طائر البجعة هو طائر غواص يعيش على البحيرات، وهو ما يتوافق بشكل جيد مع هدف النظام: يجب ألا تضطر قاعدة البيانات المتجهة إلى نقل أو مسح أو إعادة كتابة بحيرة كاملة من البيانات في كل مرة تقوم فيها بتشغيل استعلام أو إعادة ملء عمود أو إنشاء فهرس. يجب أن تفهم أولاً إصدار مجموعة البيانات الحالية، بما في ذلك أعمدتها وفهارسها وإحصائياتها وسجلات الحذف ومراجع الكائنات، ثم تقرأ فقط الجزء الذي تحتاجه بالفعل.
تنسيقات الملفات المختلطة ومحاذاة معرّف الصفوف والبيان ليست ثلاث ميزات منفصلة. فهي تنبع من نفس افتراض التصميم: مجموعة البيانات المتجهة غير متجانسة بطبيعتها.
ثلاث قطع، نموذج تخزين واحد
تقر تنسيقات الملفات المختلطة بأن الأعمدة المختلفة لها أنماط وصول مختلفة. الحقول العددية جيدة للمسح والتصفية. تحتاج الحقول المتجهة إلى بحث فعال على مستوى الصفوف. الكائنات الخام مثل مقاطع الفيديو وملفات PDF والصور والملفات الصوتية تنتمي إلى تخزين الكائنات، وليس داخل ملفات بيانات قاعدة البيانات.
تقر محاذاة معرف الصف بأن هذه الأعمدة قد تكون منفصلة ماديًا، لكنها لا تزال تصف نفس الصفوف المنطقية. قد توجد التسمية التوضيحية والتضمين والمتجه المتناثر و URI للفيديو في ملفات وتنسيقات مختلفة، ولكن لا يزال يتعين جمعها معًا كنتيجة واحدة.
يقر البيان بأن مجموعة البيانات لا تُكتب مرة واحدة وتُترك وحدها. سيتم تعديلها بواسطة أنظمة متعددة، عبر إصدارات متعددة، لمهام متعددة. يجب أن تظهر كل من الفهارس والإحصائيات وسجلات الحذف ومراجع الكائنات الخارجية ومجموعات الأعمدة في نفس طريقة العرض التي تم إصدارها.
هذا هو السبب في أن Loon ليس مجرد تنسيق ملف متجه أسرع. يساعد التنسيق الأسرع في البحث عن النقاط، لكنه لا يحل مشكلة تطور المخطط أو التنسيق متعدد المحركات. تتيح محاذاة معرّف الصفوف محاذاة الأعمدة المنقسمة للعمل كجدول واحد، لكنها لا تحدد الملفات التي تنتمي إلى الإصدار الحالي. يمكن للبيان أن يصف حالة مجموعة البيانات، ولكن بدون مجموعات الأعمدة ومحاذاة معرّف الصفوف، لا يمكن أن يمثل بشكل نظيف تخطيطات مادية مختلفة داخل مجموعة منطقية واحدة.
يحتاج نموذج التخزين إلى الثلاثة جميعًا: تنسيقات مختلفة لمجموعات الأعمدة المختلفة، ومساحة معرف صف مشترك لإعادة بناء الصفوف، وبيان بإصدار يخبر كل قارئ وكاتب ما هي مجموعة البيانات حاليًا.
حيث يتناسب لون مع قاعدة بيانات ميلفوس وزيليز فيكتور ليكبيز
في Milvus، يستبدل طبقة التخزين القديمة ذات السجل المقطعي بنموذج مبني حول Manifest و ColumnGroup وتنسيق الملف وتجريدات نظام الملفات. في Zilliz Vector Lakebase (التطور التالي لـ Zilliz Cloud)، ينطبق نفس الاتجاه على بنية Vector Lakebase: الحفاظ على مسار خدمة قاعدة بيانات المتجهات سريعًا مع تسهيل تطوير البيانات الأساسية وتحليلها والتنسيق مع الأنظمة الخارجية.
لا تزال مكونات المستوى الأعلى من ميلفوس تحتفظ بأدوارها المألوفة. يتعامل الوكيل مع التوجيه. يتعامل QueryCoord و DataCoord مع الجدولة. تقوم IndexNode ببناء الفهارس. لا تحتاج واجهات برمجة التطبيقات التي تواجه التطبيق للمجموعات والإدخالات وعمليات البحث وعمليات البحث المختلطة إلى كشف ملفات البيان أو مجموعات الأعمدة.
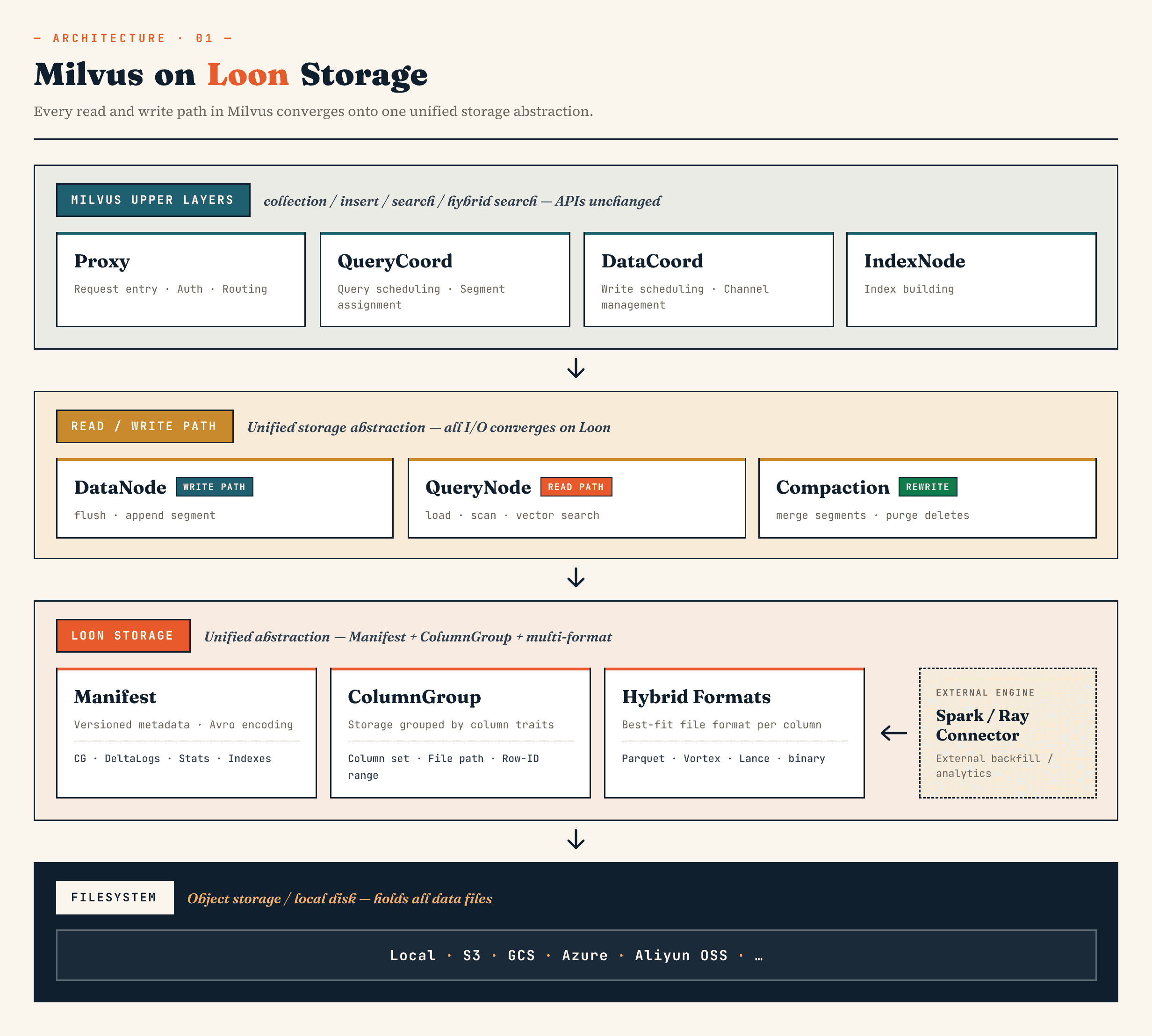
التغيير في الأسفل.
