Porque criámos o Loon: um motor de armazenamento para dados de IA que nunca pára de mudar.
Este blogue foi originalmente publicado em zilliz.com e foi republicado com autorização.
Principais conclusões
Este é um mergulho longo e profundo na engenharia, então aqui estão os pontos-chave antes de entrarmos nos detalhes.
- Os conjuntos de dados de IA não são tabelas estáticas. As mesmas linhas mudam constantemente à medida que as equipes substituem modelos de incorporação, adicionam vetores esparsos, revisam legendas, preenchem rótulos, reconstroem índices e executam análises off-line.
- Os esquemas de armazenamento tradicionais falham de três formas: colunas de vectores longas tornam os backfills dispendiosos, um único formato de ficheiro não consegue servir bem as digitalizações e as leituras pontuais e o armazenamento de bases de dados privadas obriga os pipelines externos a criar cópias extra da verdade.
- Loon é o novo mecanismo de armazenamento para Milvus e Zilliz Vetor Lakebase. Ele é construído em torno de formatos de arquivo híbridos, alinhamento de ID de linha e um Manifesto que define o estado de versão do conjunto de dados.
- O objetivo é permitir que um único conjunto de dados vectoriais suporte pesquisa online, análise offline, backfills, compactação e computação externa sem copiar, reescrever ou reimportar dados constantemente.
Introdução
Durante algum tempo, houve um argumento contra as bases de dados vectoriais que parecia razoável.
As bases de dados tradicionais já armazenam inteiros, strings, JSON, blobs e índices. Por que não adicionar um tipo _vector_ , construir um índice ANN ao lado dele e pronto?
Para a pesquisa semântica inicial, isso funciona suficientemente bem. Uma coluna vetorial e um índice podem suportar uma demonstração, uma pequena aplicação RAG ou uma funcionalidade de pesquisa interna. O problema aparece mais tarde, quando o conjunto de dados começa a comportar-se menos como uma tabela e mais como um sistema de dados de IA.
Um conjunto de dados vectoriais de produção tem linhas, chaves primárias, campos escalares e colunas consultáveis. Nesse sentido, assemelha-se a uma tabela de base de dados. Mas também tem a escala e a forma de fluxo de trabalho de um lago de dados. Pode conter centenas de milhões de registos. É repetidamente lido e reescrito pelo Spark, Ray, DuckDB, pipelines de treinamento, trabalhos de avaliação e sistemas de qualidade de dados.
Também depende do armazenamento de objectos. Os objectos de origem são frequentemente vídeos, imagens, PDFs, ficheiros áudio ou documentos Web que permanecem no S3, GCS, OSS ou outro armazenamento de objectos. A base de dados armazena referências, metadados, caraterísticas derivadas e índices. Em seguida, adiciona elementos que os modelos de armazenamento tradicionais não foram concebidos para gerir como objectos de primeira classe: embeddings densos, vectores esparsos, legendas, índices vectoriais, índices de texto, registos de eliminação, estatísticas, versões de modelos, versões de analisadores, referências de blob externas e as relações de versão entre todos eles.
É aqui que "basta adicionar uma coluna vetorial" começa a falhar. A questão não é se uma base de dados pode armazenar bytes vectoriais. Muitos sistemas podem. A questão mais difícil é se o modelo de armazenamento consegue lidar com a forma como os dados vectoriais mudam, como são consultados e como são partilhados na pilha de dados da IA.
Foi por isso que criámos o Loon, o novo motor de armazenamento para o Milvus e o Zilliz Vetor Lakebase (a próxima evolução do Zilliz Cloud).
O Loon foi concebido com três ideias:
- Utilizar diferentes formatos físicos para diferentes tipos de colunas.
- Alinhar essas colunas através de um espaço de ID de linha partilhado.
- Usar um Manifesto para definir o estado de versão do conjunto de dados.
Para ver por que essas partes são importantes, vamos começar com um fluxo de trabalho multimodal comum.
Um conjunto de dados vetoriais nunca está realmente concluído.
Imagine uma equipa de IA a criar um conjunto de dados de vídeo para formação multimodal.
Um vídeo longo é carregado para o armazenamento de objectos. Um pipeline corta-o em clipes com base em mudanças de cena, limites de filmagem ou janelas de tempo. Os clips demasiado longos ou demasiado curtos, desfocados, duplicados ou de baixa qualidade são filtrados. Os restantes clips são classificados por um modelo estético, legendados por outro modelo, incorporados por um modelo de linguagem visual e armazenados numa base de dados vetorial para pesquisa, desduplicação e filtragem de dados de treino.
