Почему мы создали Loon: механизм хранения данных ИИ, который никогда не перестает меняться.
Этот блог был первоначально опубликован на сайте zilliz.com и переиздан с разрешения.
Основные выводы
Это долгое, глубокое погружение в инженерные вопросы, поэтому прежде чем мы перейдем к деталям, приведем основные моменты.
- Наборы данных ИИ - это не статичные таблицы. Одни и те же строки постоянно меняются по мере того, как команды заменяют модели встраивания, добавляют разреженные векторы, пересматривают подписи, заполняют метки, перестраивают индексы и проводят автономный анализ.
- Традиционные схемы хранения ломаются по трем причинам: длинные векторные столбцы делают обратное заполнение дорогим, один формат файла не может хорошо обслуживать сканирование и точечное чтение, а частное хранение в базе данных вынуждает внешние конвейеры создавать дополнительные копии истины.
- Loon - это новый механизм хранения данных для Milvus и Zilliz Vector Lakebase. Он построен на гибридных форматах файлов, выравнивании идентификаторов строк и манифесте, определяющем версионное состояние набора данных.
- Цель состоит в том, чтобы сделать единый векторный набор данных способным поддерживать онлайн-поиск, офлайн-анализ, обратное заполнение, уплотнение и внешние вычисления без постоянного копирования, переписывания или повторного импорта данных.
Введение
Некоторое время аргументы против векторных баз данных звучали разумно.
Традиционные базы данных уже хранят целые числа, строки, JSON, блобы и индексы. Почему бы не добавить тип _vector_ , построить рядом с ним ANN-индекс и на этом закончить?
Для раннего семантического поиска это работает достаточно хорошо. Векторный столбец плюс индекс могут поддержать демо-версию, небольшое приложение RAG или функцию внутреннего поиска. Проблема проявляется позже, когда набор данных начинает вести себя не как таблица, а как система данных искусственного интеллекта.
В производственном векторном наборе данных есть строки, первичные ключи, скалярные поля и столбцы для запросов. В этом смысле он похож на таблицу базы данных. Но он также имеет масштаб и форму рабочего процесса озера данных. Она может содержать сотни миллионов записей. Его многократно читают и переписывают Spark, Ray, DuckDB, конвейеры обучения, задания по оценке и системы качества данных.
Он также зависит от объектного хранения. Исходными объектами часто являются видео, изображения, PDF-файлы, аудиофайлы или веб-документы, которые хранятся в S3, GCS, OSS или другом объектном хранилище. В базе данных хранятся ссылки, метаданные, производные характеристики и индексы. Затем в нее добавляются вещи, которыми традиционные модели хранения не могли управлять как первоклассными объектами: плотные вкрапления, разреженные векторы, подписи, векторные индексы, текстовые индексы, журналы удаления, статистика, версии моделей, версии парсеров, ссылки на внешние блобы и отношения версий между всеми этими объектами.
Именно здесь "просто добавьте векторный столбец" начинает рушиться. Вопрос не в том, может ли база данных хранить векторные байты. Многие системы могут. Более сложный вопрос заключается в том , сможет ли модель хранения справиться с тем, как изменяются векторные данные, как к ним обращаются и как они распределяются по стеку данных ИИ.
Именно поэтому мы создали Loon, новый механизм хранения данных для Milvus и Zilliz Vector Lakebase (следующая эволюция Zilliz Cloud).
В основе Loon лежат три идеи:
- Использовать разные физические форматы для разных типов колонок.
- Выравнивать эти столбцы через общее пространство идентификаторов строк.
- Использовать манифест для определения версионного состояния набора данных.
Чтобы понять, почему эти элементы важны, давайте начнем с обычного мультимодального рабочего процесса.
Векторный набор данных никогда не бывает законченным.
Представьте, что команда ИИ создает набор видеоданных для мультимодального обучения.
Длинное видео загружается в объектное хранилище. Конвейер разрезает его на клипы в зависимости от смены сцен, границ кадра или временных интервалов. Слишком длинные или слишком короткие, размытые, дублированные или некачественные клипы отфильтровываются. Оставшиеся клипы оцениваются эстетической моделью, подписываются другой моделью, встраиваются моделью языка зрения и сохраняются в векторной базе данных для поиска, дедупликации и фильтрации обучающих данных.
На первый взгляд, процесс работы прост:
video
→ clips
→ metadata
→ aesthetic_score
→ caption
→ embedding
→ search / dedup / training data filtering
Но набор данных поступает не полностью сформированным.
- В первую неделю таблица может содержать только
clip_id,video_id,start_offsetиduration. - На второй неделе команда добавляет
aesthetic_score. - На третьей неделе запускается модель создания субтитров, и каждый ролик получает
caption. - На четвертой неделе запускается первая модель встраивания, и каждый клип получает 768-мерное встраивание CLIP.
- Через месяц команда переключает модели и заполняет
embedding_v2, теперь уже с 1024 измерениями. - Два месяца спустя гибридный поиск становится обязательным условием, поэтому команда добавляет колонку разреженных векторов.
- Через три месяца подписи проходят человеческую проверку и должны быть исправлены на месте.
Набор данных так и не был завершен. Он продолжал накапливать новые интерпретации одних и тех же строк.
В этом заключается одно из основных отличий векторных данных от традиционных бизнес-данных. Один и тот же ряд обрабатывается снова и снова. А масштаб превращает это из неудобства в проблему хранения: мультимодальные наборы данных зачастую насчитывают не миллионы записей, а сотни миллионов или миллиарды. LAION-5B является полезным эталоном формы - миллиарды пар изображение-текст, каждая с метаданными, подписями и вкраплениями. Так что самое сложное - это не первая вставка. Самое сложное - это все, что происходит после того, как набор данных начинает развиваться. Это развитие выявляет три проблемы.
Первая проблема: длинные столбцы делают усиление записи дорогим.
Колоночные форматы, такие как Parquet, отлично подходят для многих аналитических нагрузок. Они хорошо работают, когда схемы достаточно стабильны, данные чаще читаются, чем переписываются, сканирование затрагивает только подмножество столбцов, а сжатие имеет значение. Именно для такого мира были оптимизированы многие аналитические форматы.
Векторные строки намного шире аналитических.
TPC-H lineitem - хороший базовый вариант. В нем 16 столбцов: целочисленные ключи, десятичные значения, даты, короткие строки и небольшое поле для комментариев. Одна несжатая строка занимает примерно 150 байт. После сжатия она может быть гораздо меньше. При использовании группы строк размером 64 МБ система хранения может упаковать в одну группу сотни тысяч строк.
Векторные наборы данных выглядят иначе.
Набор изображений и текстов в стиле LAION гораздо ближе к тому, что сегодня производят многие конвейеры ИИ. Каждая строка по-прежнему содержит обычные метаданные: URL, подпись, ширину, высоту, оценку качества, метки и так далее. Но после добавления вставки физическая форма строки меняется.
768-мерный вектор CLIP занимает около 1,5 КБ в fp16 или 3 КБ в fp32. Один такой столбец может быть гораздо больше, чем вся строка TPC-H lineitem.
И 768 измерений не являются чем-то необычным или большим по сегодняшним меркам. В мультимодальных конвейерах часто встречается 1024- или 2048-мерное вложение. OpenAI's text-embedding-3-large достигает 3072 измерений, что составляет около 12 КБ на вектор в fp32.
Сравнение разительное:
| Форма набора данных | Приблизительный размер ряда | Что доминирует в ряду |
|---|---|---|
| Линейный элемент TPC-H | ~150 байт без сжатия | скалярные и короткие строковые поля |
| Строка в стиле LAION с 768-мерным вектором fp16 | ~1,5 КБ+ | встраивание |
| Строка в стиле LAION с вектором 768-dim fp32 | ~3 КБ+ | встраивание |
| Строка с вектором 3072-dim fp32 | ~12 КБ+ только для вектора | встраивание |
Во многих наборах данных ИИ столбец с вектором - это не просто еще одно поле. Физически он составляет большую часть строки. Это меняет стоимость эволюции схемы.
