我们为何打造 Loon:一个永不停息变化的人工智能数据存储引擎。
本博客最初发表于 zilliz.com,经授权转载。
主要观点
这是一个漫长而深入的工程潜水,因此在我们进入细节之前,这里先介绍一下关键要点。
- 人工智能数据集不是静态表格。随着团队更换 Embeddings 模型、添加稀疏向量、修改标题、回填标签、重建索引以及运行离线分析,相同的行会不断发生变化。
- 传统的存储布局会在三个方面出现问题:长向量列使得回填成本高昂,单一文件格式无法同时为扫描和点读提供良好服务,私有数据库存储迫使外部管道创建额外的真相副本。
- Loon 是 Milvus 和 Zilliz Vector Lakebase 的新存储引擎。它围绕混合文件格式、行 ID 对齐和定义数据集版本状态的 Manifest 构建。
- 其目标是使单个向量数据集能够支持在线搜索、离线分析、回填、压缩和外部计算,而无需不断复制、重写或重新导入数据。
导言
曾几何时,有一种反对向量数据库的观点听起来很有道理。
传统数据库已经存储了整数、字符串、JSON、blob 和索引。为什么不添加一个 _vector_ 类型,在旁边建立一个 ANN 索引,然后就可以了呢?
对于早期语义搜索来说,这已经足够好用了。一个向量列加上一个索引就能支持一个演示、一个小型 RAG 应用程序或一个内部搜索功能。当数据集开始表现得不像一个表格,而更像一个人工智能数据系统时,问题就显现出来了。
生产型向量数据集具有行、主键、标量字段和可查询列。从这个意义上说,它看起来就像一个数据库表格。但它也具有数据湖的规模和工作流形状。它可能包含数以亿计的记录。它被 Spark、Ray、DuckDB、训练管道、评估作业和数据质量系统反复读取和重写。
它还依赖于对象存储。源对象通常是保存在 S3、GCS、OSS 或其他对象存储中的视频、图像、PDF、音频文件或网络文档。数据库存储引用、元数据、派生特征和索引。然后,它还会添加一些传统存储模型无法作为一流对象管理的内容:密集嵌入、稀疏向量、标题、向量索引、文本索引、删除日志、统计数据、模型版本、解析器版本、外部 blob 引用,以及所有这些内容之间的版本关系。
这就是 "只需添加一个向量列 "开始崩溃的地方。问题不在于数据库能否存储向量字节。许多系统都可以。更难的问题是,存储模型能否处理向量数据如何变化、如何查询以及如何在人工智能数据栈中共享。
这就是我们为 Milvus 和 Zilliz Vector Lakebase (Zilliz Cloud 的下一代进化版)打造全新存储引擎 Loon 的原因 。
Loon 的设计有三个理念:
- 为不同类型的列使用不同的物理格式。
- 通过共享行 ID 空间对齐这些列。
- 使用 Manifest 来定义数据集的版本状态。
要了解这些部分为何重要,让我们从常见的多模式工作流程开始。
向量数据集永远不会真正完成。
想象一下,一个人工智能团队正在构建一个用于多模态训练的视频数据集。
一段长视频被上传到对象存储中。管道根据场景变化、镜头边界或时间窗口将其剪切成片段。过长或过短、模糊、重复或低质量的片段会被过滤掉。剩下的片段由美学模型评分,由另一个模型配字幕,由视觉语言模型嵌入,并存储在向量数据库中,用于搜索、重复数据删除和训练数据过滤。
在高层次上,工作流程看起来很简单:
video
→ clips
→ metadata
→ aesthetic_score
→ caption
→ embedding
→ search / dedup / training data filtering
但数据集并非完全成型。
- 在第一周,表中可能只包含
clip_id,video_id,start_offset和duration。 - 第二周,团队添加了
aesthetic_score。 - 第三周,字幕模型运行,每个片段都会得到一个
caption。 - 第四周,第一个嵌入模型上线,每个片段获得一个 768 维的 CLIP 嵌入。
- 一个月后,团队切换模型并回填
embedding_v2,现在是 1024 维。 - 两个月后,混合搜索成为需要,因此团队增加了稀疏向量列。
- 三个月后,标题经过人工审核,必须就地修正。
数据集从未完成。它不断积累对相同基础行的新解释。
这就是向量数据与传统业务数据的核心区别之一。同一行会被反复处理。而规模将这一不便变成了存储问题:多模态数据集通常不是数百万条记录,而是数亿或数十亿条记录。LAION-5B就是一个有用的形状参考--数十亿的图像-文本对,每个都有元数据、标题和嵌入。因此,最难的部分并不是第一次插入。难点在于数据集开始演化后发生的一切。这种演变会暴露出三个问题。
第一个问题:长列使得写入扩增成本高昂
像 Parquet 这样的列格式非常适合许多分析工作负载。当 Schema 相当稳定、数据读取比重写更频繁、扫描只涉及列的子集以及压缩很重要时,它们就能很好地工作。许多分析格式就是在这种情况下进行优化的。
向量行比分析行宽得多
TPC-Hlineitem 是一个很好的基准。它有 16 列:整数键、十进制值、日期、短字符串和一个小注释字段。未压缩的一行大约为 150 字节。压缩后,可能会小得多。如果使用 64 MB 的行组,存储系统可以将数十万行打包到一个组中。
向量数据集并非如此。
LAION 类型的图像-文本数据集更接近于当今许多人工智能管道所生成的数据集。每一行仍然有普通的元数据:URL、标题、宽度、高度、质量分数、标签等等。但一旦添加了 Embeddings,行的物理形状就会发生变化。
一个 768 维的 CLIP 向量在 fp16 中约占 1.5 KB,在 fp32 中约占 3 KB。这一列可能比整个 TPC-Hlineitem 行还要大得多。
按照当今的标准,768 维并不稀奇,也不算大。1024 或 2048 维 Embeddings 在多模态管道中很常见。OpenAI 的text-embedding-3-large 维度高达 3072,在 fp32 中每个向量约为 12 KB。
对比结果非常明显:
| 数据集形状 | 近似行大小 | 行的主要内容 |
|---|---|---|
| TPC-H 行项 | ~150 字节(未压缩 | 标量和短字符串字段 |
| 带有 768 位 fp16 向量的 LAION 风格行 | ~1.5 KB+ | Embeddings |