يمكن أن تعمل DataNode وQueryNode وSegcore وSgcore والضغط والموصلات الخارجية من خلال نفس تجريد التخزين. هذا مهم لأن مجموعة البيانات لم تعد تُكتب وتُقرأ فقط بواسطة قاعدة البيانات. فقد يتم توسيعها بواسطة أنظمة الحوسبة الخارجية واستهلاكها بواسطة البحث عبر الإنترنت في وقت واحد.
على مستوى عالٍ، تبدو الطبقات على هذا النحو:
Manifest
→ ColumnGroup
→ file format layer
→ filesystem abstraction
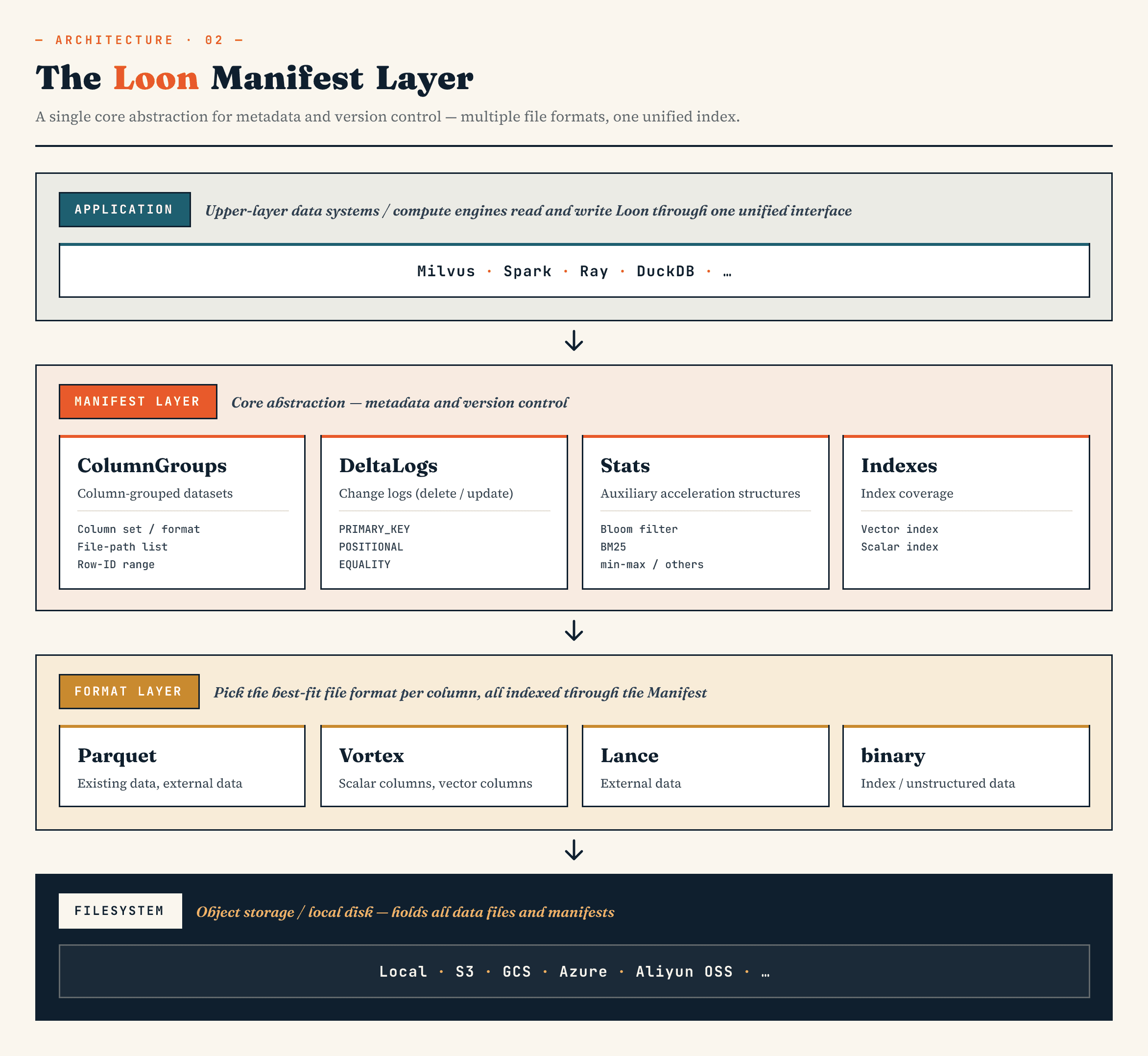
يصف البيان حالة الإصدار لمجموعة البيانات. تقوم مجموعات الأعمدة بتعيين مجموعة منطقية إلى مجموعات فعلية من الأعمدة. تتيح طبقة تنسيق الملف لكل مجموعة أعمدة اختيار التنسيق المناسب. يعمل تجريد نظام الملفات عبر تخزين الكائنات والتخزين المحلي.