Добавление одного векторного столбца может означать сотни гигабайт.
Предположим, в наборе данных 100 миллионов видеоклипов. Добавление нового 1024-мерного столбца встраивания fp32 означает запись примерно 400 ГБ необработанных векторных данных. Это без учета статистики, индексов, обновлений метаданных, накладных расходов на хранение объектов, проверку и интеграцию путей обслуживания.

Если команда ежемесячно добавляет один или два вектороподобных столбца, например embedding_v2, sparse_vector или функции rerank, эволюция схемы превращается в повторяющуюся инженерную работу daAta, измеряемую сотнями гигабайт или терабайтами.
Небольшие логические обновления могут вызвать большие физические перезаписи
Обновления не менее важны.
В столбцовых системах старые данные обычно не обновляются на месте. В журнале удаления записывается, что изменилось, а позднее уплотнение переписывает живые строки в новые файлы. Такая модель удобна, когда строки невелики.
При векторных данных небольшое логическое обновление может вызвать большую физическую перезапись.
Человек, выполняющий рецензирование, может исправить всего несколько сотен байт в надписи. Но если надпись, плотный вектор, разреженный вектор и другие производные характеристики имеют один и тот же жизненный цикл физического файла, система может в итоге переписать и векторы. Логическое изменение невелико. А вот физический ввод-вывод может быть огромным.
Это проблема усиления записи в векторном хранилище. Дорогая часть заключается не только в том, что векторы большие. Дело в том, что большие производные поля и маленькие изменяемые поля часто оказываются связанными вместе при компоновке хранилища, которая рассматривает их как единое целое.
Для наборов данных ИИ обратное заполнение является рутинной рабочей нагрузкой.
Для традиционных аналитических таблиц изменение схемы может происходить лишь изредка. Для наборов данных ИИ это рутинная работа. Модели захвата обновляются. Модели вкраплений заменяются. Позже добавляются разреженные векторы. Появляются реранки признаков. Исправляются человеческие метки. Заполняются теги управления. Индексы перестраиваются.
Эти операции не являются простым добавлением. Они часто изменяют или расширяют существующие строки.
Вот почему векторное хранилище не может оптимизировать только пропускную способность сканирования. Оно также должно удешевить обратное заполнение и частичное обновление.
Вторая проблема: одни и те же данные должны поддерживать сканирование и точечное чтение.
После записи данных путь чтения разделяется. Один и тот же векторный набор данных обычно имеет два разных типа доступа: аналитическое сканирование и точечное чтение.
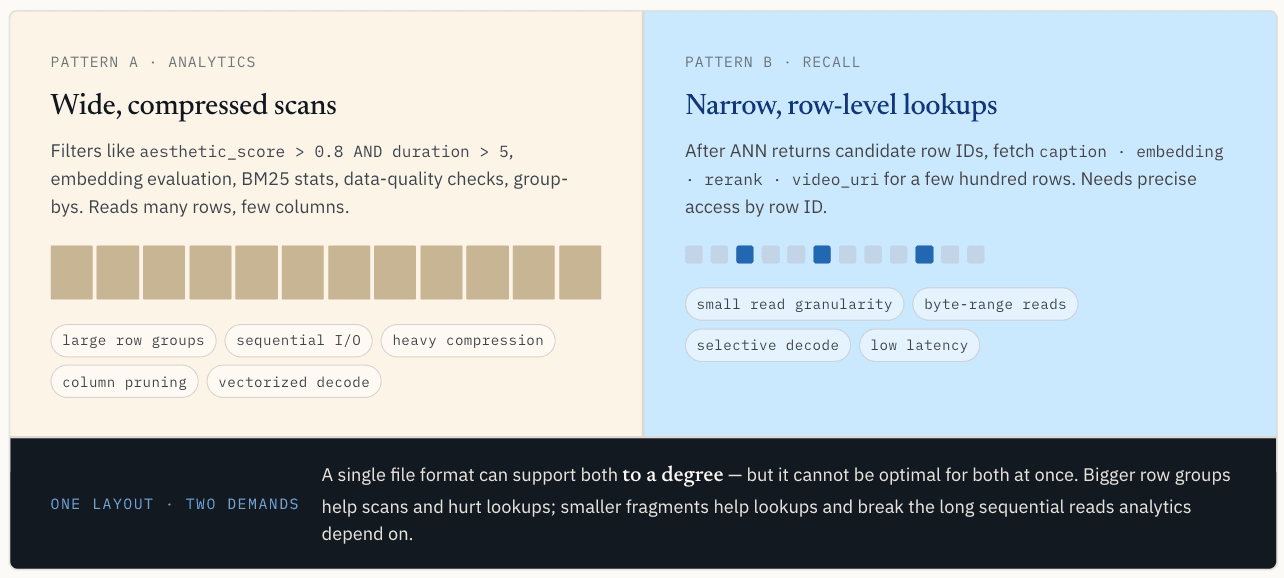
Аналитические рабочие нагрузки требуют широкого, сжатого сканирования.
Конвейер может выполнять такие фильтры, как:
WHERE aesthetic_score > 0.8 AND duration > 5
Или он может выполнять автономный анализ, оценку полного встраивания, статистику BM25, построение растровых изображений, проверку качества данных, подсчеты и группировки.
Этот шаблон считывает много строк, но только несколько столбцов. Он предпочитает последовательный ввод-вывод, большие группы строк, сжатие, обрезку столбцов, пакетное декодирование и векторное выполнение.
Здесь помогают большие группы строк. Они позволяют одному запросу ввода-вывода получить большой объем полезных данных, повышают эффективность сжатия и предоставляют механизму выполнения достаточно связных данных для амортизации накладных расходов. Когда несколько столбцов считываются вместе, их упорядочивание для повышения пропускной способности сканирования также помогает сократить количество пропусков кэша при векторном выполнении.
Parquet силен на этом пути.
Результаты ANN требуют узкого поиска на уровне строк
После того как ANN-поиск возвращает идентификаторы строк-кандидатов, системе часто требуется получить такие поля, как:
caption
embedding
rerank feature
video_uri
metadata
Этот шаблон считывает меньшее количество строк, часто сотни или тысячи, но ему нужен точный доступ по идентификатору строки. Он хочет найти конкретную строку и столбец, получить только нужный диапазон байтов и не тянуть всю группу строк только для того, чтобы получить несколько записей.
Точечный поиск имеет почти противоположные предпочтения по сравнению со сканированием. Ему нужна меньшая детализация чтения. В идеале уровень хранения может найти соответствующий сегмент или диапазон байтов по идентификатору строки, прочитать только этот диапазон и декодировать только те данные, которые нужны для результата.
Сжатие также имеет разные компромиссы. Для сканирования более сильное сжатие часто оправдывает себя, поскольку система считывает много данных и экономит ввод-вывод. Для поиска точек сжатие может стать помехой, если для получения одной строки требуется декодировать гораздо больший сжатый блок.
Одна компоновка не может быть оптимизирована для обоих путей
Это основной конфликт. Скалярная фильтрация и аналитика требуют широких, сжатых, удобных для сканирования макетов. Векторному поиску нужны узкие, точные, адресуемые к строкам макеты.
Один формат файла может поддерживать оба в той или иной степени, но он не может быть оптимальным для обоих одновременно.
Если все столбцы хранятся в Parquet, скалярное сканирование будет удобным. Но поиск ANN после вызова становится сложнее. Системе может понадобиться всего несколько сотен векторов, подписей или записей метаданных, в то время как уровень хранения может быть вынужден читать большие группы строк, содержащие в основном нерелевантные строки.