| 带有 768 位 fp32 向量的 LAION 样式行 | ~3 KB+ | Embeddings |
| 带 3072 位 fp32 向量的行 | 仅向量就 ~12 KB+ | Embeddings |
在许多人工智能数据集中,向量列不仅仅是另一个字段。在物理上,它是行的大部分。这就改变了 Schema 演进的成本。
增加一列向量可能意味着数百千兆字节
假设一个数据集有 1 亿个视频片段。添加一个新的 1024 维 fp32 嵌入列意味着要写入大约 400 GB 的原始向量数据。这还不包括统计、索引、元数据更新、对象存储开销、验证或服务路径集成。

如果团队每月增加一两个类似向量的列,如embedding_v2 、sparse_vector 或 Rerankers 功能,那么 Schema 演进就会成为一项以数百 GB 或 TB 为单位的重复性 daAta 工程工作。
小的逻辑更新会引发大的物理重写
更新同样重要。
在列式系统中,旧数据通常不会就地更新。删除日志会记录更改的内容,随后压缩会将实时行重写到新文件中。当数据行较少时,这种模型是可以管理的。
对于向量数据,一个小的逻辑更新就可能引发大的物理重写。
人工审核工作可能只会纠正标题中的几百个字节。但如果标题、密集向量、稀疏向量和其他衍生特征共享相同的物理文件生命周期,系统最终可能也会重写向量。逻辑变化很小。物理 I/O 却可能非常巨大。
这就是向量存储中的写放大问题。代价高昂的不仅是向量很大。而是大型派生字段和小型可变字段经常被存储布局捆绑在一起,将它们视为一个单元。
对于人工智能数据集来说,回填是例行工作负载
对于传统的分析表,Schema 演进可能只是偶尔发生。而对于人工智能数据集来说,这是例行工作。标题模型升级。替换嵌入模型。随后添加稀疏向量。出现 Rerankers 特征。修正人工标签。回填治理标签。重建索引。
这些操作并非简单的追加。它们经常会修改或扩展现有行。
这就是为什么向量存储不能只优化扫描吞吐量。它还必须降低回填和部分更新的成本。
第二个问题:同一数据必须支持扫描和点读取
数据写入后,读取路径会分裂。同一个向量数据集通常有两种截然不同的访问模式:分析扫描和点读取。
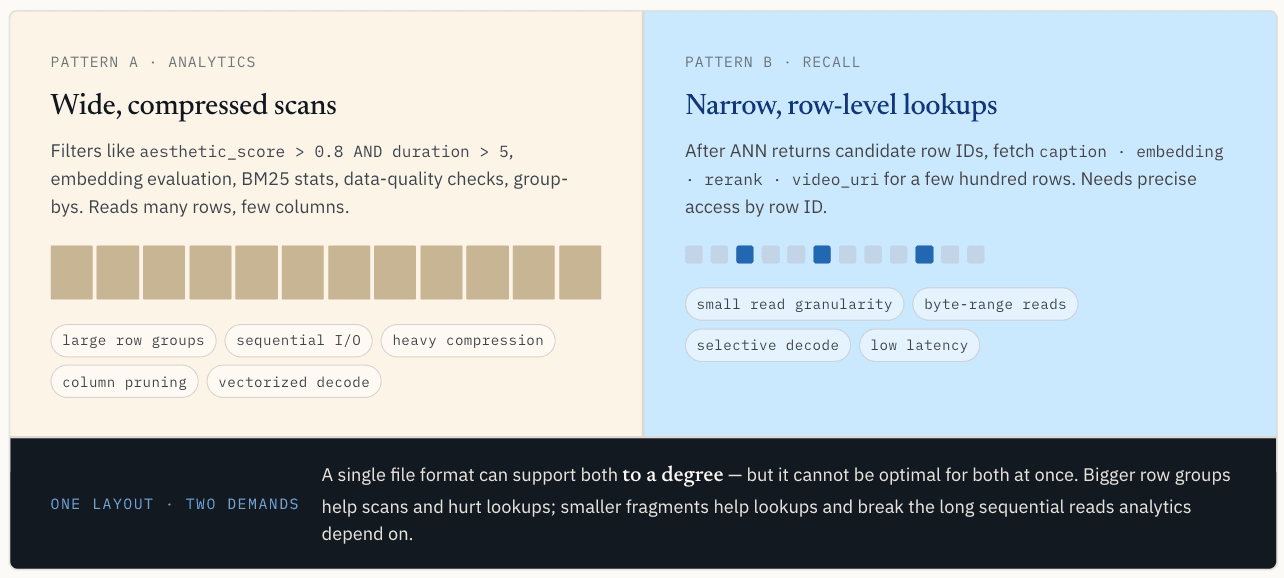
分析型工作负载需要广泛的压缩扫描
流水线可以运行过滤器,例如
WHERE aesthetic_score > 0.8 AND duration > 5
或者运行离线分析、全嵌入评估、BM25 统计、位图构建、数据质量检查、计数和分组。
这种模式会读取许多行,但只读取少数列。它喜欢顺序 I/O、较大的行组、压缩、列剪枝、批量解码和向量执行。
大型行组在这方面很有帮助。它们能让单个 I/O 请求获取大量有用数据,提高压缩效率,并为执行引擎提供足够的连续数据以摊销开销。当多列一起读取时,保持它们的有序性以提高扫描吞吐量,也有助于减少向量执行过程中的缓存缺失。
Parquet 在这方面表现出色。
ANN 结果需要狭窄的行级查找
在 ANN 搜索返回候选行 ID 后,系统通常需要获取以下字段:
caption
embedding
rerank feature
video_uri
metadata
这种模式读取的行数较少,通常只有几百或几千行,但它需要按行 ID 进行精确访问。它希望找到特定的行和列,只获取所需的字节范围,避免为了获取几条记录而调用整个行组。
点查找与扫描的偏好几乎相反。它需要更小的读取粒度。理想情况下,存储层可以通过行 ID 找到相关的段或字节范围,只读取该范围,并只解码结果所需的数据。
压缩也有不同的取舍。对于扫描,较重的压缩通常是值得的,因为系统会读取大量数据并节省 I/O。而对于点查找,如果检索一条记录需要解码一个大得多的压缩块,压缩就会成为一种负担。
一种布局无法同时优化两种路径
这是核心矛盾。标量过滤和分析需要宽、压缩、便于扫描的布局。向量查找需要窄的、精确的、可寻址的布局。
单一文件格式可以在一定程度上同时支持这两种需求,但不可能同时满足这两种需求。
如果所有列都在 Parquet 中,标量扫描就会很方便。但调用后的 ANN 查找就变得困难了。系统可能只需要几百条向量、标题或元数据记录,而存储层可能不得不读取包含大部分无关行的大型行组。
在本地固态硬盘上,缓存和 mmap 可以隐藏部分成本。一旦数据存储在对象存储中,成本就会变得更加明显。每一次缓存缺失都可能成为一次远程范围读取。如果候选行分散在多个行组中,单次查询就会触发多次读取,每次读取的数据量都会超过查询所需的数据量。在布局不合理的情况下,获取 1,000 条候选行很容易导致数十或数百兆字节的不必要 I/O,极端情况下甚至会更多。
缩小行组有助于点查找,但会损害扫描。过多的小片段会降低压缩效率,增加元数据开销,并破坏分析引擎所依赖的长序列读取。
因此,问题并不在于找到单一的神奇行组大小。问题在于,同一个数据集被要求像两个不同的存储系统一样运行。
混合搜索将两种路径合并为一个查询
混合搜索使冲突更难被忽视。单个查询可能首先应用标量过滤器:
aesthetic_score > 0.8 AND duration > 5
然后运行 ANN 搜索。
然后按行 ID 获取标题、向量和元数据。
对用户来说,这是一个搜索请求。对存储层来说,这既是一次分析扫描,也是一次低延迟随机查找。
这就是为什么向量存储需要的不仅仅是更好的 Parquet 设置。它需要一种根据实际读取方式来放置不同列的方法。
第三个问题:数据集不在一个引擎内
前两个问题发生在数据库内部。第三个问题发生在系统之间的边界。

人工智能数据管道跨越多个系统
在视频工作流程中,向量数据库本身几乎不存在任何问题。
原始视频保存在对象存储中。剪辑生成可能在 Spark 或 Ray 中运行。美学评分可以在 GPU 服务中运行。字幕制作可以在 LLM 推理管道中运行。嵌入可能由另一个 GPU 工作生成。稀疏向量可能来自 SPLADE 服务。离线评估、训练数据过滤、人工审核和治理工作都可能在其他地方运行。
向量数据库服务于在线搜索,但数据集是由许多系统制作、修正、评估和扩展的。
专用存储格式可创建多个真相副本
如果数据库使用只有自己才能读写的私有物理格式,那么每个外部任务都需要导出、转换、复制和导入。同样的 Collections 可能存在于数据库、Spark 临时目录、评估输出和本地回填目录中。那么真正的问题就来了:
- 哪个副本才是真相的来源?