النقطة المهمة هي أن تنسيقات الملفات المختلطة ومحاذاة معرف الصفوف والبيان ليست ميزات منفصلة. فهي تحدد معًا نموذج التخزين.
مع وضع هذا النموذج في مكانه، يمكننا النظر إلى خيارات التصميم الثلاثة واحدًا تلو الآخر: كيف يخزن Loon مجموعات الأعمدة المختلفة، وكيف يقوم بمحاذاة هذه الملفات في صفوف، وكيف يحول البيان هذه الملفات إلى مجموعة بيانات ذات إصدارات.
التصميم 1: استخدام تنسيق الملف الصحيح لمجموعة الأعمدة الصحيحة
الأعمدة المختلفة لها أنماط وصول مختلفة. لا ينبغي إجبارهم على نفس تنسيق الملف.
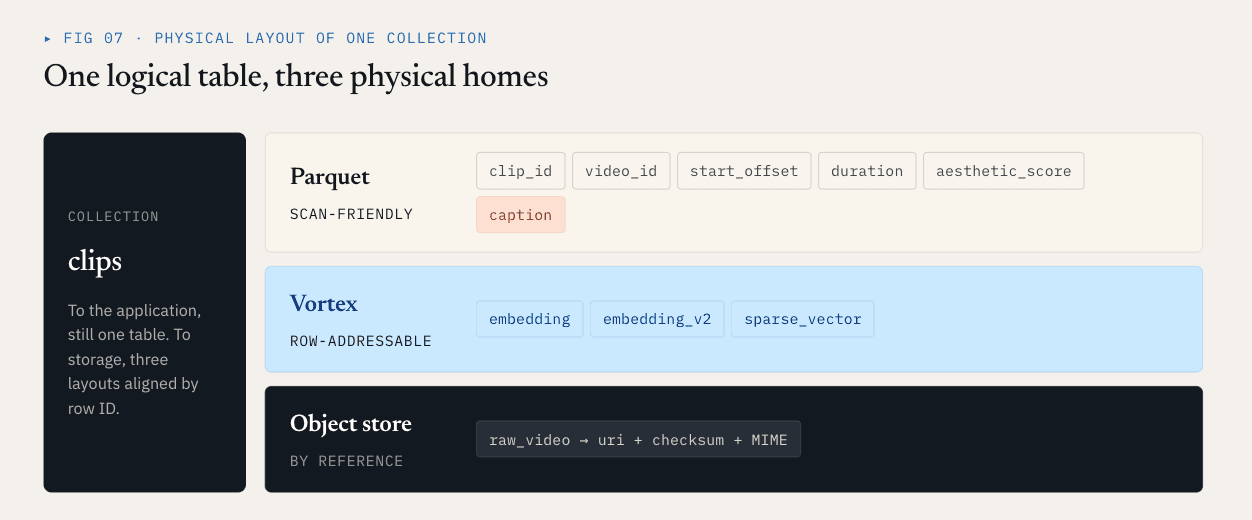
يقسم Loon مجموعة منطقية إلى مجموعات أعمدة.
- غالبًا ما يتم مسح الحقول العددية وحقول التصفية ومفاتيح العمل والحقول الإحصائية أو تصفيتها أو تجميعها أو استخدامها لتخطيط الاستعلام. وهي تستفيد من الضغط وتشذيب الأعمدة وتوافق النظام البيئي. يعد الباركيه مناسبًا جيدًا لهذه الأعمدة.
- غالبًا ما تتم قراءة المتجهات الكثيفة والمتجهات المتناثرة وميزات إعادة الترتيب بعد استدعاء الشبكة الوطنية حسب معرف الصف. وهي تحتاج إلى وصول عشوائي منخفض التأخير، وقراءات دقيقة على نطاق البايت، وفك تشفير انتقائي. يعد التخطيط الموجه للقطعة مناسبًا بشكل أفضل. يستخدم Loon Vortex في هذا الاتجاه.
- يجب عدم تضمين الكائنات الأولية مثل مقاطع الفيديو وملفات PDF والصور والملفات الصوتية في ملفات بيانات قاعدة البيانات المتجهة. يجب أن تبقى في تخزين الكائنات. تسجل قاعدة البيانات المراجع، والمجموعات الاختبارية، وأنواع MIME، وإصدارات المحلل، والعلاقات على مستوى الصفوف.
بالنسبة لمثال الفيديو، قد يبدو التخطيط الفعلي هكذا:
Parquet ColumnGroup:
clip_id / video_id / start_offset / duration / aesthetic_score / caption
Vortex ColumnGroups:
embedding
embedding_v2
sparse_vector
Object storage:
raw video objects
بالنسبة للتطبيق، لا تزال هذه مجموعة واحدة. بالنسبة لطبقة التخزين، تستخدم أجزاء مختلفة من تلك المجموعة تنسيقات مادية مختلفة. هذا يقلل بشكل مباشر من عمليات إعادة الكتابة غير الضرورية. إضافة embedding_v2 يمكن أن تصبح إضافة مجموعة أعمدة متجهة جديدة بالإضافة إلى التزام بيان. ولا يتطلب ذلك إعادة كتابة عمود التسمية التوضيحية أو البيانات الوصفية العددية أو عمود التضمين الموجود.
تنطبق الفكرة نفسها على المتجهات المتفرقة أو ميزات إعادة الترتيب أو الحقول المشتقة الأخرى. إذا كان من الممكن أن يكون العمود الجديد مستقلاً فعليًا ومحاذاة حسب معرّف الصف، فلا داعي لسحب الأعمدة غير المرتبطة من خلال نفس مسار إعادة الكتابة.
يقوم Loon أيضًا بتكييف استخدام تنسيقات الملفات.
بالنسبة للباركيه، فإن الإعدادات الافتراضية ليست دائماً مثالية للبيانات ذات المتجهات الثقيلة. يمكن أن تكون مجموعة الصفوف سعة 64 ميغابايت كبيرة جدًا للبحث عن النقاط لأن القراءة العشوائية الصغيرة قد تسحب بيانات أكثر بكثير مما هو مطلوب. يقوم Loon بتشديد مجموعات الصفوف إلى 1 ميغابايت في المسارات ذات الصلة وتعطيل الترميزات، مثل ترميز القاموس على أعمدة المتجهات، عندما لا تساعد بيانات المتجهات ذات المظهر العشوائي.