На локальном SSD кэш и mmap могут скрыть часть этих затрат. Когда данные хранятся в объектном хранилище, затраты становятся более заметными. Каждый промах кэша может превратиться в чтение удаленного диапазона. Если строки-кандидаты разбросаны по многим группам строк, один запрос может вызвать несколько считываний, каждое из которых извлекает больше данных, чем нужно запросу. При плохой компоновке получение 1000 строк-кандидатов может легко привести к десяткам или сотням мегабайт ненужных операций ввода-вывода, а в крайних случаях и гораздо больше.
Уменьшение размера групп строк помогает при поиске, но вредит при сканировании. Слишком большое количество мелких фрагментов снижает эффективность сжатия, увеличивает накладные расходы на метаданные и разрушает длинные последовательные чтения, от которых зависят аналитические системы.
Таким образом, проблема заключается не в том, чтобы найти волшебный размер группы строк. Проблема в том, что один и тот же набор данных должен вести себя как две разные системы хранения.
Гибридный поиск заставляет объединить оба пути в один запрос
При гибридном поиске конфликт сложнее игнорировать. В одном запросе сначала могут применяться скалярные фильтры:
aesthetic_score > 0.8 AND duration > 5
Затем запускается ANN-поиск.
Затем извлекаются надписи, вектор и метаданные по идентификатору строки.
Для пользователя это один поисковый запрос. Для уровня хранения это и аналитическое сканирование, и случайный поиск с низкой задержкой.
Поэтому векторное хранилище нуждается не только в лучшей настройке Parquet. Ему нужен способ размещения различных столбцов в соответствии с тем, как они будут читаться на самом деле.
Третья проблема: набор данных не живет в одном движке
Первые две проблемы возникают внутри базы данных. Третья возникает на границе между системами.

Конвейеры данных ИИ охватывают множество систем
В процессе работы с видео очень мало что происходит в самой векторной базе данных.
Необработанные видеоролики хранятся в объектном хранилище. Генерация клипов может выполняться в Spark или Ray. Эстетическая оценка может выполняться в GPU-сервисе. Создание надписей может выполняться в конвейере вывода LLM. Вкрапления могут быть сгенерированы другой работой GPU. Разреженные векторы могут поступать из сервиса SPLADE. Оффлайн-оценка, фильтрация обучающих данных, человеческий обзор и задания по управлению могут выполняться в другом месте.
Векторная база данных служит для онлайн-поиска, но набор данных создается, корректируется, оценивается и расширяется многими системами.
Частные форматы хранения создают несколько копий истины
Если база данных использует частный физический формат, который может читать и записывать только она, то для каждой внешней работы требуется экспорт, преобразование, копирование и импорт. Одна и та же коллекция может существовать в базе данных, во временной директории Spark, в выходе оценки и в локальной директории резервного копирования. Тогда встает реальный вопрос:
- Какая копия является источником истины?
- Какая из них содержит модель подписи за прошлый месяц?
- Какие строки уже были исправлены человеком?
- Какой столбец разреженного вектора был сгенерирован какой моделью?
- Какой индекс вектора все еще действителен после заполнения?
- К какому исходному видеообъекту относится эта строка?
В небольших масштабах команды иногда могут обойтись соглашениями об именовании и ручными проверками. При наличии сотен миллионов строк и терабайтов вкраплений это становится проблемой согласованности.
Векторные наборы данных нуждаются в общем версионном состоянии
Системы Lakehouse решили одну из версий этой проблемы для структурированных данных. Iceberg, Delta Lake и Hudi - это не просто хранение файлов. Их основной вклад заключается в том, что они позволяют нескольким движкам координировать работу с одним и тем же состоянием таблицы.
Векторные базы данных теперь нуждаются в аналогичной возможности, но состояние более сложное. Оно должно включать не только файлы таблиц и разделы, но и векторные индексы, текстовые индексы, разреженные функции, журналы удаления, статистику, диапазоны идентификаторов строк и ссылки на внешние блобы.
Вопрос не просто в том, "может ли Spark читать файлы Milvus?".
Вопрос в том, что после того, как Spark заполнит столбец разреженного вектора, как Milvus узнает, к какой версии принадлежит этот столбец, какие строки он охватывает, какая модель его создала и когда онлайновые запросы могут безопасно его использовать?
Ответ должен находиться в модели хранения.
Почему исправлений недостаточно
Заманчиво рассматривать эти проблемы как три отдельные инженерные проблемы.
- Усиление записи? Добавьте пакетную обработку.
- Точечное чтение? Добавьте кэш.
- Внешние системы? Добавьте инструменты экспорта и импорта.
Эти исправления могут помочь, но они не решают основную проблему: векторный набор данных физически неоднороден.

В видеопримере clip_id, video_id, duration и aesthetic_score - это короткие скалярные поля. Они полезны для фильтрации и анализа.
captionэто текст. Его можно использовать для BM25, просмотра, исправления и заполнения.embeddingдлинный плотный вектор. Используется для отзыва ANN, а затем для поиска на уровне рядов или повторного ранжирования.embedding_v2новый вывод модели, часто заполняемый спустя долгое время после вставки исходных данных.sparse_vectorПоддерживает гибридный поиск и имеет свой собственный шаблон доступа.- Необработанное видео должно оставаться в объектном хранилище. База данных должна хранить ссылку, контрольную сумму, тип MIME, версию парсера и отношения на уровне строки.
- Векторные индексы, текстовые индексы, статистика и журналы удаления - это производные объекты со своей собственной семантикой версий.
Эти объекты имеют общую логическую строку, но не должны иметь одинаковое физическое расположение или жизненный цикл.
- Если их принудительно поместить в одну обычную таблицу, обновления станут дорогими.
- Если их принудительно поместить в один формат колоночного файла, то точечные чтения станут дорогими.
- Если их рассматривать как несвязанные объектные файлы, управление версиями становится хрупким.
Поэтому модель хранения должна исходить из того, что набор данных неоднороден.
Это приводит к трем требованиям к проектированию:
- Во-первых, разные группы столбцов должны храниться в разных физических форматах.
- Во-вторых, этим группам столбцов необходимо общее пространство идентификаторов строк, чтобы они могли вести себя как единая логическая таблица.
- В-третьих, набору данных необходим версионный манифест, в котором объявляется, какие файлы, индексы, журналы, статистика и ссылки на объекты принадлежат текущему представлению.
Именно такой дизайн лежит в основе Loon, нашего нового механизма хранения данных для Milvus и Zilliz Cloud.
Loon: механизм хранения Milvus и Zilliz Cloud для эволюционирующих векторных наборов данных
Чтобы решить все вышеперечисленные проблемы, мы создали Loon, новый механизм хранения данных для Milvus и Zilliz Vector Lakebase (следующая эволюция Zilliz Cloud), предназначенный для эволюционирующих векторных наборов данных.
Название следует традициям Zilliz по именованию птиц. Гагара - это ныряющая птица, которая живет на озерах, что вполне соответствует цели системы: векторная база данных не должна перемещаться, сканировать или переписывать все озеро данных каждый раз, когда она выполняет запрос, заполняет столбец или строит индекс. Сначала она должна понять текущую версию набора данных, включая его столбцы, индексы, статистику, журналы удаления и ссылки на объекты, а затем считывать только ту часть, которая ей действительно нужна.
Гибридные форматы файлов, выравнивание идентификаторов строк и Manifest - это не три отдельные функции. Они вытекают из одного и того же предположения: векторный набор данных по своей природе неоднороден.
Три части, одна модель хранения
Гибридные форматы файлов признают, что разные столбцы имеют разные шаблоны доступа. Скалярные поля хороши для сканирования и фильтров. Векторные поля требуют эффективного поиска на уровне строк. Необработанные объекты, такие как видео, PDF-файлы, изображения и аудиофайлы, должны храниться в объектном хранилище, а не в файлах данных базы данных.
Выравнивание идентификаторов строк признает, что эти столбцы могут быть физически разделены, но они все равно описывают одни и те же логические строки. Надпись, вставка, разреженный вектор и URI видео могут находиться в разных файлах и форматах, но их все равно нужно собрать в единый результат.