- 哪一份包含上个月的标题模型?
- 哪些行已经过人工审核修正?
- 哪个稀疏向量列是由哪个模型生成的?
- 哪个向量索引在回填后仍然有效?
- 这一行指的是哪个原始视频对象?
在小规模情况下,团队有时可以通过命名约定和人工检查来解决问题。如果有数亿行和 TB 级的 Embeddings,这就成了一个一致性问题。
向量数据集需要一个共享的版本化状态
Lakehouse 系统解决了结构化数据的这一问题。Iceberg、Delta Lake 和 Hudi 不仅仅是存储文件。它们的核心贡献是让多个引擎围绕同一个表状态进行协调。
向量数据库现在需要类似的能力,但状态更加复杂。它不仅必须包括表文件和分区,还必须包括向量索引、文本索引、稀疏特征、删除日志、统计数据、行 ID 范围以及外部 blob 的引用。
问题并不简单,"Spark 能读取 Milvus 文件吗?"
问题是,在 Spark 回填稀疏向量列之后,Milvus 如何知道该列属于哪个版本、覆盖哪些行、由哪个模型生成,以及何时可以安全地在线查询使用该列?
答案就在存储模型中。
为什么仅有补丁是不够的
我们很容易将这些问题视为三个独立的工程问题。
- 写入放大?添加批处理。
- 点读取?添加缓存。
- 外部系统?添加导出和导入工具。
这些补丁可以提供帮助,但并不能解决根本问题:向量数据集在物理上是异构的。

在视频示例中,clip_id 、video_id 、duration 和aesthetic_score 是短标量字段。它们有助于过滤和分析。
caption是文本。可用于 BM25、审查、校正和回填。embedding是长而密集的向量。用于 ANN 召回,之后用于行级查找或 Rerankers。embedding_v2是一个新的模型输出,通常在插入原始数据很久之后才回填。sparse_vector原始视频支持混合搜索,并有自己的访问模式。- 原始视频应保存在对象存储中。数据库应存储引用、校验和、MIME 类型、解析器版本和行级关系。
- 向量索引、文本索引、统计数据和删除日志是派生对象,有自己的版本语义。
这些对象共享一个逻辑行,但它们不应共享相同的物理布局或生命周期。
- 如果强行将它们合并为一个普通表布局,更新的成本就会变得很高。
- 如果强行将它们合并为一种列式文件格式,点读取就会变得昂贵。
- 如果将它们视为不相关的对象文件,版本管理就会变得脆弱。
因此,存储模型必须从数据集是异构的这一事实出发。
这就产生了三个设计要求:
- 首先,不同的列组应该以不同的物理格式存储。
- 其次,这些列组需要一个共享的行 ID 空间,这样它们就能像一个逻辑表一样运行。
- 第三,数据集需要一个版本化的 "清单"(Manifest),声明哪些文件、索引、日志、统计数据和对象引用属于当前视图。
这就是我们在 Milvus 和 Zilliz Cloud 背后的新存储引擎 Loon 背后的设计。
Loon:Milvus 和 Zilliz Cloud 背后的存储引擎,用于不断演化的向量数据集
为了解决上述所有问题,我们为 Milvus 和Zilliz Vector Lakebase(Zilliz Cloud 的下一代进化版)构建了新的存储引擎Loon,专为不断演化的向量数据集而设计。
这个名字沿袭了 Zilliz 的鸟类命名传统。loon 是一种生活在湖泊上的潜鸟,这与系统的目标不谋而合:向量数据库每次运行查询、回填列或建立索引时,都不必移动、扫描或重写整个数据湖。它应首先了解当前数据集的版本,包括其列、索引、统计信息、删除日志和对象引用,然后只读取实际需要的部分。
混合文件格式、行 ID 对齐和 Manifest 并不是三个独立的功能。它们源于同一个设计假设:向量数据集本身就是异构的。
三个部分,一个存储模型