A um nível elevado, o fluxo de trabalho parece simples:
video
→ clips
→ metadata
→ aesthetic_score
→ caption
→ embedding
→ search / dedup / training data filtering
Mas o conjunto de dados não chega totalmente formado.
- Na primeira semana, a tabela pode conter apenas
clip_id,video_id,start_offset, eduration. - Na segunda semana, a equipa acrescenta
aesthetic_score. - Na terceira semana, é executado um modelo de legendagem e cada clip recebe um
caption. - Na quarta semana, o primeiro modelo de incorporação fica online e cada clip recebe uma incorporação CLIP de 768 dimensões.
- Um mês depois, a equipa muda de modelo e volta a preencher
embedding_v2, agora com 1024 dimensões. - Dois meses mais tarde, a pesquisa híbrida torna-se um requisito, pelo que a equipa acrescenta uma coluna de vectores esparsos.
- Três meses mais tarde, as legendas são sujeitas a revisão humana e têm de ser corrigidas no local.
O conjunto de dados nunca foi concluído. Continuou a acumular novas interpretações das mesmas linhas subjacentes.
Esta é uma das principais diferenças entre os dados vectoriais e os dados comerciais tradicionais. A mesma linha é reprocessada vezes sem conta. E a escala transforma isto de um inconveniente num problema de armazenamento: os conjuntos de dados multimodais não são frequentemente milhões de registos, mas centenas de milhões ou milhares de milhões. O LAION-5B é uma referência útil para a forma - biliões de pares imagem-texto, cada um com metadados, legendas e embeddings. Portanto, a parte mais difícil não é a primeira inserção. A parte difícil é tudo o que acontece depois de o conjunto de dados começar a evoluir. Essa evolução expõe três problemas.
O primeiro problema: colunas longas tornam a amplificação da escrita dispendiosa
Formatos colunares como o Parquet são excelentes para muitas cargas de trabalho analíticas. Eles funcionam bem quando os esquemas são razoavelmente estáveis, os dados são lidos com mais frequência do que reescritos, as varreduras tocam apenas um subconjunto de colunas e a compressão é importante. Esse é o mundo para o qual muitos formatos analíticos foram optimizados.
As linhas vectoriais são muito mais largas do que as linhas analíticas
O TPC-H lineitem é uma boa linha de base. Tem 16 colunas: chaves inteiras, valores decimais, datas, cadeias curtas e um pequeno campo de comentários. Uma linha não comprimida tem cerca de 150 bytes. Após a compressão, pode ser muito mais pequena. Com um grupo de linhas de 64 MB, um sistema de armazenamento pode empacotar centenas de milhares de linhas num grupo.
Os conjuntos de dados vectoriais não têm esse aspeto.
Um conjunto de dados de imagem-texto do tipo LAION está muito mais próximo do que muitos pipelines de IA produzem atualmente. Cada linha continua a ter metadados normais: um URL, uma legenda, largura, altura, índices de qualidade, etiquetas, etc. Mas assim que a incorporação é adicionada, a forma física da linha muda.
Um vetor CLIP de 768 dimensões ocupa cerca de 1,5 KB em fp16 ou 3 KB em fp32. Essa única coluna pode ser muito maior do que uma linha inteira do TPC-H lineitem.
E 768 dimensões não são invulgares ou grandes para os padrões actuais. Um embedding de 1024 ou 2048 dimensões é comum em pipelines multimodais. O text-embedding-3-large da OpenAI vai até 3072 dimensões, o que equivale a cerca de 12 KB por vetor em fp32.
A comparação é evidente:
| Forma do conjunto de dados | Tamanho aproximado da linha | O que domina a linha |
|---|---|---|
| Item de linha TPC-H | ~150 bytes não comprimidos | campos escalares e de cadeia curta |
| Linha do tipo LAION com vetor fp16 de 768 dígitos | ~1,5 KB+ | incorporação |
| Linha estilo LAION com vetor fp32 de 768 dígitos | ~3 KB+ | incorporação |
| Linha com vetor fp32 de 3072 dim | ~12 KB+ só para o vetor | incorporação |
Em muitos conjuntos de dados de IA, a coluna do vetor não é apenas mais um campo. Fisicamente, é a maior parte da linha. Isso altera o custo da evolução do esquema.
Adicionar uma coluna de vetor pode significar centenas de gigabytes
Suponhamos que um conjunto de dados tem 100 milhões de clips de vídeo. Adicionar uma nova coluna de incorporação fp32 de 1024 dimensões significa escrever cerca de 400 GB de dados vetoriais brutos. Isso não inclui estatísticas, índices, atualizações de metadados, sobrecarga de armazenamento de objetos, validação ou integração de caminho de serviço.