В манифесте признается, что набор данных не пишется один раз и не оставляется в покое. Он будет изменен множеством систем, в нескольких версиях, для множества задач. Индексы, статистика, журналы удаления, ссылки на внешние объекты и группы столбцов должны отображаться в одном и том же версионном представлении.
Вот почему Loon - это не просто более быстрый формат векторных файлов. Более быстрый формат помогает в поиске точек, но не решает проблемы эволюции схемы или координации работы нескольких машин. Выравнивание идентификаторов строк позволяет разделенным столбцам вести себя как единая таблица, но не указывает, какие файлы относятся к текущей версии. Манифест может описывать состояние набора данных, но без групп столбцов и выравнивания идентификаторов строк он не может чисто представлять различные физические компоновки внутри одной логической коллекции.
В модели хранения нужны все три составляющие: разные форматы для разных групп столбцов, общее пространство идентификаторов строк для реорганизации строк и версионный манифест, который сообщает каждому читателю и писателю, в каком состоянии находится набор данных.
Как Loon вписывается в Milvus и Zilliz Vector Lakebase
В Milvus он заменяет старый слой хранения сегментного бинлога моделью, построенной на основе Manifest, ColumnGroup, формата файла и абстракций файловой системы. В Zilliz Vector Lakebase (следующая эволюция Zilliz Cloud) архитектура Vector Lakebase построена в том же направлении: сохраняйте скорость обслуживания векторной базы данных, одновременно упрощая эволюцию, анализ и координацию базовых данных с внешними системами.
Компоненты Milvus верхнего уровня сохраняют свои привычные роли. Прокси управляет маршрутизацией. QueryCoord и DataCoord занимаются планированием. IndexNode создает индексы. Прикладным API для коллекций, вставок, поиска и гибридного поиска не нужно открывать файлы Manifest или ColumnGroups.
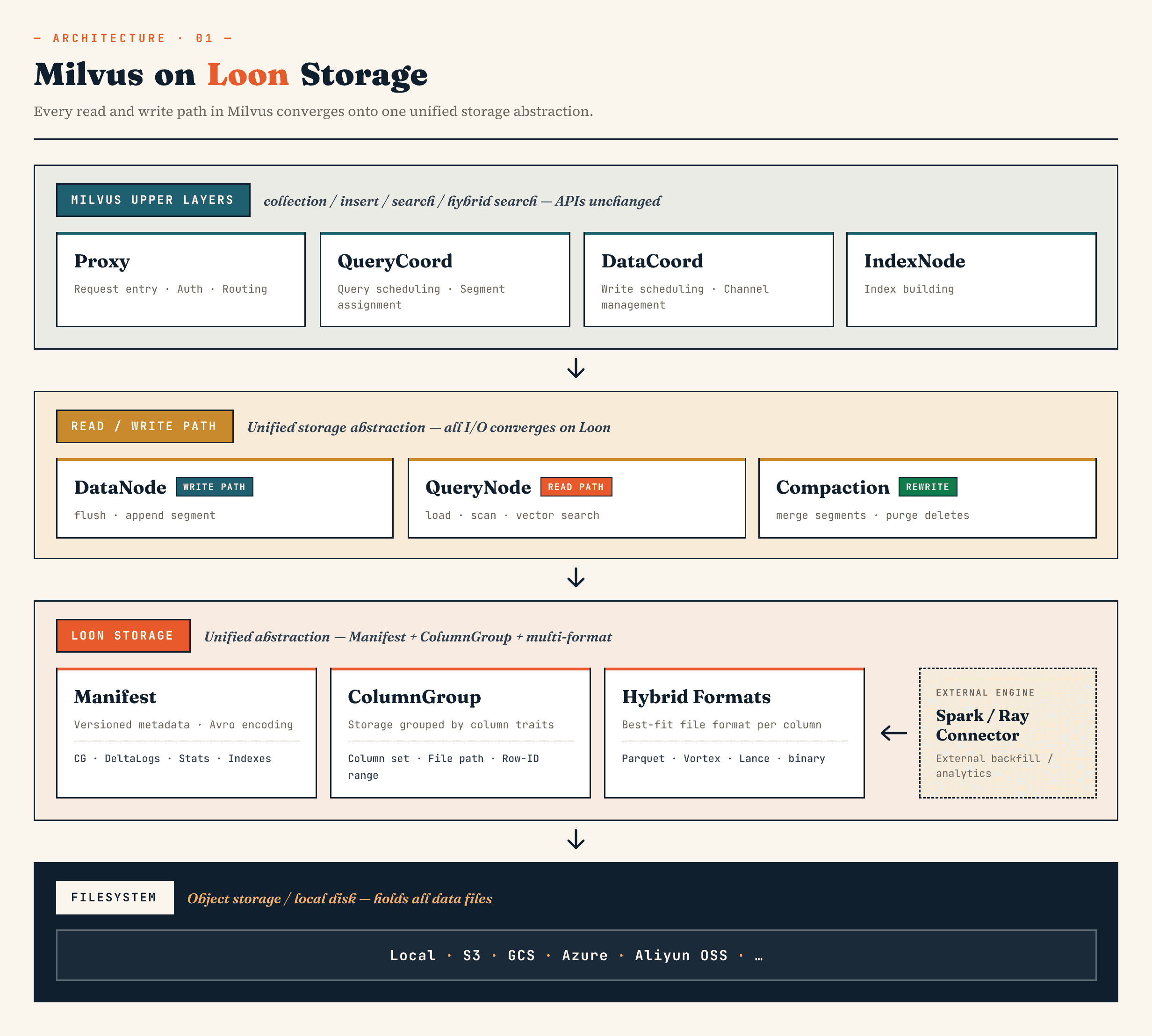
Изменения заключаются в следующем.
DataNode, QueryNode, segcore, compaction и внешние коннекторы могут работать через одну и ту же абстракцию хранения. Это важно, потому что набор данных больше не записывается и читается только базой данных. Он может расширяться внешними вычислительными системами и одновременно потребляться онлайн-поиском.