混合文件格式承认不同列有不同的访问模式。标量字段适用于扫描和筛选。向量字段需要高效的行级查找。视频、PDF、图像和音频文件等原始对象属于对象存储,而不是数据库数据文件。
行 ID 对齐承认这些列可能在物理上是分开的,但它们仍然描述相同的逻辑行。标题、Embeddings、稀疏向量和视频 URI 可能存在于不同的文件和格式中,但它们仍然需要作为一个结果汇集到一起。
Manifest 承认,数据集不是写完一次就不管了。它将被多个系统、多个版本、多个任务所修改。索引、统计、删除日志、外部对象引用和列组都必须出现在同一版本视图中。
这就是为什么 Loon 不仅仅是一种更快的向量文件格式。更快的格式有助于点查找,但不能解决 Schema 演进或多引擎协调问题。行 ID 对齐可以让拆分的列表现得像一个表,但它并不能指定哪些文件属于当前版本。Manifest 可以描述数据集的状态,但如果没有列群和行 ID 对齐,它就无法在一个逻辑 Collections 内清晰地表示不同的物理布局。
存储模型需要这三样东西:不同列组的不同格式、重构行的共享行 ID 空间,以及告诉每个读写器当前数据集是什么的版本化 Manifest。
Loon 在 Milvus 和 Zilliz Vector Lakebase 中的定位
在 Milvus 中,它用围绕 Manifest、ColumnGroup、文件格式和文件系统抽象构建的模型取代了旧的段 binlog 存储层。在Zilliz Vector Lakebase(Zilliz Cloud 的下一个演进版本)中,同样的方向也适用于 Vector Lakebase 架构:在保持向量数据库服务路径快速的同时,让底层数据更易于演进、分析以及与外部系统协调。
上层的 Milvus 组件仍然保持它们熟悉的角色。代理处理路由。QueryCoord 和 DataCoord 负责调度。IndexNode 负责建立索引。面向应用的 Collections、插入、搜索和混合搜索 API 无需公开 Manifest 文件或 ColumnGroup。
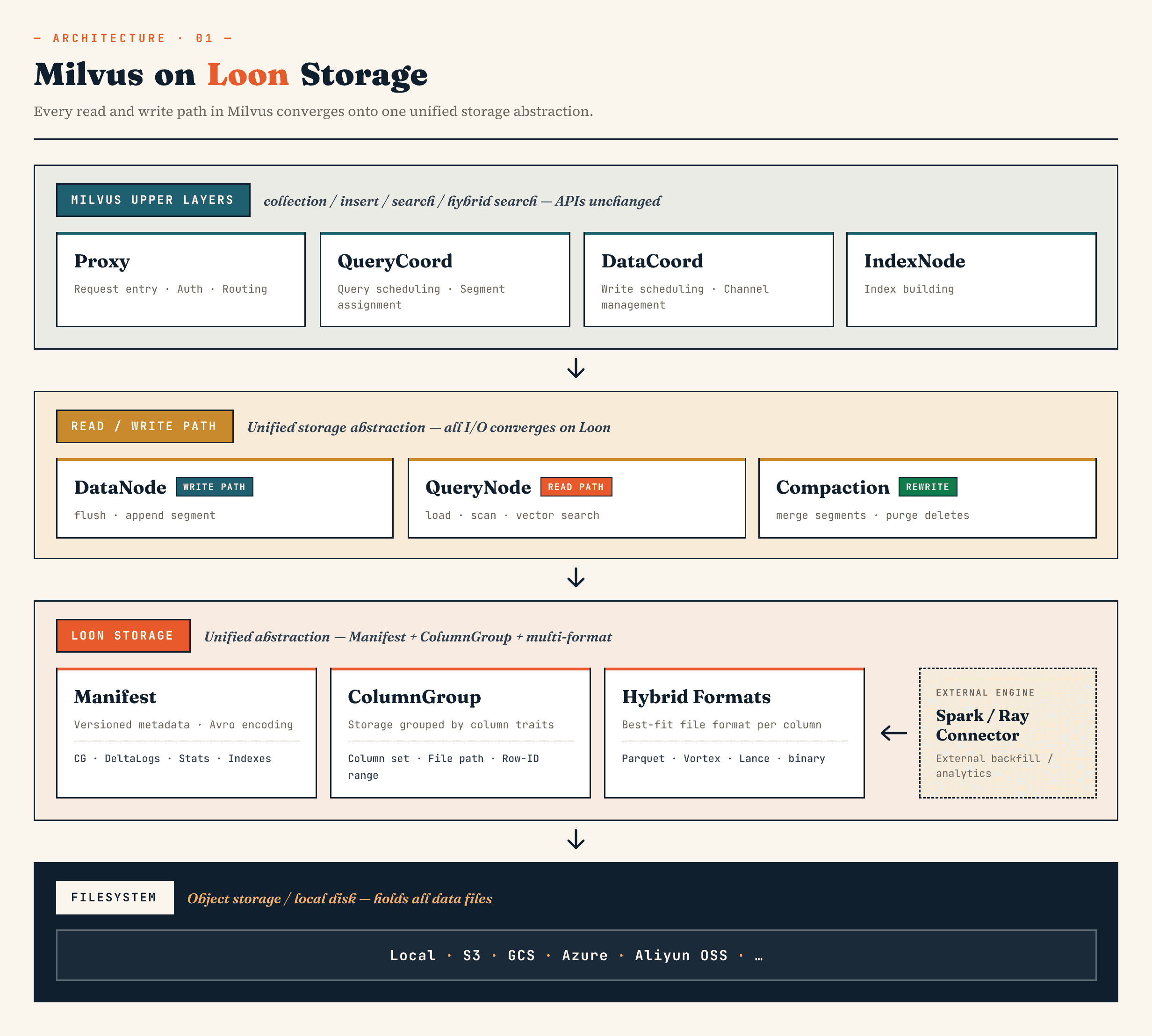
变化在下面。
DataNode、QueryNode、segcore、压缩和外部连接器可以通过相同的存储抽象进行操作。这很重要,因为数据集不再仅由数据库写入和读取。外部计算系统可以扩展数据集,在线搜索也可以同时使用数据集。
从高层来看,这些层是这样的:
Manifest
→ ColumnGroup
→ file format layer
→ filesystem abstraction
Manifest 描述数据集的版本状态。ColumnGroups 将逻辑 Collections 映射到物理列组。文件格式层可让每个列组选择合适的格式。文件系统抽象可在对象存储和本地存储中使用。
重要的一点是,混合文件格式、行 ID 对齐和 Manifest 并不是独立的功能。它们共同定义了存储模型。
有了这个模型,我们就可以逐一查看三种设计选择:Loon 如何存储不同的 ColumnGroup,如何将它们重新对齐成行,以及 Manifest 如何将这些文件变成版本化数据集。
设计 1:为正确的列组使用正确的文件格式
不同的列有不同的访问模式。不应强迫它们使用相同的文件格式。
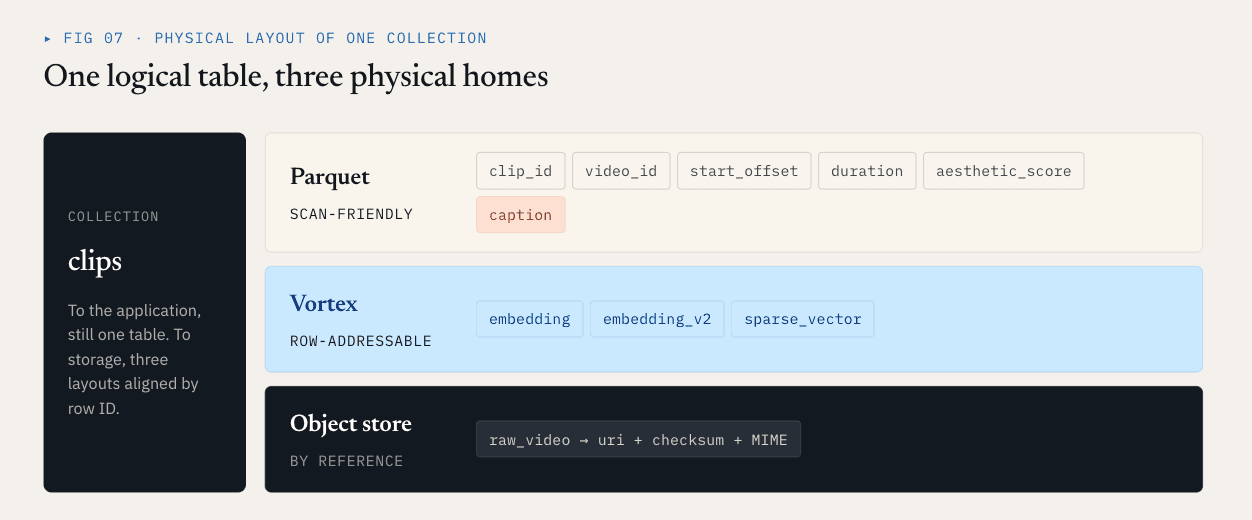
Loon 将逻辑 Collections 分成 ColumnGroups。
- 标量字段、过滤字段、业务键和统计字段经常被扫描、过滤、聚合或用于查询规划。它们受益于压缩、列修剪和生态系统兼容性。Parquet 非常适合这些列。
- 密集向量、稀疏向量和 Rerankers 特征通常在 ANN 召回后按行 ID 读取。它们需要低延迟随机访问、精确的字节范围读取和选择性解码。面向分段的布局更合适。Loon 在这方面使用了 Vortex。