Se a equipa adicionar uma ou duas colunas vectoriais todos os meses, tais como embedding_v2, sparse_vector, ou funcionalidades de rerank, a evolução do esquema torna-se um trabalho recorrente de engenharia daAta medido em centenas de gigabytes ou terabytes.
Pequenas actualizações lógicas podem desencadear grandes reescritas físicas
As actualizações são igualmente importantes.
Nos sistemas colunares, os dados antigos não são normalmente actualizados no local. Um registo de eliminação regista as alterações e a compactação reescreve posteriormente as linhas activas em novos ficheiros. Esse modelo é gerenciável quando as linhas são pequenas.
Com dados vectoriais, uma pequena atualização lógica pode desencadear uma grande reescrita física.
Um trabalho de revisão humano pode corrigir apenas algumas centenas de bytes numa legenda. Mas se a legenda, o vetor denso, o vetor esparso e outras caraterísticas derivadas partilharem o mesmo ciclo de vida do ficheiro físico, o sistema pode acabar por reescrever também os vectores. A alteração lógica é pequena. A E/S física pode ser enorme.
Este é o problema da amplificação da escrita no armazenamento vetorial. A parte dispendiosa não é apenas o facto de os vectores serem grandes. É o facto de os campos derivados grandes e os campos mutáveis pequenos ficarem frequentemente ligados por uma disposição de armazenamento que os trata como uma unidade.
Para conjuntos de dados de IA, o backfill é uma carga de trabalho de rotina
Para tabelas analíticas tradicionais, a evolução do esquema pode ocorrer apenas ocasionalmente. Para os conjuntos de dados de IA, é uma rotina. Os modelos de legenda são actualizados. Os modelos de incorporação são substituídos. Os vectores esparsos são adicionados mais tarde. Aparecem caraterísticas de reclassificação. As etiquetas humanas são corrigidas. As etiquetas de governação são preenchidas novamente. Os índices são reconstruídos.
Estas operações não são simples adições. Elas frequentemente modificam ou estendem linhas existentes.
É por isso que o armazenamento vetorial não pode apenas otimizar o débito de digitalização. Também tem de tornar os backfills e as actualizações parciais mais baratos.
O segundo problema: os mesmos dados devem suportar varreduras e leituras pontuais
Depois de os dados serem escritos, o caminho de leitura divide-se. O mesmo conjunto de dados vetoriais normalmente tem dois padrões de acesso distintos: varredura analítica e leituras pontuais.
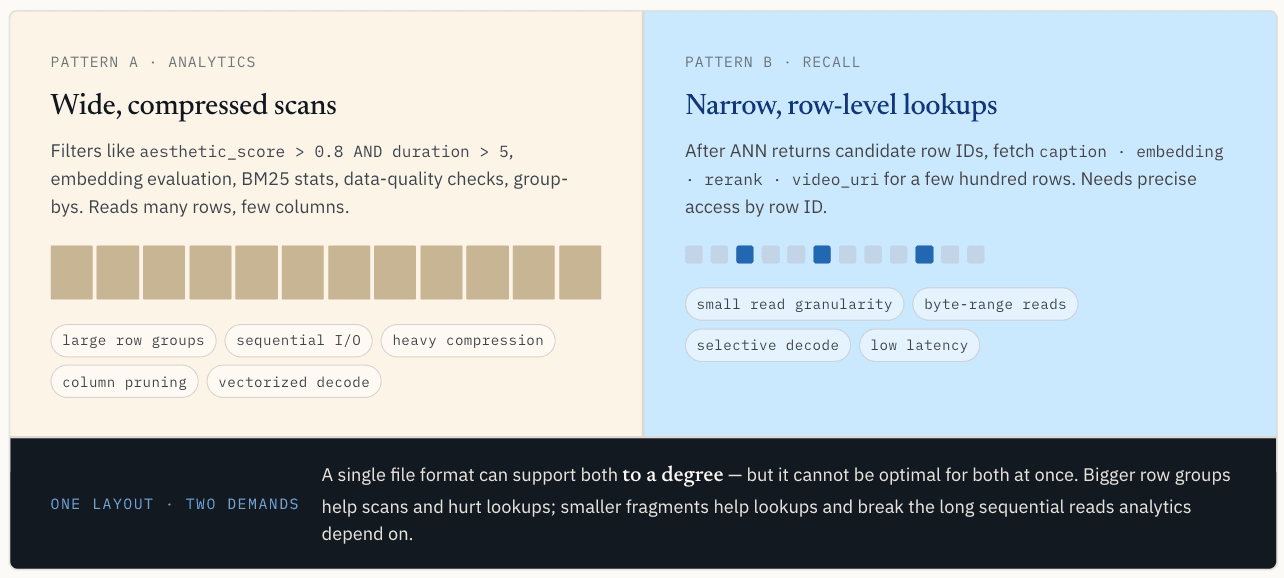
As cargas de trabalho analíticas querem varreduras amplas e compactadas
Um pipeline pode executar filtros como:
WHERE aesthetic_score > 0.8 AND duration > 5
Ou pode executar análises offline, avaliação de incorporação completa, estatísticas BM25, construção de mapas de bits, verificações da qualidade dos dados, contagens e agrupamentos.