На высоком уровне слои выглядят следующим образом:
Manifest
→ ColumnGroup
→ file format layer
→ filesystem abstraction
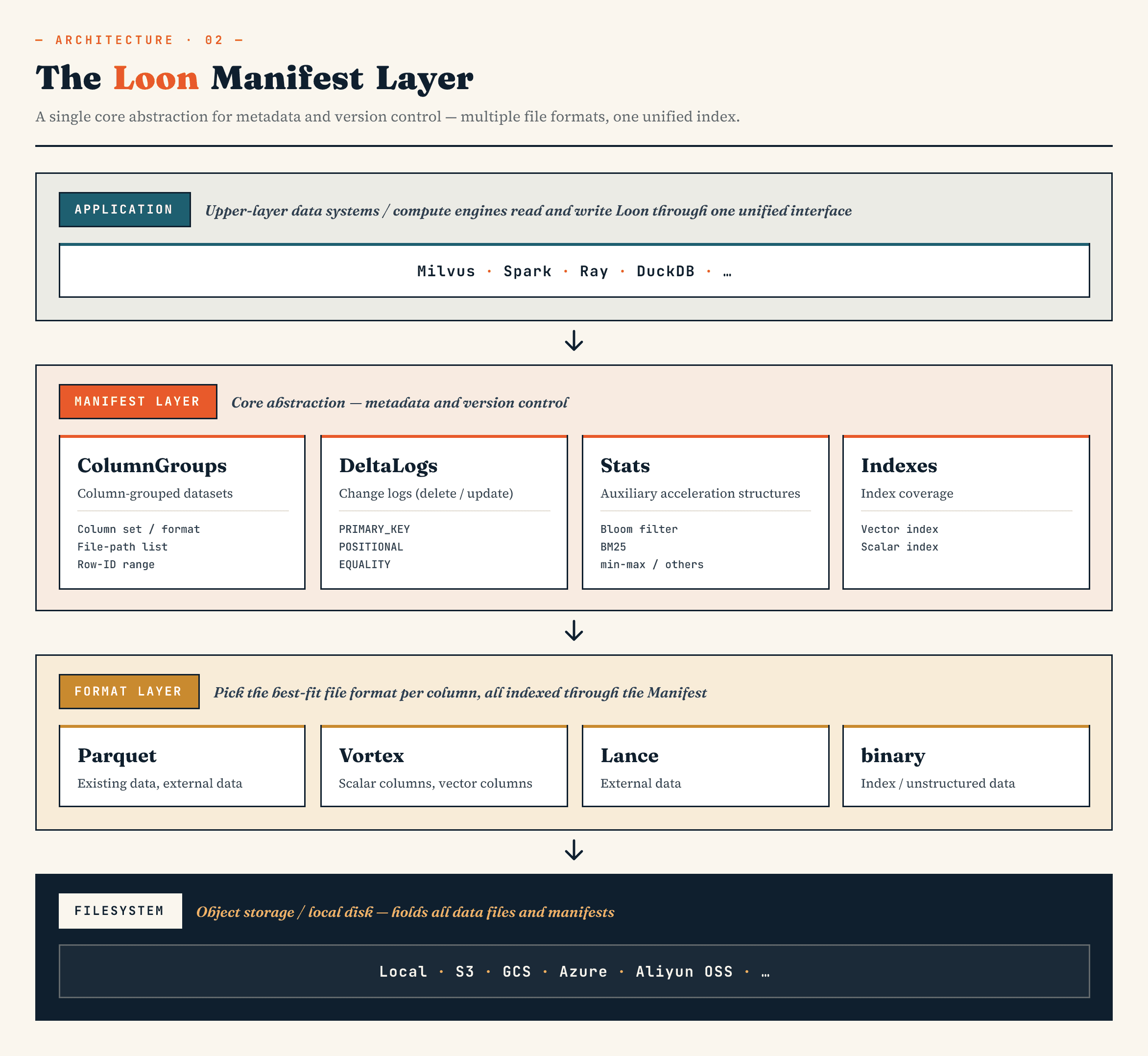
Manifest описывает версионное состояние набора данных. ColumnGroups отображает логическую коллекцию на физические группы столбцов. Уровень формата файлов позволяет каждой группе ColumnGroup выбрать подходящий формат. Абстракция файловой системы работает как в объектном, так и в локальном хранилище.
Важно отметить, что гибридные форматы файлов, выравнивание идентификаторов строк и Manifest не являются отдельными функциями. Вместе они определяют модель хранения.
Имея такую модель, мы можем рассмотреть три варианта дизайна по очереди: как Loon хранит различные ColumnGroups, как выравнивает их обратно в строки и как Manifest превращает эти файлы в версионный набор данных.
Дизайн 1: используйте правильный формат файла для правильной группы столбцов
Разные столбцы имеют разные шаблоны доступа. Их не следует принудительно помещать в один и тот же формат файла.
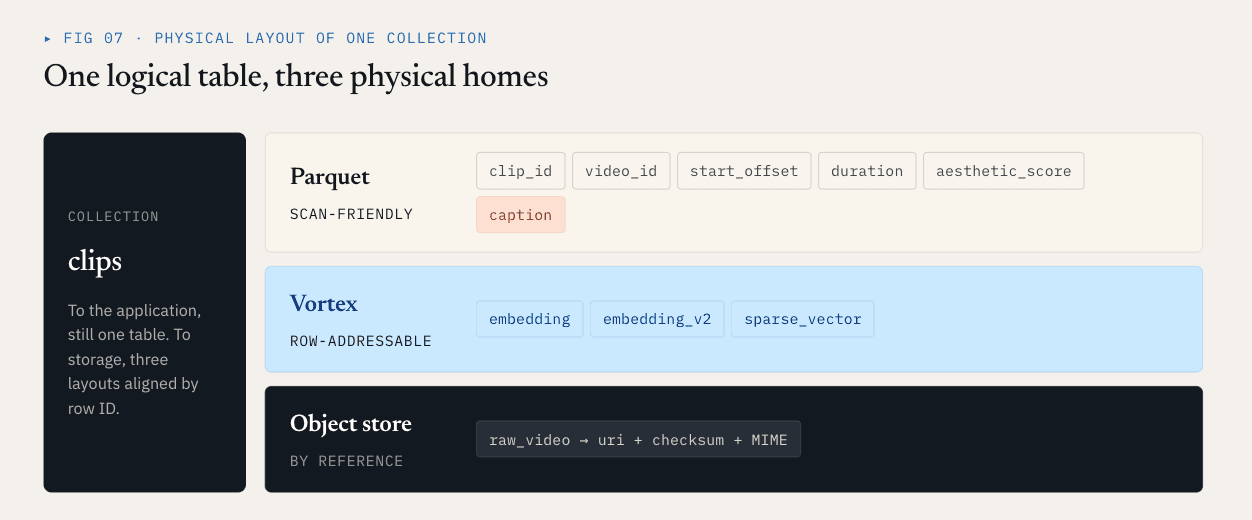
Loon разделяет логическую коллекцию на группы столбцов (ColumnGroups).
- Скалярные поля, поля фильтрации, бизнес-ключи и статистические поля часто сканируются, фильтруются, агрегируются или используются для планирования запросов. Они выигрывают от сжатия, обрезки столбцов и совместимости с экосистемой. Parquet хорошо подходит для этих столбцов.
- Плотные векторы, разреженные векторы и ранжированные признаки часто считываются после отзыва ANN по идентификатору строки. Они нуждаются в произвольном доступе с низкой задержкой, точном чтении в байтовом диапазоне и выборочном декодировании. Лучше всего подходит сегментно-ориентированная компоновка. В этом направлении Loon использует Vortex.
- Необработанные объекты, такие как видео, PDF, изображения и аудиофайлы, не должны встраиваться в файлы данных векторной базы данных. Они должны оставаться в объектном хранилище. В базе данных записываются ссылки, контрольные суммы, типы MIME, версии парсера и отношения на уровне строк.
Для примера с видео физическая схема может выглядеть следующим образом:
Parquet ColumnGroup:
clip_id / video_id / start_offset / duration / aesthetic_score / caption
Vortex ColumnGroups:
embedding
embedding_v2
sparse_vector
Object storage:
raw video objects
Для приложения это все еще одна коллекция. Для уровня хранения разные части этой коллекции используют разные физические форматы. Это напрямую сокращает количество ненужных перезаписей. Добавление embedding_v2 может стать новым вектором ColumnGroup плюс фиксация Manifest. Для этого не нужно переписывать колонку с надписями, скалярные метаданные или существующую колонку с вложениями.
Та же идея применима к разреженным векторам, признакам rerank и другим производным полям. Если новый столбец может быть физически независимым и выровненным по идентификатору строки, ему не придется протаскивать несвязанные столбцы через тот же путь перезаписи.
Loon также адаптирует использование форматов файлов.
Для Parquet настройки по умолчанию не всегда идеально подходят для векторных данных. Группа строк размером 64 МБ может оказаться слишком большой для поиска точек, поскольку при небольшом случайном чтении может быть получено гораздо больше данных, чем нужно. Loon ограничивает группы строк до 1 МБ в соответствующих путях и отключает кодировки, такие как словарная кодировка на векторных столбцах, если они не помогают в работе с векторными данными, имеющими случайный вид.
Для Vortex более важной работой является компоновка. Loon использует компоновку, в которой сбалансированы эффективность сканирования и поиск точек. Внутри группы строк сегменты из смежных столбцов могут быть расположены близко друг к другу, чтобы поддерживать сканирование. Для выполнения операций чтение подсегментов позволяет системе извлекать только нужные байты, а не тянуть весь сегмент.