بالنسبة لـ Vortex، العمل الأكثر أهمية هو التخطيط. يستخدم Loon تخطيطًا يوازن بين كفاءة المسح الضوئي والبحث عن النقاط. ضمن مجموعة صفوف، يمكن وضع المقاطع من الأعمدة ذات الصلة بالقرب من بعضها البعض لدعم المسح الضوئي. لإجراء العمليات، تسمح قراءات المقاطع الفرعية للنظام بجلب البايتات ذات الصلة فقط بدلاً من سحب مقطع كامل.
يدعم Loon أيضًا تكامل Lance للقراءة فقط، بحيث يمكن تركيب مجموعات بيانات Lance الحالية كمجموعات أعمدة عندما يكون التوافق مهمًا.
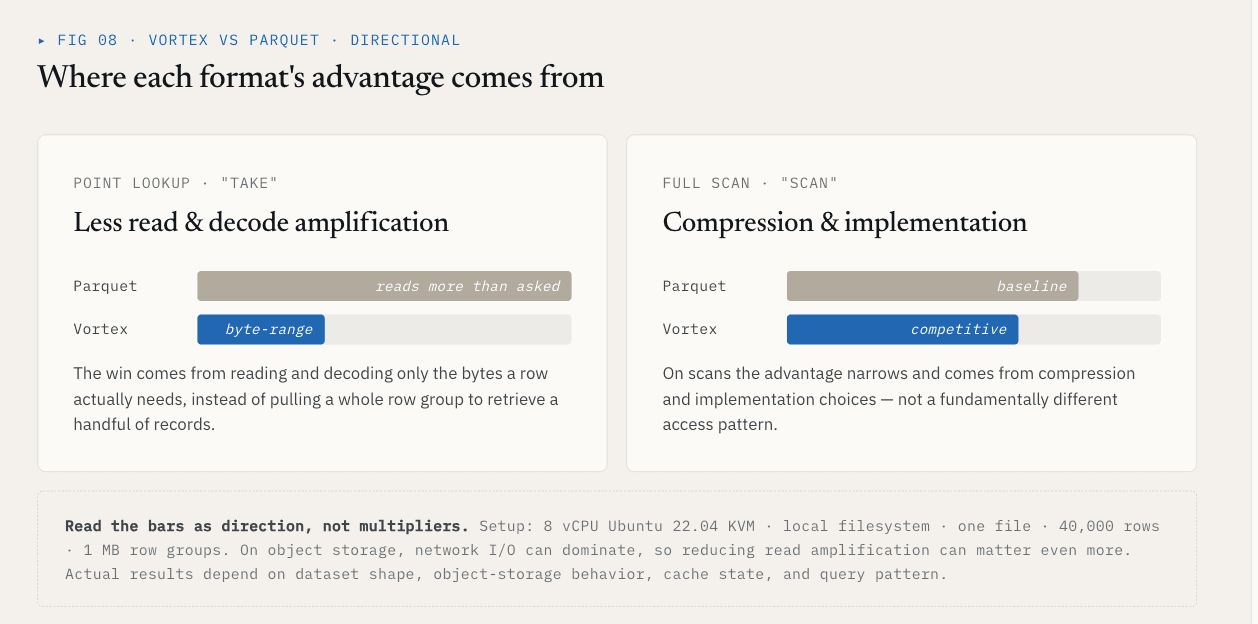
ما يظهره المعيار
في اختبار محلي واحد، باستخدام ملف واحد يحتوي على 40,000 صف ومخطط {id: int64, name: utf8, value: float64, vector: list<float32>[128]} ، أظهر Vortex هذه النتائج مقابل Parquet مع مجموعات صفوف بسعة 1 ميغابايت:
| العملية | فورتكس | الباركيه | الفرق |
|---|---|---|---|
| خذ، K=1000 صف عشوائي | 5.8 مللي ثانية | 144 مللي ثانية | أسرع 25 مرة |
| مسح عمود متجه كامل | 21 مللي ثانية | 142 مللي ثانية | 6.76 مرة أسرع |
| حجم الملف، حوالي 21 ميغابايت من البيانات الأولية | 6.62 ميغابايت | 7.16 ميغابايت | أصغر بنسبة 7% |
تأتي نتيجة take من تقليل كمية البيانات غير ذات الصلة التي يجب قراءتها وفك تشفيرها. وتأتي نتيجة المسح من خيارات الضغط والتنفيذ.
يجب أن تظل هذه الأرقام مرتبطة بإعدادها: 8 وحدات vCPU Ubuntu 22.04 KVM، نظام ملفات محلي، ملف واحد، 40,000 صف، مجموعات صفوف 1 ميغابايت، والمخطط أعلاه. على تخزين الكائن، يمكن أن يهيمن الإدخال/الإخراج على الشبكة، لذا فإن تقليل تضخيم القراءة يمكن أن يكون أكثر أهمية. تعتمد النتائج الفعلية على شكل مجموعة البيانات وسلوك تخزين الكائنات وحالة ذاكرة التخزين المؤقت ونمط الاستعلام.
النقطة الأوسع ليست أن كل عمود يجب أن يستخدم Vortex.
النقطة المهمة هي أن مجموعات البيانات المتجهة تحتاج إلى اختيار تنسيق الملف على مستوى ColumnGroup.