Este padrão lê muitas linhas mas apenas algumas colunas. Ele gosta de E/S sequencial, grupos de linhas maiores, compressão, poda de colunas, decodificação em lote e execução vetorizada.
Grandes grupos de linhas ajudam aqui. Eles permitem que uma única solicitação de E/S extraia uma grande quantidade de dados úteis, melhoram a eficiência da compactação e fornecem ao mecanismo de execução dados contíguos suficientes para amortizar a sobrecarga. Quando várias colunas são lidas em conjunto, mantê-las organizadas para o rendimento da varredura também ajuda a reduzir os erros de cache durante a execução vetorizada.
O Parquet é forte neste caminho.
Os resultados ANN precisam de pesquisas estreitas, a nível de linha
Depois que a pesquisa ANN retorna IDs de linhas candidatas, o sistema frequentemente precisa buscar campos como:
caption
embedding
rerank feature
video_uri
metadata
Esse padrão lê menos linhas, geralmente centenas ou milhares, mas precisa de acesso preciso por ID de linha. Pretende localizar uma linha e coluna específicas, obter apenas o intervalo de bytes necessário e evitar obter um grupo de linhas inteiro apenas para obter alguns registos.
A pesquisa pontual tem quase a preferência oposta à varredura. Ela quer uma granularidade de leitura menor. Idealmente, a camada de armazenamento pode encontrar o segmento relevante ou o intervalo de bytes por ID de linha, ler apenas esse intervalo e descodificar apenas os dados necessários para o resultado.
A compressão também tem uma compensação diferente. Para varreduras, uma compressão mais pesada geralmente vale a pena porque o sistema lê muitos dados e economiza E/S. Para a pesquisa de pontos, a compressão pode tornar-se um problema se a recuperação de uma linha exigir a descodificação de um bloco comprimido muito maior.
Um layout não pode ser otimizado para ambos os caminhos
Este é o conflito central. A filtragem e a análise escalar querem layouts amplos, compactados e de fácil leitura. A pesquisa de vectores quer layouts estreitos, precisos e endereçáveis por linha.
Um único formato de arquivo pode suportar ambos até certo ponto, mas não pode ser ideal para ambos simultaneamente.
Se todas as colunas estiverem no Parquet, as digitalizações escalares são confortáveis. Mas a pesquisa ANN após a recuperação torna-se mais difícil. O sistema pode necessitar apenas de algumas centenas de vectores, legendas ou registos de metadados, enquanto a camada de armazenamento pode ter de ler grandes grupos de linhas que contêm maioritariamente linhas irrelevantes.
Num SSD local, a cache e o mmap podem ocultar parte deste custo. Quando os dados são armazenados no armazenamento de objectos, o custo torna-se mais visível. Cada falha de cache pode se tornar uma leitura de intervalo remoto. Se as linhas candidatas estiverem espalhadas por muitos grupos de linhas, uma única consulta pode desencadear várias leituras, cada uma extraindo mais dados do que a consulta precisa. Em um layout mal definido, a busca de 1.000 linhas candidatas pode facilmente resultar em dezenas ou centenas de megabytes de E/S desnecessárias e, em casos extremos, muito mais.
Tornar os grupos de linhas mais pequenos ajuda a pesquisa de pontos, mas prejudica as pesquisas. Demasiados fragmentos pequenos reduzem a eficiência da compressão, aumentam a sobrecarga de metadados e quebram as longas leituras sequenciais de que os motores analíticos dependem.
Portanto, o problema não é encontrar um único tamanho mágico de grupo de linhas. O problema é que o mesmo conjunto de dados está a ser solicitado a comportar-se como dois sistemas de armazenamento diferentes.