Loon также поддерживает интеграцию с Lance только для чтения, поэтому существующие наборы данных Lance можно монтировать как ColumnGroups, когда совместимость имеет значение.
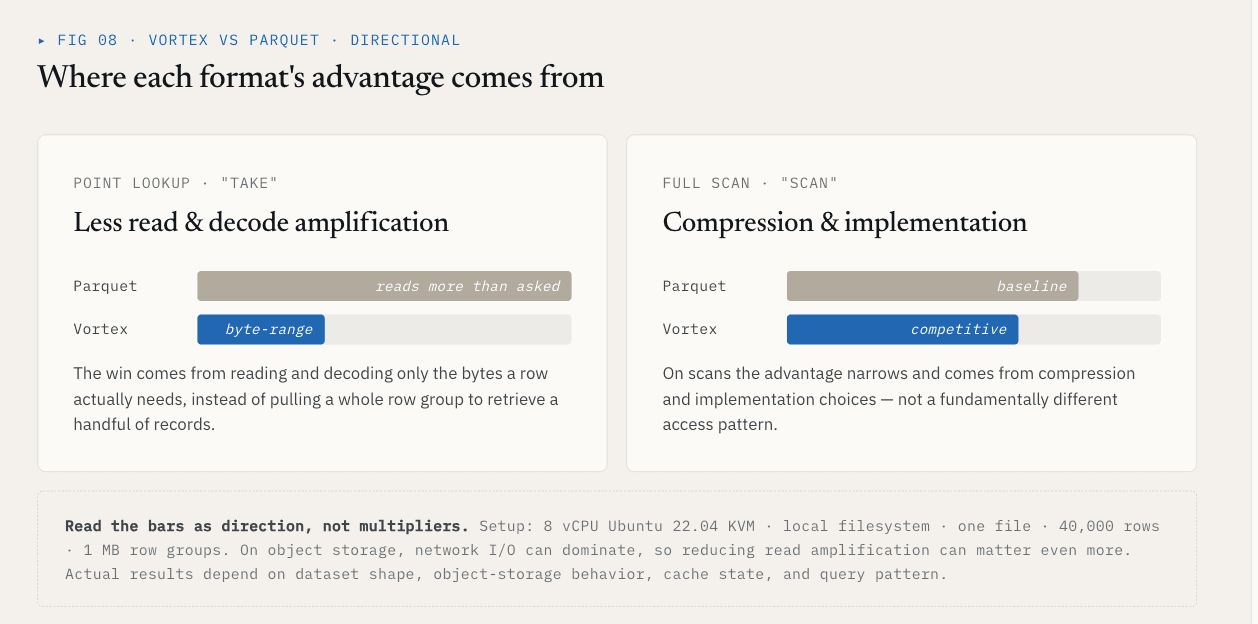
Что показывает бенчмарк
В одном из локальных тестов, используя один файл с 40 000 строк и схемой {id: int64, name: utf8, value: float64, vector: list<float32>[128]}, Vortex показал следующие результаты в сравнении с Parquet с группами строк размером 1 МБ:
| Операция | Vortex | Parquet | Разница |
|---|---|---|---|
| Взять, K=1000 случайных строк | 5,8 мс | 144 мс | В 25 раз быстрее |
| Полное векторно-колоночное сканирование | 21 мс | 142 мс | 6,76x быстрее |
| Размер файла, ~21 МБ необработанных данных | 6,62 МБ | 7,16 МБ | На 7 % меньше |
Результат take обусловлен уменьшением количества нерелевантных данных, которые необходимо считывать и декодировать. Результат сканирования зависит от сжатия и выбора реализации.
Эти цифры должны оставаться привязанными к их настройкам: 8 vCPU Ubuntu 22.04 KVM, локальная файловая система, один файл, 40 000 строк, группы строк по 1 МБ и приведенная выше схема. В объектных хранилищах сетевой ввод-вывод может доминировать, поэтому снижение усиления чтения может иметь еще большее значение. Фактические результаты зависят от формы набора данных, поведения объектного хранилища, состояния кэша и шаблона запроса.
Суть не в том, что каждый столбец должен использовать Vortex.
Суть в том, что векторные наборы данных нуждаются в выборе формата файла на уровне ColumnGroup.
Дизайн 2: выравнивание физических файлов через идентификаторы строк
Гибридные форматы файлов решают одну проблему: разные столбцы теперь могут жить в тех форматах, которые подходят им лучше всего.
Но это создает вторую проблему. Если скалярные поля живут в Parquet, векторы - в Vortex, а необработанные объекты - в объектном хранилище, как система будет по-прежнему рассматривать их как одну коллекцию?
Loon решает эту проблему с помощью выравнивания по идентификатору строки.
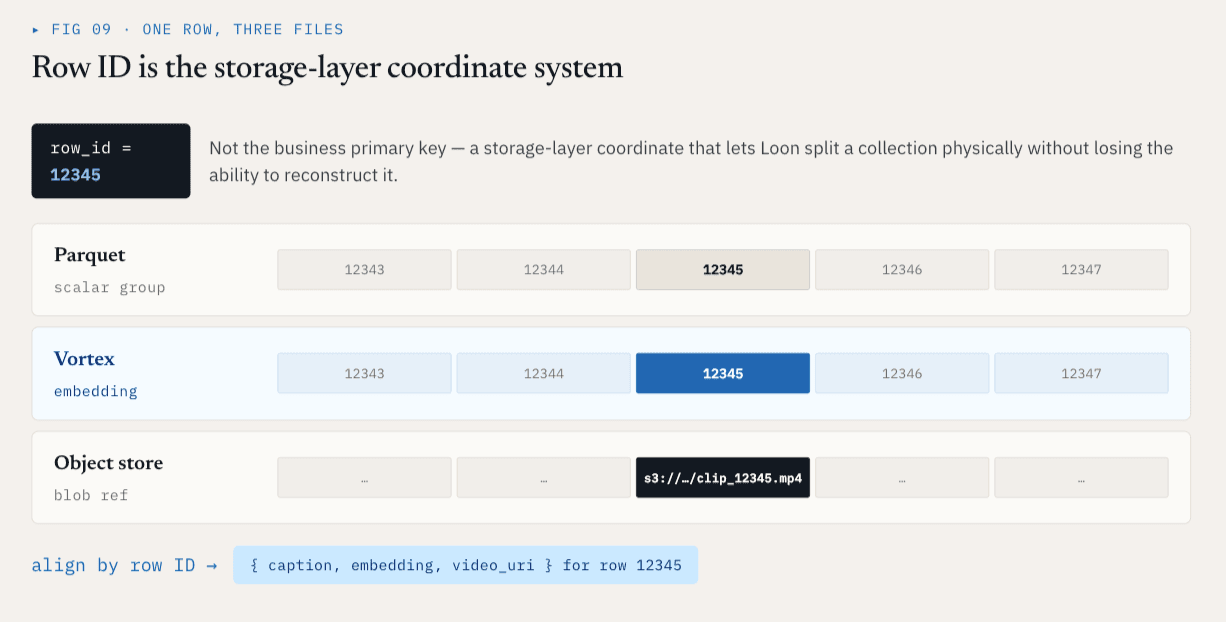
Идентификатор строки - это система координат слоя хранения.
Каждый физический файл ColumnGroupFile записывает путь к файлу и диапазон идентификаторов строк, который он охватывает:
path
start_index
end_index
Различные ColumnGroups могут охватывать одно и то же пространство ID строки, даже если они находятся в разных файлах и форматах.
Для идентификатора строки 12345 скалярные метаданные могут находиться в Parquet ColumnGroup, вложения - в Vortex ColumnGroup, а необработанное видео - в ссылке на объектное хранилище. Логически они все равно представляют собой одну строку. Это дает слою хранения стабильную систему координат.
Идентификатор строки не является первичным ключом в бизнесе. Это система координат слоя хранения, которая позволяет Loon разделить коллекцию физически, не теряя возможности восстановить ее логически.