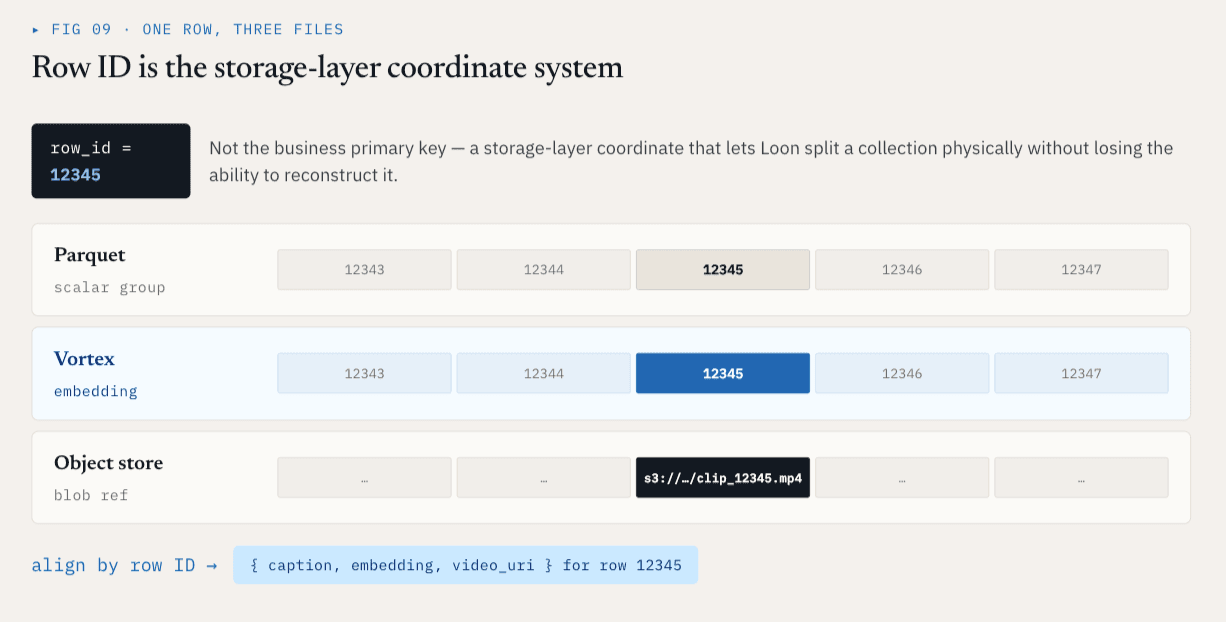
التصميم 2: محاذاة الملفات الفعلية من خلال معرفات الصفوف
تعمل تنسيقات الملفات الهجينة على حل مشكلة واحدة: يمكن للأعمدة المختلفة الآن أن تعيش في التنسيقات التي تناسبها بشكل أفضل.
لكن هذا يخلق مشكلة ثانية. إذا كانت الحقول القياسية تعيش في Parquet، والمتجهات تعيش في Vortex، والكائنات الخام تعيش في مخزن الكائنات، فكيف يستمر النظام في التعامل معها كمجموعة واحدة؟
يحل Loon هذه المشكلة بمحاذاة معرف الصف.
مُعرِّف الصف هو نظام إحداثيات طبقة التخزين
كل ملف ColumnGroupFile فعلي يسجل مسار الملف ونطاق معرف الصف الذي يغطيه:
path
start_index
end_index
يمكن أن تغطي مجموعات الأعمدة المختلفة نفس مساحة معرف الصف حتى لو كانت موجودة في ملفات وتنسيقات مختلفة.
بالنسبة لمعرّف الصف 12345 ، قد تكون البيانات الوصفية القياسية في مجموعة أعمدة باركيه، وقد يكون التضمين في مجموعة أعمدة Vortex، وقد يتم تمثيل الفيديو الخام بواسطة مرجع تخزين كائن. منطقيًا، لا يزالان صفًا واحدًا. هذا يعطي طبقة التخزين نظام إحداثيات ثابت.
معرف الصف ليس المفتاح الأساسي للعمل. إنه نظام إحداثيات طبقة التخزين الذي يسمح لـ Loon بتقسيم مجموعة ما فعليًا دون فقدان القدرة على إعادة بنائها منطقيًا.
لا يتعين على الأعمدة الجديدة إعادة كتابة الأعمدة القديمة
لا تتطلب إضافة embedding_v2 إعادة كتابة التسمية التوضيحية الأصلية أو البيانات الوصفية أو embedding_v1 ColumnGroups. يمكن لـ Loon كتابة مجموعة أعمدة متجهة جديدة، وتسجيل نطاق معرف الصف الذي يغطيه، والتزام هذا التغيير من خلال البيان.
ينطبق الأمر نفسه على المتجهات المتفرقة أو ميزات إعادة الترتيب أو الحقول المشتقة الأخرى التي تصل لاحقًا.
ما دامت مجموعة الأعمدة الجديدة تغطي نطاق معرّف الصف الصحيح، فيمكنها الانضمام إلى نفس المجموعة المنطقية دون إجبار البيانات غير ذات الصلة على الانتقال.
يمكن أن تكون عمليات الحذف والضغط أكثر استهدافًا
تساعد محاذاة معرف الصف أيضًا في عمليات الحذف.
يمكن التعبير عن الحذف أولاً من خلال سجل الحذف. يصبح الصف غير مرئي على المستوى المنطقي، بينما يتأخر التنظيف المادي حتى يتم الضغط. عندما يعمل الضغط في النهاية، لا يحتاج دائمًا إلى إعادة كتابة كل مجموعة أعمدة مرتبطة بالصفوف المتأثرة. يمكنه التركيز على مجموعات الأعمدة التي تحتاج إلى التنظيف.
هذا مهم لأنه ليس لكل عمود نفس ملف تعريف التكلفة. تختلف إعادة كتابة مجموعة أعمدة عمودية قصيرة قياسية عن إعادة كتابة مئات الجيجابايت من المتجهات الكثيفة.
يمكن للبحث الهجين جلب الأعمدة التي يحتاجها فقط
محاذاة معرّف الصف هو أيضًا ما يجعل البحث المختلط عمليًا فوق تنسيقات الملفات المختلطة.
بعد أن يقوم البحث الهجين بإرجاع معرّفات الصفوف المرشحة، يمكن للنظام جلب الحقول اللازمة للنتيجة النهائية فقط: التسميات التوضيحية أو البيانات الوصفية أو المتجهات أو ميزات إعادة الترتيب أو مراجع الكائنات.
على سبيل المثال، قد يحتاج الاستعلام:
caption
embedding
video_uri
قد تعيش هذه الحقول في مجموعات أعمدة مختلفة. يمكن لـ Loon تحديد موقع الملفات ذات الصلة حسب نطاق معرف الصف، وقراءة نطاقات البايت اللازمة، وتجميع النتيجة.
بدون محاذاة معرّف الصف، ستكون التنسيقات المختلطة مجرد ملفات منفصلة موضوعة جنباً إلى جنب. مع محاذاة معرف الصف، فإنها تتصرف كمجموعة منطقية واحدة.
يخفي القارئ المجمّع التقسيم من الطبقة العليا
مكون وقت التشغيل الذي يجعل هذا قابلاً للاستخدام هو القارئ المعبأ.