- 视频、PDF、图像和音频文件等原始对象不应嵌入向量数据库的数据文件中。它们应保留在对象存储中。数据库会记录引用、校验和、MIME 类型、解析器版本和行级关系。
在视频示例中,物理布局可能是这样的:
Parquet ColumnGroup:
clip_id / video_id / start_offset / duration / aesthetic_score / caption
Vortex ColumnGroups:
embedding
embedding_v2
sparse_vector
Object storage:
raw video objects
对于应用程序来说,这仍然是一个 Collection。对于存储层来说,该 Collections 的不同部分使用不同的物理格式。这直接减少了不必要的重写。添加embedding_v2 可以变成一个新的向量 ColumnGroup 加上 Manifest 提交。它不需要重写标题列、标量元数据或现有的 Embeddings 列。
同样的想法也适用于稀疏向量、Rerankers 特征或其他派生字段。如果新列在物理上是独立的,并按行 ID 对齐,那么它就不必将不相关的列拖入同一重写路径。
Loon 还能调整文件格式的使用。
对于 Parquet 而言,默认设置并不总是向量重型数据的理想选择。对于点查找来说,64 MB 的行组可能过大,因为一个小的随机读取可能会拉出远多于需要的数据。Loon 将相关路径中的行组收紧到 1 MB,并在对随机查找向量数据没有帮助时禁用编码,如向量列上的字典编码。
对于 Vortex 来说,更重要的工作是布局。Loon 采用的布局兼顾了扫描效率和点查找。在一个行组内,相关列的段可以靠近放置,以支持扫描。为了执行操作,子段读取允许系统只获取相关字节,而不是拉取整个段。
Loon 还支持只读 Lance 集成,因此在兼容性问题上,现有的 Lance 数据集可以作为 ColumnGroup 挂载。
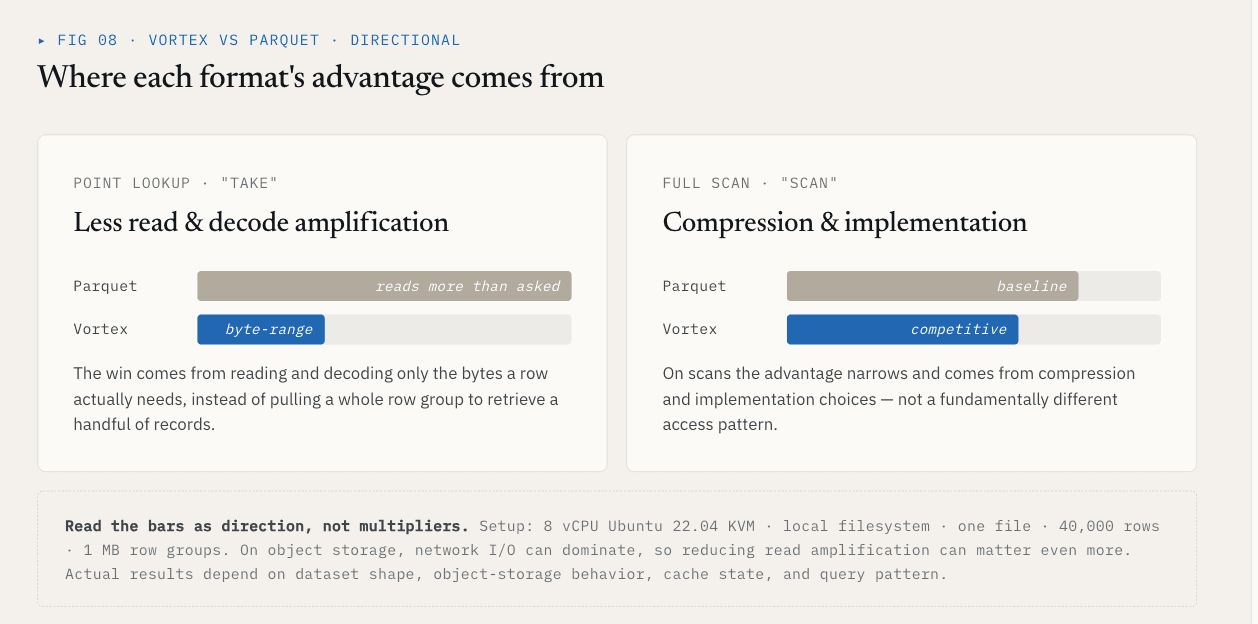
基准测试结果
在一次本地测试中,Vortex 使用具有 40,000 行和 Schema{id: int64, name: utf8, value: float64, vector: list<float32>[128]} 的单个文件,与具有 1 MB 行组的 Parquet 进行了对比,结果如下:
| 操作符 | Vortex | 镶嵌 | 差异 |
|---|---|---|---|
| 取,K=1000 随机行 | 5.8 毫秒 | 144 毫秒 | 快 25 倍 |
| 全向量列扫描 | 21 毫秒 | 142 毫秒 | 快 6.76 倍 |
| 文件大小,~21 MB 原始数据 | 6.62 MB | 7.16 MB | 缩小 7 |
take 的结果来自于减少了必须读取和解码的无关数据量。扫描结果来自压缩和执行选择。
这些数字应与它们的设置保持一致:8 vCPU Ubuntu 22.04 KVM、本地文件系统、一个文件、40,000 行、1 MB 行组以及上述 Schema。在对象存储中,网络 I/O 可能占主导地位,因此降低读取放大率可能更为重要。实际结果取决于数据集形状、对象存储行为、缓存状态和查询模式。
更广泛地说,并不是每一列都应该使用 Vortex。
重点是,向量数据集需要在 ColumnGroup 层面选择文件格式。
设计 2:通过行 ID 对齐物理文件
混合文件格式解决了一个问题:不同的列现在可以使用最适合它们的格式。
但这又产生了第二个问题。如果标量字段住在 Parquet 中,向量住在 Vortex 中,原始对象住在对象存储中,系统如何仍将它们视为一个 Collections?