Новые столбцы не требуют переписывания старых столбцов
Добавление embedding_v2 не требует переписывания исходной надписи, метаданных или embedding_v1 ColumnGroups. Loon может написать новый вектор ColumnGroup, записать диапазон идентификаторов строк, который он охватывает, и зафиксировать это изменение через Manifest.
То же самое относится к разреженным векторам, характеристикам rerank или другим производным полям, которые будут получены позже.
Если новая группа ColumnGroup охватывает правильный диапазон идентификаторов строк, она может присоединиться к той же логической коллекции, не заставляя перемещать несвязанные данные.
Удаление и уплотнение могут быть более целенаправленными
Выравнивание идентификаторов строк также помогает при удалении.
Сначала удаление может быть выражено через журнал удаления. Строка становится невидимой на логическом уровне, а физическая очистка откладывается до уплотнения. Когда уплотнение в конце концов выполняется, ему не всегда нужно переписывать все ColumnGroup, привязанные к затронутым строкам. Она может сосредоточиться на тех ColumnGroup, которые нуждаются в очистке.
Это важно, поскольку не каждый столбец имеет одинаковый профиль затрат. Переписывание короткой скалярной ColumnGroup сильно отличается от переписывания сотен гигабайт плотных векторов.
Гибридный поиск может получить только те столбцы, которые ему нужны
Выравнивание идентификаторов строк - это также то, что делает гибридный поиск практичным поверх гибридных форматов файлов.
После того как ANN-поиск возвращает идентификаторы строк-кандидатов, система может получить только те поля, которые необходимы для конечного результата: подписи, метаданные, векторы, характеристики ранжирования или ссылки на объекты.
Например, в запросе может потребоваться:
caption
embedding
video_uri
Эти поля могут находиться в разных ColumnGroups. Loon может найти соответствующие файлы по диапазону идентификаторов строк, считать необходимые диапазоны байтов и собрать результат.
Без выравнивания идентификаторов строк гибридные форматы были бы просто отдельными файлами, расположенными рядом друг с другом. С выравниванием идентификаторов строк они ведут себя как единая логическая коллекция.
Packed Reader скрывает разделение от верхнего уровня.
Компонент времени выполнения, который делает это удобным, - Packed Reader.
Верхний уровень видит единый поток Arrow RecordBatch. Под ним данные могут поступать из нескольких ColumnGroups в разных форматах файлов. Packed Reader скрывает эти различия, выравнивает данные по диапазонам row-ID и планирует многофайловый ввод-вывод с контролируемым использованием памяти.
Он также поддерживает прямой take по идентификатору строки. Получив набор идентификаторов строк, он находит соответствующие файлы ColumnGroupFiles, выполняет чтение диапазона и возвращает запрашиваемые поля.
Для рабочего процесса с видео в запросе ANN могут потребоваться caption, embedding и video_uri. Packed Reader может получить скалярную ColumnGroup и векторную ColumnGroup, не затрагивая несвязанные столбцы.
В этом и заключается разница между "отдельными файлами" и "таблицей с несколькими физическими макетами".
Дизайн 3: сделайте манифест источником истины
Гибридные форматы файлов определяют, как физически хранятся данные. Выравнивание идентификаторов строк определяет, как разделенные группы столбцов образуют единую логическую таблицу. Но система все равно должна ответить на более важный вопрос: какие файлы, журналы, статистика, индексы и ссылки на объекты принадлежат текущей версии набора данных? Это задача манифеста.

Каталогов объектного хранилища недостаточно
Хранилище объектов - это не каталог базы данных. Каталог может содержать старые файлы, новые файлы, результаты неудачных заданий, временные файлы, журналы удаления, файлы, на которые все еще ссылаются старые снимки, и файлы, ожидающие очистки. Тот факт, что файл существует, не означает, что он принадлежит к текущей версии набора данных.
Набор данных Loon может быть организован в такие каталоги, как:
_metadata/
_data/
_delta/
_stats/
_index/
Но структура каталогов не является источником истины. Манифест является таковым. Читатели не должны перечислять каталоги и делать выводы о состоянии на основе любых случайно существующих файлов. Они должны читать текущий манифест и следовать версионности, которую он декларирует.
Манифест определяет одно версионное представление набора данных
Манифест определяет набор данных в данной версии. В нем записано:
- какие ColumnGroups существуют
- какие диапазоны идентификаторов строк они охватывают
- какой физический формат использует каждая ColumnGroup
- где находятся файлы
- какие журналы удаления активны
- какая статистика доступна
- какие индексы существуют
- на какие внешние блобы есть ссылки
- какие столбцы и диапазоны строк охватывают эти статистики или индексы.
При каждом обновлении записывается новая версия манифеста. Читатель, открывший версию N, видит стабильное представление набора данных в версии N. Писатель может подготовить версию N+1, не мешая читателям, которые все еще используют версию N.
Манифест отслеживает не только файлы таблиц
В Loon тело манифеста кодируется с помощью Apache Avro и организовано вокруг четырех основных секций.
- ColumnGroups описывает столбцы, форматы, файлы и диапазоны идентификаторов строк.
- DeltaLogs описывают удаления. Различные типы удалений охватывают разные источники изменений, такие как удаления по первичному ключу от клиентов, позиционные удаления от внутреннего уплотнения или удаления по равенству от внешних движков.
- Статистика включает метаданные планирования, такие как фильтры bloom, статистика BM25 и минимальные/максимальные значения.
- Индексы описывают тип индекса, параметры, охватываемые столбцы и диапазоны идентификаторов строк. Они могут включать векторные индексы, такие как HNSW или IVF, текстовые индексы, инвертированные индексы, растровые индексы и связанные с ними структуры.
В этом Loon отличается от традиционного табличного манифеста.
Векторный набор данных должен отслеживать не только файлы данных и разделы. Он также должен отслеживать векторные индексы, текстовые индексы, разреженные функции, журналы удаления, статистику, ссылки на внешние объекты и диапазоны идентификаторов строк, которые их связывают.
Манифест должен быть доступен для записи не только в базе данных
Самое важное - это не только то, что содержит манифест. Важно, кто может его записать.
- Если только база данных может писать манифест, он остается внутренними метаданными. Более чистые метаданные, но все еще частные для одного движка.
- Если же внешние движки могут генерировать новые ColumnGroups, статистику и записи Manifest, Manifest становится интерфейсом координации.
- Например, задание Spark может заполнить разреженный векторный столбец. Оно записывает новую ColumnGroup, регистрирует покрытие строк и статистику, а также фиксирует новый Manifest. Онлайн-запросы могут продолжать читать старую версию во время выполнения задания. После успешной фиксации новая версия становится видимой.
По духу это похоже на Iceberg и Delta Lake, но объектная модель шире. Векторный набор данных должен отслеживать векторные индексы, текстовые индексы, разреженные характеристики, журналы удаления, статистику, ссылки на блобы и диапазоны идентификаторов строк, а не только файлы таблиц и разделы.
Оптимистичные коммиты упрощают обновление версий
Каждый коммит записывает новую версию Manifest. Писатель может создать новое содержимое на основе версии N, а затем попытаться написать manifest-{N+1}.avro. Семантика условной записи в хранилище объектов или семантика соответствия генерации может сделать коммит неудачным, если эта версия уже существует. Тогда писатель может повторить попытку с более новой версией.
Это дает Loon оптимистичный параллелизм, не заставляя каждое обновление проходить через тяжелый, сильно согласованный путь координации. Без манифеста многоформатное и многодвигательное хранилище в конечном итоге превращается в соглашения об именовании и ручное согласование. Это может сработать для небольших наборов данных. Но это не подходит для векторных данных масштаба ТБ.
Манифест - это то, что превращает разнородные файлы в набор данных, который могут безопасно читать и обновлять несколько систем.
Что изменится для пользователей, когда хранилище станет версионным
Для разработчиков приложений Loon не должен стать новым бременем API.