ترى الطبقة العليا دفقًا موحدًا لـ Arrow RecordBatch. في الأسفل، قد تأتي البيانات من مجموعات أعمدة متعددة بتنسيقات ملفات مختلفة. يخفي القارئ المعبأ هذه الاختلافات، ويقوم بمحاذاة البيانات حسب نطاقات معرف الصف، ويجدول الإدخال/الإخراج متعدد الملفات مع التحكم في استخدام الذاكرة.
كما أنه يدعم أيضًا take المباشر حسب معرّف الصف. وبالنظر إلى مجموعة من معرّفات الصفوف، فإنه يحدد موقع ملفات ColumnGroupFiles ذات الصلة، ويصدر قراءات النطاق، ويعيد الحقول المطلوبة.
بالنسبة لسير عمل الفيديو، قد يحتاج استعلام ANN إلى caption و embedding و video_uri. يمكن للقارئ المعبأ أن يجلب مجموعة الأعمدة القياسية ومجموعة الأعمدة المتجهة دون لمس الأعمدة غير ذات الصلة.
هذا هو الفرق بين "الملفات المنفصلة" و "جدول بتخطيطات مادية متعددة".
التصميم 3: جعل البيان مصدر الحقيقة
تحدد تنسيقات الملفات المختلطة كيفية تخزين البيانات فعليًا. تحدد محاذاة معرف الصف كيف تظل مجموعات الأعمدة المنفصلة تشكل جدولًا منطقيًا واحدًا. ولكن لا يزال النظام بحاجة إلى الإجابة عن سؤال أكبر: ما هي الملفات والسجلات والإحصائيات والفهارس ومراجع الكائنات التي تنتمي إلى الإصدار الحالي من مجموعة البيانات؟ هذه هي مهمة البيان.

دلائل تخزين الكائنات ليست كافية
تخزين الكائنات ليس كتالوج قاعدة البيانات. قد يحتوي الدليل على ملفات قديمة وملفات جديدة ومخرجات مهام فاشلة وملفات مؤقتة وسجلات حذف وملفات لا يزال يُشار إليها بواسطة لقطات قديمة وملفات تنتظر التنظيف. لا تعني حقيقة وجود ملف ما أنه ينتمي إلى إصدار مجموعة البيانات الحالي.
قد يتم تنظيم مجموعة بيانات Loon في دلائل مثل:
_metadata/
_data/
_delta/
_stats/
_index/
لكن بنية الدليل ليست مصدر الحقيقة. البيان هو مصدر الحقيقة. يجب على القراء عدم سرد الدلائل واستنتاج الحالة من أي ملفات تصادف وجودها. يجب عليهم قراءة البيان الحالي واتباع طريقة عرض الإصدار التي يعلنها.
يعرّف البيان طريقة عرض نسخة واحدة من مجموعة البيانات
يحدد البيان مجموعة البيانات في إصدار معين. وهو يسجّل
- مجموعات الأعمدة الموجودة
- نطاقات معرّفات الصفوف التي تغطيها
- التنسيق الفعلي الذي تستخدمه كل مجموعة أعمدة
- مكان وجود الملفات
- سجلات الحذف النشطة
- ما هي الإحصائيات المتوفرة
- الفهارس الموجودة
- أي النقط الخارجية المشار إليها
- أي الأعمدة ونطاقات الصفوف التي تغطيها تلك الإحصائيات أو الفهارس
كل تحديث يكتب إصدار بيان جديد. القارئ الذي يفتح الإصدار N يرى عرضًا ثابتًا لمجموعة البيانات في الإصدار N. يمكن للكاتب إعداد الإصدار N+1 دون تعطيل القراء الذين لا يزالون يستخدمون الإصدار N.
يتتبع البيان أكثر من ملفات الجداول
في Loon، يتم ترميز نص البيان باستخدام Apache Avro ويتم تنظيمه حول أربعة أقسام رئيسية.
- تصف مجموعات الأعمدة الأعمدة والتنسيقات والملفات ونطاقات معرفات الصفوف.
- سجلات دلتا تصف عمليات الحذف. تغطي أنواع الحذف المختلفة مصادر مختلفة للتغيير، مثل عمليات حذف المفتاح الأساسي من العملاء، أو الحذف الموضعي من الضغط الداخلي، أو الحذف المتساوي من المحركات الخارجية.
- تتضمن الإحصائيات بيانات وصفية للتخطيط مثل مرشحات الازدهار وإحصائيات BM25 وقيم الحد الأدنى/الحد الأقصى.
- تصف الفهارس نوع الفهرس والمعلمات والأعمدة المغطاة ونطاقات معرفات الصفوف. يمكن أن يشمل ذلك الفهارس المتجهة مثل HNSW أو IVF، والفهارس النصية، والفهارس المقلوبة، والفهارس النقطية، والهياكل ذات الصلة.
هذا هو المكان الذي يختلف فيه Loon عن بيان الجدول التقليدي.
تحتاج مجموعة البيانات المتجهة إلى تتبع ليس فقط ملفات البيانات والأقسام. بل تحتاج أيضًا إلى تتبع فهارس المتجهات، والفهارس النصية، والميزات المتناثرة، وسجلات الحذف، والإحصائيات، ومراجع الكائنات الخارجية، ونطاقات معرفات الصفوف التي تربطها.
يجب أن يكون البيان قابلاً للكتابة من قبل أكثر من قاعدة البيانات
الجزء الأكثر أهمية ليس فقط ما يحتويه البيان. بل من يستطيع كتابته.
- إذا كانت قاعدة البيانات هي الوحيدة القادرة على كتابة البيان، فستبقى بيانات وصفية داخلية. بيانات وصفية أنظف، ولكنها تظل خاصة بمحرك واحد.
- إذا كان بإمكان المحركات الخارجية إنشاء مجموعات أعمدة وإحصائيات وإدخالات بيانات، يصبح البيان واجهة تنسيق.
- يمكن لمهمة Spark، على سبيل المثال، إعادة ملء عمود متجه متناثر. فهي تكتب مجموعة أعمدة جديدة، وتسجل تغطية الصفوف والإحصائيات، وتلتزم ببيان جديد. يمكن أن تستمر الاستعلامات عبر الإنترنت في قراءة الإصدار القديم أثناء المهمة. بمجرد نجاح الالتزام، يصبح الإصدار الجديد مرئيًا.
هذا مشابه في روحه لـ Iceberg و Delta Lake، لكن نموذج الكائن أوسع. تحتاج مجموعة البيانات المتجهة إلى تتبع الفهارس المتجهة والفهارس النصية والميزات المتفرقة وسجلات الحذف والإحصائيات ومراجع النقطة، ونطاقات معرفات الصفوف، وليس فقط ملفات الجداول والأقسام.