Loon 通过行 ID 对齐解决了这个问题。
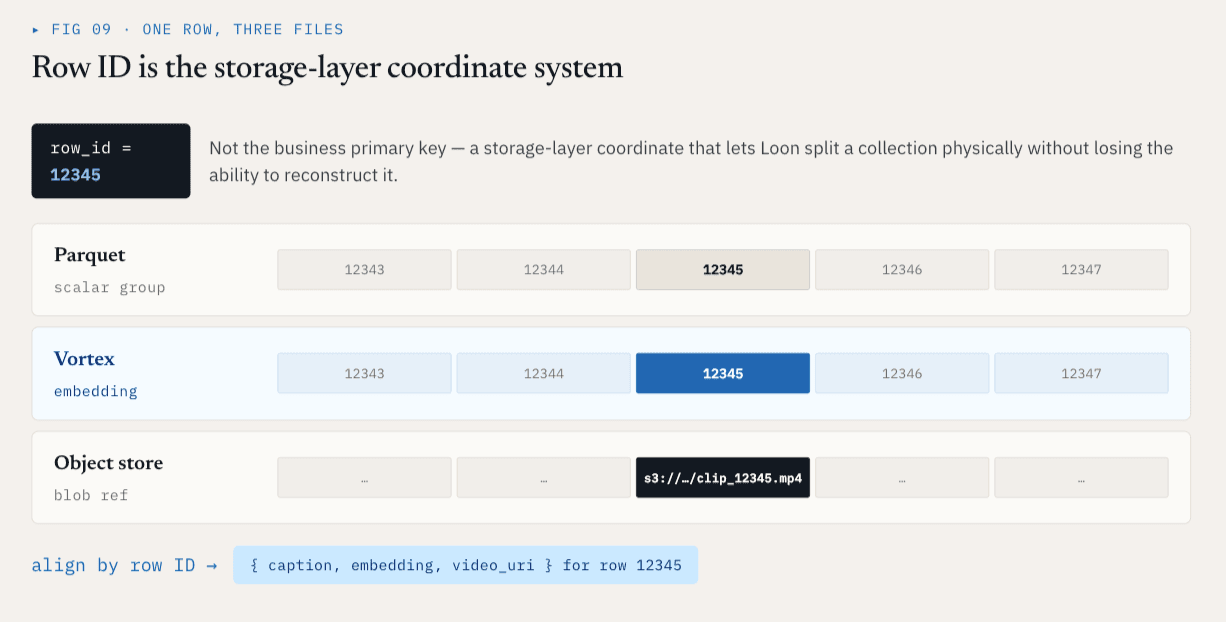
行 ID 是存储层坐标系
每个物理 ColumnGroupFile 都记录了文件路径和所覆盖的行 ID 范围:
path
start_index
end_index
不同的 ColumnGroup 可以覆盖相同的行 ID 空间,即使它们存在于不同的文件和格式中。
对于行 ID12345 ,标量元数据可能在 Parquet ColumnGroup 中,嵌入可能在 Vortex ColumnGroup 中,而原始视频可能由对象存储引用表示。从逻辑上讲,它们仍然是一行。这就为存储层提供了一个稳定的坐标系。
行 ID 不是业务主键。它是存储层的坐标系,可让 Loon 在物理上分割一个 Collections,而不会失去逻辑上重建它的能力。
新列无需重写旧列
添加embedding_v2 不需要重写原始标题、元数据或embedding_v1 ColumnGroups。Loon 可以编写一个新的向量 ColumnGroup,记录其覆盖的行 ID 范围,并通过 Manifest 提交该变更。
这同样适用于后来到达的稀疏向量、Rerankers 特征或其他派生字段。
只要新的 ColumnGroup 覆盖了正确的行 ID 范围,它就可以加入相同的逻辑 Collections,而不会强制移动不相关的数据。
删除和压缩更有针对性
行 ID 对齐也有助于删除。
删除首先可以通过删除日志来表达。在逻辑层面上,该行会变得不可见,而物理清理会延迟到压缩之后。当压缩最终运行时,它并不总是需要重写与受影响行绑定的每个 ColumnGroup。它可以专注于需要清理的 ColumnGroup。
这一点很重要,因为并非每一列都有相同的成本特征。重写一个短标量 ColumnGroup 与重写数百 GB 的密集向量截然不同。
混合搜索可以只获取需要的列
行 ID 对齐也是混合搜索在混合文件格式基础上的实用性所在。
ANN 搜索返回候选行 ID 后,系统可以只获取最终结果所需的字:标题、元数据、向量、Rerankers 特征或对象引用。
例如,查询可能需要
caption
embedding
video_uri
这些字段可能存在于不同的列组(ColumnGroups)中。Loon 可以通过行 ID 范围找到相关文件,读取必要的字节范围,并将结果汇总。
如果没有行 ID 对齐,混合格式将只是并排放置的独立文件。有了行 ID 对齐,它们就像一个逻辑 Collections。
打包阅读器从上层隐藏了分割过程
打包阅读器是实现这一功能的运行时组件。
上层看到的是一个统一的 Arrow RecordBatch 流。在下层,数据可能来自不同文件格式的多个 ColumnGroup。打包阅读器会隐藏这些差异,按行 ID 范围对齐数据,并通过控制内存使用量来安排多文件 I/O。
它还支持按行 ID 直接take 。给定一组行 ID,它就能找到相关的 ColumnGroupFiles,进行范围读取,并返回请求的字段。
对于视频工作流,ANN 查询可能需要caption 、embedding 和video_uri 。打包读取器可以在不接触无关列的情况下获取标量 ColumnGroup 和向量 ColumnGroup。
这就是 "独立文件 "和 "具有多个物理布局的表 "之间的区别。
设计 3:让清单成为真理之源
混合文件格式定义了数据的物理存储方式。行 ID 对齐方式决定了分离的列组(ColumnGroups)如何仍然构成一个逻辑表。但系统仍需要回答一个更大的问题:哪些文件、日志、统计信息、索引和对象引用属于当前版本的数据集?这就是 Manifest 的工作。

仅有对象存储目录是不够的
对象存储不是数据库目录。目录中可能包含旧文件、新文件、失败的作业输出、临时文件、删除日志、仍被旧快照引用的文件以及等待清理的文件。文件存在并不意味着它属于当前数据集版本。
Loon 数据集可能被组织成如下目录:
_metadata/
_data/
_delta/
_stats/
_index/
但目录结构并不是真相的来源。清单才是。读者不应该列出目录,并根据碰巧存在的文件推断状态。他们应该阅读当前的 Manifest,并遵循它所声明的版本视图。
Manifest 定义了数据集的一个版本视图
Manifest 定义了特定版本的数据集。它记录
- 存在哪些列组
- 它们覆盖了哪些行 ID 范围
- 每个列组使用的物理格式
- 文件存放在哪里
- 哪些删除日志处于活动状态
- 哪些统计数据可用
- 存在哪些索引
- 引用了哪些外部 Blob
- 这些统计信息或索引覆盖哪些列和行范围