Пользователи по-прежнему должны работать с привычными концепциями Milvus: коллекциями, вставками, поиском и гибридным поиском. Им не придется думать о файлах Manifest, группах ColumnGroups, диапазонах идентификаторов строк или компоновке файлов при разработке обычных приложений.
Изменения кроются в следующем. Хранилище становится более осведомленным о том, как на самом деле развиваются наборы данных ИИ.
Добавление нового вложения не должно перемещать старые данные
Раньше добавление embedding_v2 в существующую коллекцию часто требовало экспорта данных, обучения новой модели, генерации векторов, а затем повторного импорта или обновления коллекции с помощью SDK. Такой путь создает много оперативной работы: отслеживание версий, повторные попытки неудачных заданий, перестроение индексов, воздействие на сервисы и проверка согласованности.
С Loon это может превратиться в эволюцию схемы плюс фиксация новой ColumnGroup. Новый столбец встраивания можно записать как собственную физическую ColumnGroup, выровнять по идентификатору строки и сделать видимым через Manifest. Старый столбец с надписью, скалярный столбец метаданных и оригинальный столбец встраивания перемещать не нужно.
Обратные заполнения не должны требовать цикла обновления на стороне клиента
Многие обновления данных ИИ являются обратным заполнением. Команда может добавлять разреженные векторы после того, как гибридный поиск становится важным. Она может добавить функции ранжирования после обучения новой модели. Она может исправить подписи после проверки человеком. Она может добавить теги управления после обновления политики.
В традиционной компоновке эти изменения часто происходят через обновления клиентского SDK или пути записи только в базу данных, даже если данные производятся Spark, Ray или другим внешним движком.
В Loon внешние вычислительные системы могут создавать новые ColumnGroups и фиксировать их через Manifest. База данных больше не должна быть единственной точкой входа для каждой перезаписи.
Автономный анализ не должен требовать еще одной копии истины
Раньше команды часто сбрасывали онлайн-коллекцию в Parquet для оффлайн-оценки или анализа. При этом создаются две версии одного и того же набора данных: онлайн-коллекция и копия для анализа. Когда исправляются подписи, регенерируются вкрапления, применяются журналы удаления или перестраиваются индексы, команде приходится спрашивать, какая из копий является актуальной.
При использовании модели хранения на основе манифестов аналитические системы могут читать тот же самый версионный набор данных, что и обслуживающая система. Они могут проецировать только нужные им столбцы, сканировать только соответствующие диапазоны строк и работать с объявленной версией набора данных, а не с экспортированным вручную снимком.
Удаления и исправления должны касаться только того, что изменилось
Удаление, исправление подписей, исправление меток и обновление управления - обычное дело в наборах данных ИИ. Они не должны заставлять каждый столбец длинного вектора проходить один и тот же путь перезаписи.
В Loon удаление журналов сначала можно рассматривать как логическое удаление. Позднее уплотнение может очистить затронутые ColumnGroups без перезаписи несвязанных данных. Если изменяется короткое текстовое поле, уровень хранения не должен перезаписывать сотни гигабайт плотных векторов только потому, что они разделяют одну и ту же логическую строку.
Внешние движки становятся частью рабочего процесса, а не аварийным люком
Более серьезный сдвиг заключается в том, что внешние движки больше не рассматриваются как системы вне базы данных векторов.
Spark, Ray, задания по оценке, системы маркировки и конвейеры управления уже производят и изменяют большую часть данных. Уровень хранения должен позволить им сотрудничать вокруг единого источника истины, а не постоянно экспортировать, копировать и повторно импортировать данные.
Именно это и делает возможным версия Manifest. Она дает возможность онлайн-обслуживания, оффлайн-анализа, заданий на обратное заполнение и уплотнения общего представления набора данных.
Это может показаться деталями внутреннего хранения, но они влияют на то, как быстро команды могут итеративно работать с наборами данных ИИ. Каждое изменение модели, заполнение функций, исправление надписей, фильтр качества и перестроение индекса зависит от одного и того же вопроса: "Может ли система обновить набор данных, не перемещая ненужные данные?".
В этом и заключается практическая ценность модели хранения.
Loon доступна в Milvus 3.0 beta и Zilliz Vector Lakebase
Loon доступна в Milvus 3.0 beta, а также является частью слоя хранения данных в Zilliz Vector Lakebase, следующей эволюции Zilliz Cloud. В этом выпуске основное внимание уделяется трем ключевым областям:
- Манифест. Цель состоит в том, чтобы при записи, заполнении, удалении, статистике и обновлении индексов создавались версионные представления наборов данных, которые читатели могут открывать последовательно. Для читателей это означает, что запрос может открыть определенную версию манифеста и увидеть стабильное представление набора данных. Для писателей это означает, что новые файлы данных, журналы удаления, статистика или файлы индексов могут быть сначала подготовлены, а затем сделаны видимыми с помощью версионного коммита.
- ColumnGroup и поддержка форматов. Parquet поддерживает скалярные и экосистемные колонки. Vortex поддерживает векторно-тяжелые шаблоны доступа. Lance может быть интегрирован в режиме "только чтение" для совместимости с существующими наборами данных Lance.
- Индекс на озере. Скалярные индексы, фильтрующие индексы и инвертированные индексы с текстом могут участвовать в планировании на основе Manifest по диапазону строк. Векторные индексы на основе Lake более вовлечены в процесс. HNSW и IVF по-разному ведут себя с объектным хранилищем, и HNSW, в частности, чувствителен к случайному доступу и локальности кэша. Он не может просто повторно использовать макет, разработанный для локального SSD, и ожидать того же результата.
Работа еще впереди
- Внешние пути записи имеют значение, потому что Spark и Ray должны уметь создавать ColumnGroups и Manifest commits, не заставляя каждую обратную запись проходить через цикл клиентского SDK.
- Взаимодействие с Lakehouse имеет значение, поскольку многие команды уже используют каталоги и механизмы запросов, такие как Iceberg, Delta Lake, Trino, DuckDB и Athena. Векторные данные должны иметь возможность участвовать в этой экосистеме без потери производительности векторного поиска.
- Расположение индексов имеет значение, поскольку графовые индексы и инвертированные структуры имеют разные схемы доступа к объектным хранилищам.
- Семантика больших объектов имеет значение, поскольку необработанные видео, PDF, изображения и аудиофайлы требуют управления ссылками, версионирования и удаления, которые соответствуют производному векторному набору данных.
Точное поведение релиза, настройки по умолчанию и пути миграции должны быть указаны в соответствующих примечаниях к релизам Milvus и Zilliz Cloud. Однако направление хранения данных очевидно: векторные базы данных нуждаются в версионированной, "озерной" основе под обслуживающим слоем.
Попробуйте Loon под Zilliz Vector Lakebase
Если ваш текущий стек разделяет онлайн-обслуживание, автономный анализ, обратное заполнение и внешние рабочие процессы озера данных на разные системы, стоит обратить внимание на Zilliz Vector Lakebase. Вы можете попробовать его в Zilliz Cloud. Новые подписчики по электронной почте получают $100 бесплатных кредитов. Вы также можете обсудить с нами свой вариант использования.
Вы также можете следить за выпуском Milvus 3.0, чтобы узнать, как развивается Loon в движке с открытым исходным кодом.
Zilliz Vector Lakebase объединяет в себе:
- многоуровневое обслуживание для различных компромиссов между производительностью и стоимостью в реальном времени
- Поиск по требованию для крупномасштабных или исследовательских рабочих нагрузок, не требующих постоянных вычислений.
- Внешний поиск в озере данных, позволяющий индексировать и искать непосредственно в существующих данных озера.
- Полноспектральный поиск по векторам, тексту, JSON и геопространственным данным с гибридным поиском и ранжированием
- Унифицированное хранилище на базе Vortex - открытого формата, предназначенного для более быстрого и недорогого случайного чтения векторных данных.
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word