الالتزامات المتفائلة تبقي تحديثات الإصدار بسيطة
كل التزام يكتب إصدار بيان جديد. يمكن للكاتب بناء محتوى جديد بناءً على الإصدار N، ثم محاولة الكتابة manifest-{N+1}.avro. يمكن أن تؤدي دلالات الكتابة الشرطية لتخزين الكائنات أو دلالات مطابقة التوليد إلى فشل الالتزام إذا كان هذا الإصدار موجودًا بالفعل. يمكن للكاتب بعد ذلك إعادة المحاولة مقابل الإصدار الأحدث.
وهذا يمنح Loon التزامن المتفائل دون إجبار كل تحديث على المرور عبر مسار تنسيق ثقيل ومتسق بقوة. بدون البيان، يتحول التخزين متعدد التنسيقات والمحركات في النهاية إلى اصطلاحات التسمية والتوفيق اليدوي. قد ينجح ذلك مع مجموعات البيانات الصغيرة. لكنه لا يعمل مع البيانات المتجهة على نطاق التيرابايت.
البيان هو ما يحول الملفات غير المتجانسة إلى مجموعة بيانات يمكن لأنظمة متعددة قراءتها وتحديثها بأمان.
ما الذي يتغير بالنسبة للمستخدمين عندما يصبح التخزين بإصدار
بالنسبة لمطوري التطبيقات، لا ينبغي أن تصبح Loon عبئاً جديداً على واجهة برمجة التطبيقات.
يجب أن يستمر المستخدمون في العمل مع مفاهيم ميلفوس المألوفة: المجموعات، والإدراج، والبحث، والبحث المختلط. لا ينبغي أن يحتاجوا إلى التفكير في ملفات البيانات، أو مجموعات الأعمدة، أو نطاقات معرّفات الصفوف، أو تخطيط الملفات أثناء تطوير التطبيق العادي.
التغيير في الأسفل. يصبح التخزين أكثر وعيًا بكيفية تطور مجموعات بيانات الذكاء الاصطناعي فعليًا.
يجب ألا تؤدي إضافة تضمين جديد إلى نقل البيانات القديمة
في السابق، كانت إضافة embedding_v2 إلى مجموعة موجودة غالبًا ما تتطلب تصدير البيانات، وتدريب نموذج جديد، وتوليد المتجهات، ثم إعادة استيراد المجموعة أو تحديثها بشكل مجمّع عبر مجموعة تطوير البرمجيات. يؤدي هذا المسار إلى الكثير من العمل التشغيلي: تتبع الإصدار، وإعادة محاولة العمل الفاشلة، وإعادة بناء الفهرس، وتأثير الخدمة، والتحقق من الاتساق.
مع Loon، يمكن أن يصبح هذا تطورًا للمخطط بالإضافة إلى التزام مجموعة أعمدة جديدة. يمكن كتابة عمود التضمين الجديد كمجموعة أعمدة فعلية خاصة به، محاذاة حسب معرف الصف، وجعلها مرئية من خلال البيان. لا يلزم نقل عمود التسمية التوضيحية القديم وعمود البيانات الوصفية القياسي وعمود التضمين الأصلي.
يجب ألا تتطلب عمليات الردم حلقة تحديث من جانب العميل
العديد من تحديثات بيانات الذكاء الاصطناعي عبارة عن عمليات ردم. قد يضيف الفريق متجهات متفرقة بعد أن يصبح البحث الهجين مهمًا. قد يضيف ميزات إعادة الترتيب بعد تدريب نموذج جديد. قد يصحح التسميات التوضيحية بعد المراجعة البشرية. قد يضيف علامات حوكمة بعد تحديث السياسة.
في التخطيط التقليدي، غالبًا ما تحدث هذه التغييرات عبر تحديثات SDK الخاصة بالعميل أو مسارات الكتابة الخاصة بقاعدة البيانات فقط، حتى عندما يتم إنتاج البيانات بواسطة Spark أو Ray أو محرك خارجي آخر.
مع Loon، يمكن لأنظمة الحوسبة الخارجية إنتاج مجموعات أعمدة جديدة والتزامها من خلال البيان. لم يعد من الضروري أن تكون قاعدة البيانات نقطة الدخول الوحيدة لكل عملية إعادة كتابة.
يجب ألا يتطلب التحليل دون اتصال بالإنترنت نسخة أخرى من الحقيقة
في السابق، غالبًا ما كانت الفرق غالبًا ما تقوم بتفريغ مجموعة عبر الإنترنت في Parquet للتقييم أو التحليل دون اتصال بالإنترنت. يؤدي ذلك إلى إنشاء نسختين من نفس مجموعة البيانات: المجموعة المتصلة بالإنترنت ونسخة التحليل. بمجرد تصحيح التسميات التوضيحية أو إعادة إنشاء التضمينات، أو تطبيق سجلات الحذف، أو إعادة بناء الفهارس، يتعين على الفريق أن يسأل عن النسخة الحالية.
باستخدام نموذج التخزين المستند إلى البيانات، يمكن لمحركات التحليل قراءة نفس طريقة عرض مجموعة البيانات ذات الإصدار مثل نظام العرض. ويمكنهم عرض الأعمدة التي يحتاجون إليها فقط، ومسح نطاقات الصفوف ذات الصلة فقط، والعمل مقابل إصدار مجموعة بيانات معلن بدلاً من لقطة تم تصديرها يدويًا.
يجب أن تمس عمليات الحذف والتصحيحات ما تم تغييره فقط
تُعدّ عمليات الحذف وتصحيحات التسمية التوضيحية وإصلاحات التسميات وتحديثات الحوكمة روتينية في مجموعات بيانات الذكاء الاصطناعي. يجب ألا يجبروا كل عمود متجه طويل على نفس مسار إعادة الكتابة.
باستخدام Loon، يمكن التعامل مع حذف السجلات أولاً كحذف منطقي. يمكن للضغط اللاحق تنظيف مجموعات الأعمدة المتأثرة دون إعادة كتابة البيانات غير ذات الصلة. إذا تغير حقل نصي قصير، يجب ألا تضطر طبقة التخزين إلى إعادة كتابة مئات الجيجابايت من المتجهات الكثيفة لمجرد أنها تشترك في نفس الصف المنطقي.