每次更新都会写入一个新的 Manifest 版本。打开第 N 版的读者看到的是第 N 版数据集的稳定视图。写入者可以准备第 N+1 版,而不会影响仍在使用第 N 版的读者。
Manifest 跟踪的不只是表文件
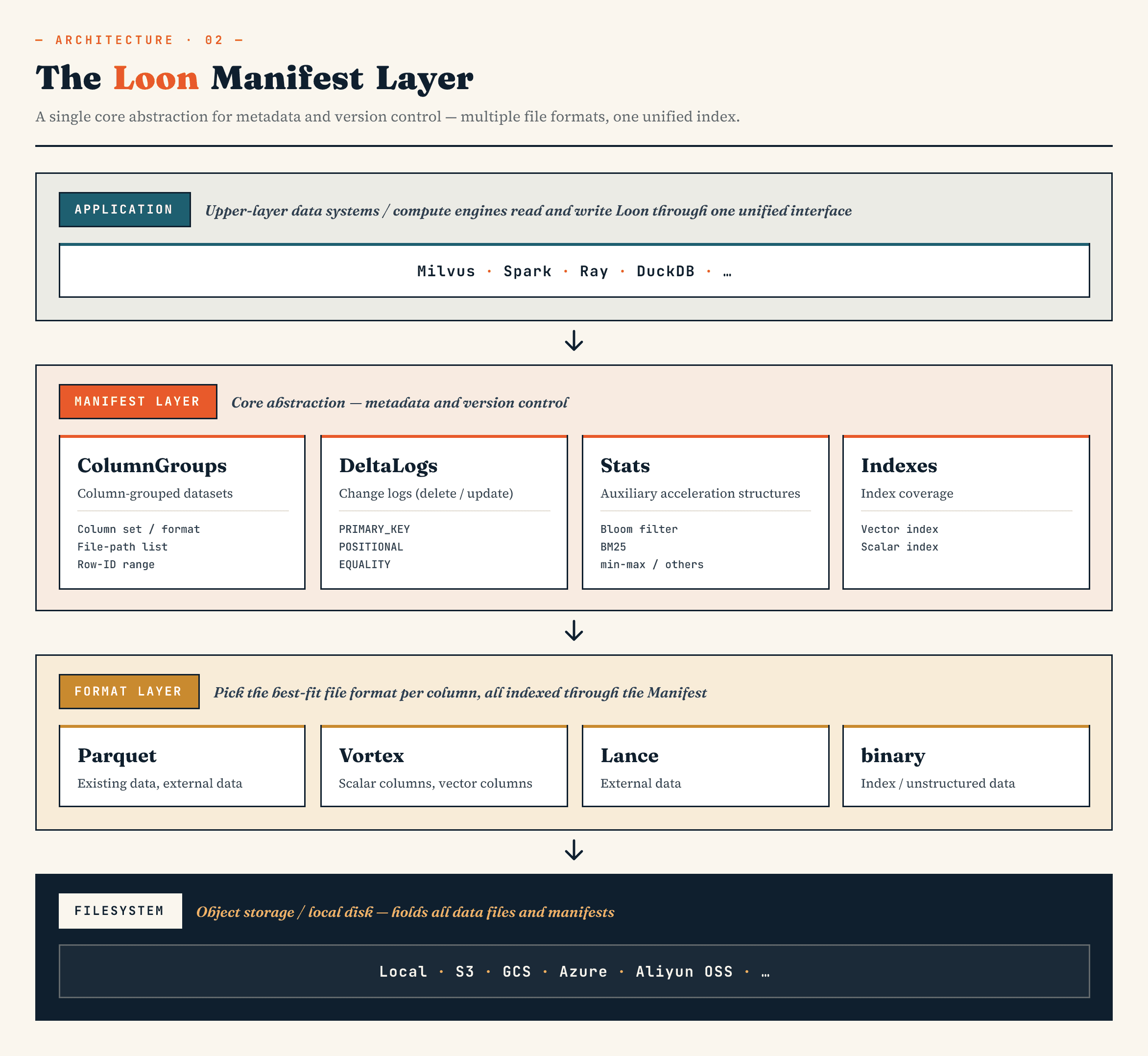
在 Loon 中,Manifest 主体使用 Apache Avro 编码,并围绕四个主要部分组织。
- ColumnGroups 描述列、格式、文件和行 ID 范围。
- DeltaLogs 描述删除。不同的删除类型涵盖不同的变化来源,例如来自客户端的主键删除、来自内部压缩的位置删除或来自外部引擎的相等删除。
- 统计信息包括规划元数据,如 bloom 过滤器、BM25 统计信息和最小/最大值。
- 索引描述索引类型、参数、覆盖列和行 ID 范围。这可能包括向量索引(如 HNSW 或 IVF)、文本索引、反转索引、位图索引和相关结构。
这就是 Loon 与传统表格清单的不同之处。
向量数据集不仅需要跟踪数据文件和分区。它还需要跟踪向量索引、文本索引、稀疏特征、删除日志、统计数据、外部对象引用以及连接它们的行 ID 范围。
除数据库外,Manifest 还必须能被更多人写入
最重要的部分不仅仅是清单包含的内容。最重要的是谁可以写。
- 如果只有数据库可以写 Manifest,那么它仍然是内部元数据。元数据更干净,但仍是一个引擎的私有数据。
- 如果外部引擎可以生成新的 ColumnGroups、stats 和 Manifest 条目,那么 Manifest 就会成为一个协调接口。
- 例如,Spark 作业可以回填稀疏向量列。它会写入一个新的 ColumnGroup,记录行覆盖率和统计信息,并提交一个新的 Manifest。在线查询可以在作业过程中继续读取旧版本。一旦提交成功,新版本就会变得可见。
这与 Iceberg 和 Delta Lake 的精神相似,但对象模型更宽泛。向量数据集需要跟踪向量索引、文本索引、稀疏特征、删除日志、统计信息、blob 引用和行 ID 范围,而不仅仅是表文件和分区。
乐观提交让版本更新更简单
每次提交都会写入一个新的 Manifest 版本。写入者可根据版本 N 创建新内容,然后尝试写入manifest-{N+1}.avro 。如果版本已经存在,对象存储的条件写入或生成匹配语义会导致提交失败。然后,写入者可以针对更新的版本重试。
这就为 Loon 提供了乐观的并发性,而不会强迫每次更新都要通过繁重的强一致性协调路径。如果没有清单,多格式和多引擎存储最终会变成命名约定和手动调节。这可能适用于小型数据集。但对于 TB 级的向量数据来说却行不通。
正是清单将异构文件转化为多个系统可以安全读取和更新的数据集。
存储版本化后,用户会有哪些变化
对于应用程序开发人员来说,Loon 不应该成为新的 API 负担。
用户仍应使用熟悉的 Milvus 概念:Collection、插入、搜索和混合搜索。在正常的应用程序开发过程中,他们不需要考虑 Manifest 文件、ColumnGroups、行 ID 范围或文件布局。
变化就在下面。存储变得更加了解人工智能数据集的实际发展情况。
添加新 Embeddings 不应移动旧数据
以前,向现有 Collections 添加embedding_v2 通常需要导出数据、训练新模型、生成向量,然后通过 SDK 重新导入或批量更新 Collections。这种路径会产生大量操作符:版本跟踪、失败作业重试、索引重建、服务影响和一致性检查。
有了 Loon,这就可以变成 Schema 演进加上新的 ColumnGroup 提交。新的 Embeddings 列可以写成自己的物理 ColumnGroup,按行 ID 对齐,并通过 Manifest 显示。旧的标题栏、标量元数据栏和原始嵌入栏无需移动。
回填不应需要客户端更新循环
许多人工智能数据更新都是回填。一个团队可能会在混合搜索变得重要后添加稀疏向量。它可能会在新模型训练完成后添加 Rerankers 特征。它可能会在人工审核后更正标题。在政策更新后,可能会添加管理标签。
在传统布局中,即使数据是由 Spark、Ray 或其他外部引擎生成的,这些变化也往往是通过客户端 SDK 更新或纯数据库写入路径发生的。
有了 Loon,外部计算系统可以生成新的 ColumnGroups,并通过 Manifest 提交。数据库不再是每次重写的唯一入口。
离线分析不需要另一份真相副本
以前,团队经常将一个在线 Collections 倾倒到 Parquet 中,用于离线评估或分析。这样就会产生同一数据集的两个版本:在线 Collections 和分析副本。一旦标题被修正、Embeddings 被重新生成、删除日志被应用或索引被重建,团队就必须询问哪个副本是最新的。
通过基于 Manifest 的存储模型,分析引擎可以读取与服务系统相同版本的数据集视图。它们可以只预测需要的列,只扫描相关的行范围,并根据已声明的数据集版本而不是手动导出的快照进行工作。
删除和更正应只涉及已更改的内容
在人工智能数据集中,删除、标题更正、标签修复和治理更新都是例行工作。它们不应该强迫每个长向量列通过相同的重写路径。
有了 Loon,删除日志首先可以被视为逻辑删除。之后的压缩可以在不重写无关数据的情况下清理受影响的列组(ColumnGroups)。如果一个简短的文本字段发生变化,存储层就不应该因为它们共享同一逻辑行而重写数百千兆字节的密集向量。
外部引擎成为工作流的一部分,而不是逃生门
更大的转变是,外部引擎不再被视为向量数据库之外的系统。
Spark、Ray、评估作业、标签系统和治理管道已经产生并修改了很多数据。存储层应使它们能够围绕单一真相源进行协作,而不是不断地导出、复制和重新导入。
这正是 Manifest 版本所能实现的。它为在线服务、离线分析、回填作业和压缩提供了数据集的共享视图。
这些听起来像是内部存储细节,但它们会影响团队迭代人工智能数据集的速度。每一次模型更改、特征回填、标题校正、质量过滤器和索引重建都取决于同一个问题:"系统能否在不移动不需要移动的数据的情况下更新数据集? "
这就是存储模型的实用价值。
Loon 可在 Milvus 3.0 测试版和 Zilliz 向量 Lakebase 中使用
Loon 可在Milvus 3.0 测试版中使用,同时也是Zilliz Vector Lakebase(Zilliz Cloud 的下一个演进版本)中存储层的一部分。该版本重点关注三个核心领域:
- 任务(Manifest)。我们的目标是让写入、回填、删除、统计和索引更新产生版本化的数据集视图,让读者可以一致地打开这些视图。对于读者来说,这意味着查询可以打开特定的 Manifest 版本,并看到稳定的数据集视图。对于写入者来说,这意味着可以先准备好新的数据文件、删除日志、统计数据或索引文件,然后通过版本化提交使其可见。
- 支持 ColumnGroup 和格式。Parquet 支持标量列和生态系统友好列。Vortex 支持重向量访问模式。Lance 可以只读模式集成,以便与现有的 Lance 数据集兼容。
- 湖泊索引标量统计、过滤索引和文本反转索引可按行范围参与基于 Manifest 的规划。Lake 本地的向量索引参与度更高。HNSW 和 IVF 在对象存储上有不同的行为,尤其是 HNSW 对随机存取和高速缓存的本地性非常敏感。它不能简单地重复使用为本地固态硬盘设计的布局,并期望得到相同的结果。
未来仍有工作要做
- 外部写入路径很重要,因为 Spark 和 Ray 应该能够生成 ColumnGroups 和 Manifest commits,而无需通过客户端 SDK 循环强制进行每次回填。
- Lakehouse 互操作性很重要,因为许多团队已经在使用目录和查询引擎,如Iceberg、Delta Lake、Trino、DuckDB 和 Athena。向量数据应该能够参与到该生态系统中,而不会损失向量搜索性能。
- 索引布局很重要,因为图索引和反转结构在对象存储上具有不同的访问模式。
- 大型对象语义很重要,因为原始视频、PDF、图像和音频文件需要与衍生向量数据集一致的引用管理、版本管理和删除行为。
确切的发布行为、默认设置和迁移路径应遵循相关的 Milvus 和Zilliz Cloud 发布说明。不过,存储方向是明确的:向量数据库需要一个服务层下的版本化、湖原生基础。
在 Zilliz 向量 Lakebase 下试用 Loon
如果你当前的堆栈将在线服务、离线分析、回填和外部数据湖工作流分离到不同的系统中,那么 Zilliz Vector Lakebase 值得一试。您可以在Zilliz Cloud 中试用。新注册的工作电子邮件可获得 100 美元的免费积分。也欢迎您与我们讨论您的使用案例。
您还可以关注Milvus 3.0 版本,了解 Loon 如何在开源引擎中发展。
Zilliz Vector Lakebase 汇集了:
- 针对不同实时性能和成本权衡的分层服务
- 针对大规模或探索性工作负载的按需搜索,无需始终在线计算
- 外部数据湖搜索,因此您可以直接对现有数据湖数据进行索引和搜索
- 跨向量、文本、JSON 和地理空间数据的全方位搜索,以及混合检索和重新排序
- 基于 Vortex 的统一数据湖本地存储,Vortex 是一种开放格式,专为更快、更低成本地随机读取向量密集型数据而设计
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word