تصبح المحركات الخارجية جزءًا من سير العمل وليس مهربًا
التحول الأكبر هو أن المحركات الخارجية لم تعد تُعامل كأنظمة خارج قاعدة بيانات المتجهات.
حيث أن سبارك وراي ووظائف التقييم وأنظمة التسمية وخطوط أنابيب الحوكمة تنتج وتعدل بالفعل الكثير من البيانات. يجب أن تمكنهم طبقة التخزين من التعاون حول مصدر واحد للحقيقة بدلاً من التصدير والنسخ وإعادة الاستيراد باستمرار.
هذا ما يتيحه إصدار من Manifest. فهو يمنح العرض عبر الإنترنت، والتحليل دون اتصال بالإنترنت، ووظائف الردم، والضغط عرضًا مشتركًا لمجموعة البيانات.
قد تبدو هذه كتفاصيل تخزين داخلية، لكنها تؤثر على مدى سرعة الفرق في تكرار مجموعات بيانات الذكاء الاصطناعي. يعتمد كل تغيير في النموذج، وإعادة ملء الميزات، وتصحيح التسميات التوضيحية، وتصفية الجودة، وإعادة بناء الفهرس على نفس السؤال: "هل يمكن للنظام تحديث مجموعة البيانات دون نقل البيانات التي لا يحتاج إلى نقلها؟
هذه هي القيمة العملية لنموذج التخزين.
يتوفر Loon في الإصدار التجريبي من Milvus 3.0 و Zilliz Vector Lakebase
يتوفر Loon في الإصدار التجريبي من Milvus 3. 0، وهو أيضًا جزء من طبقة التخزين في Zilliz Vector Lakebase، وهو التطور التالي لـ Zilliz Cloud. ويركز هذا الإصدار على ثلاثة مجالات أساسية:
- البيان. الهدف هو أن تنتج عمليات الكتابة والردم والحذف والإحصائيات وتحديثات الفهرس طرق عرض مجموعة البيانات التي يمكن للقراء فتحها باستمرار. بالنسبة للقراء، هذا يعني أن الاستعلام يمكن أن يفتح إصدارًا محددًا من البيان ويشاهد طريقة عرض ثابتة لمجموعة البيانات. بالنسبة للكتّاب، هذا يعني أنه يمكن إعداد ملفات البيانات الجديدة أو حذف السجلات أو الإحصائيات أو ملفات الفهرس أولاً ثم جعلها مرئية من خلال التزام بإصدار.
- مجموعة الأعمدة ودعم التنسيق. تدعم الباركيه الأعمدة القياسية والملائمة للنظام البيئي. يدعم Vortex أنماط الوصول ذات المتجهات الثقيلة. يمكن دمج Lance في وضع القراءة فقط للتوافق مع مجموعات بيانات Lance الحالية.
- الفهرس على البحيرة. يمكن للإحصائيات العددية وفهارس التصفية والفهارس المقلوبة النصية المشاركة في التخطيط المستند إلى البيان حسب نطاق الصفوف. تشارك فهارس المتجهات الأصلية للبحيرة بشكل أكبر. لدى HNSW و IVF سلوك مختلف على تخزين الكائنات، و HNSW على وجه الخصوص حساس للوصول العشوائي وموقع ذاكرة التخزين المؤقت. لا يمكن ببساطة إعادة استخدام تخطيط مصمم لمخزن SSD محلي وتوقع نفس النتيجة.
لا يزال هناك عمل في المستقبل
- مسارات الكتابة الخارجية مهمة لأن سبارك وراي يجب أن يكونا قادرين على إنتاج مجموعات الأعمدة والتزامات البيان دون إجبار كل عملية تعبئة من خلال حلقة SDK للعميل.
- تعدقابلية التشغيل البيني في ليكهاوس مهمة لأن العديد من الفرق تستخدم بالفعل كتالوجات ومحركات استعلام مثل Iceberg و Delta Lake و Trino و DuckDB و Athena. يجب أن تكون البيانات المتجهة قادرة على المشاركة في هذا النظام البيئي دون فقدان أداء البحث المتجه.
- تخطيط الفهرس مهم لأن فهارس الرسوم البيانية والهياكل المقلوبة لها أنماط وصول مختلفة على تخزين الكائنات.
- إندلالات الكائنات الكبيرة مهمة لأن مقاطع الفيديو الأولية وملفات PDF والصور والملفات الصوتية تتطلب إدارة المراجع وإصدار الإصدارات وسلوك الحذف الذي يتماشى مع مجموعة البيانات المتجهة المشتقة.
يجب أن يتبع سلوك الإصدار الدقيق والإعدادات الافتراضية ومسار الترحيل ملاحظات إصدار Milvus وZilliz Cloud ذات الصلة. ومع ذلك، فإن اتجاه التخزين واضح: تحتاج قواعد البيانات المتجهة إلى أساس إصدار أصلي للبحيرة تحت طبقة العرض.
جرب Loon تحت قاعدة بحيرة زيليز المتجهة
إذا كانت مكدسك الحالي يفصل بين العرض عبر الإنترنت، والتحليل دون اتصال بالإنترنت، والردم، وسير عمل بحيرة البيانات الخارجية في أنظمة مختلفة، فإن Zilliz Vector Lakebase يستحق التجربة. يمكنك تجربتها في Zilliz Cloud. يحصل المسجّلون الجدد في البريد الإلكتروني للعمل على أرصدة مجانية بقيمة 100 دولار. نرحب بك أيضًا للتحدث معنا حول حالة الاستخدام الخاصة بك.
يمكنك أيضًا متابعة إصدار ميلفوس 3.0 لترى كيف يتطور لون في المحرك مفتوح المصدر.
يجمع محرك زيليز فيكتور ليكبيز بين:
- خدمة متدرجة لمختلف مقايضات الأداء والتكلفة في الوقت الفعلي
- بحث عند الطلب لأحمال العمل واسعة النطاق أو الاستكشافية دون حوسبة دائمة
- بحث خارجي في بحيرة البيانات، بحيث يمكنك الفهرسة والبحث مباشرةً عبر بيانات البحيرة الحالية
- بحث كامل الطيف عبر المتجهات، والنصوص، وJSON، والبيانات الجغرافية المكانية، مع الاسترجاع الهجين وإعادة الترتيب
- تخزين موحد أصلي للبحيرة مبني على Vortex، وهو تنسيق مفتوح مصمم لقراءات عشوائية أسرع وأقل تكلفة على البيانات ذات المتجهات الثقيلة
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word