A pesquisa híbrida força ambos os caminhos numa única consulta
A pesquisa híbrida torna o conflito mais difícil de ignorar. Uma única consulta pode primeiro aplicar filtros escalares:
aesthetic_score > 0.8 AND duration > 5
Em seguida, executa a pesquisa ANN.
Em seguida, vai buscar a legenda, o vetor e os metadados por ID de linha.
Para o utilizador, trata-se de um pedido de pesquisa. Para a camada de armazenamento, trata-se de uma pesquisa analítica e de uma pesquisa aleatória de baixa latência.
É por isso que o armazenamento de vectores precisa de mais do que uma melhor definição de Parquet. Precisa de uma forma de colocar colunas diferentes de acordo com a forma como são efetivamente lidas.
O terceiro problema: o conjunto de dados não reside num único motor
Os dois primeiros problemas ocorrem no interior da base de dados. O terceiro ocorre na fronteira entre sistemas.

Os pipelines de dados de IA abrangem muitos sistemas
No fluxo de trabalho de vídeo, muito pouco acontece na própria base de dados vetorial.
Os vídeos em bruto vivem no armazenamento de objectos. A geração de clips pode ser executada no Spark ou no Ray. A pontuação estética pode ser executada num serviço GPU. As legendas podem ser executadas num pipeline de inferência LLM. Os embeddings podem ser gerados por outro trabalho de GPU. Os vectores esparsos podem ser provenientes de um serviço SPLADE. A avaliação offline, a filtragem de dados de formação, a revisão humana e os trabalhos de governação podem ser executados noutro local.
A base de dados de vectores serve a pesquisa em linha, mas o conjunto de dados é produzido, corrigido, avaliado e alargado por muitos sistemas.
Os formatos de armazenamento privados criam várias cópias da verdade
Se a base de dados utiliza um formato físico privado que só ela pode ler e escrever, cada tarefa externa necessita de uma exportação, uma conversão, uma cópia e uma importação. A mesma coleção pode existir na base de dados, num diretório temporário Spark, num output de avaliação e num diretório local de backfill. Então a verdadeira questão torna-se:
- Qual cópia é a fonte da verdade?
- Qual delas contém o modelo de legenda do mês passado?
- Quais linhas já foram corrigidas por revisão humana?
- Que coluna de vetor esparso foi gerada por que modelo?
- Que índice vetorial ainda é válido após o backfill?
- A que objeto de vídeo original se refere esta linha?
Em pequena escala, as equipas podem por vezes sobreviver com convenções de nomes e verificações manuais. Com centenas de milhões de linhas e terabytes de incorporação, isto torna-se um problema de consistência.
Os conjuntos de dados vectoriais precisam de um estado de versão partilhado
Os sistemas Lakehouse resolveram uma versão deste problema para dados estruturados. Iceberg, Delta Lake e Hudi não se limitam a armazenar ficheiros. A sua principal contribuição é permitir que vários motores se coordenem em torno do mesmo estado de tabela.
As bases de dados vectoriais necessitam agora de uma capacidade semelhante, mas o estado é mais complexo. Deve incluir não só ficheiros de tabela e partições, mas também índices vectoriais, índices de texto, caraterísticas esparsas, registos de eliminação, estatísticas, intervalos de ID de linha e referências a blobs externos.
A questão não é simplesmente: "O Spark pode ler arquivos Milvus?"
A questão é: depois que o Spark preenche uma coluna de vetor esparso, como o Milvus sabe a qual versão essa coluna pertence, quais linhas ela cobre, qual modelo a produziu e quando as consultas online podem usá-la com segurança?
A resposta tem que estar no modelo de armazenamento.
Porque é que os patches não são suficientes
É tentador tratar estes problemas como três problemas de engenharia distintos.
- Amplificação de escrita? Adicione batching.
- Leituras pontuais? Adicione um cache.
- Sistemas externos? Adicione ferramentas de exportação e importação.
Essas correcções podem ajudar, mas não resolvem o problema subjacente: um conjunto de dados vectoriais é fisicamente heterogéneo.

No exemplo do vídeo, clip_id, video_id, duration e aesthetic_score são campos escalares curtos. São úteis para filtragem e análise.
captioné texto. Pode ser utilizado para BM25, revisão, correção e preenchimento.embeddingé um vetor longo e denso. É utilizado para a recuperação de RNA e, posteriormente, para pesquisa ou reanálise ao nível da linha.embedding_v2é um novo modelo de saída, muitas vezes preenchido muito tempo depois de os dados originais terem sido inseridos.sparse_vectorsuporta pesquisa híbrida e tem seu próprio padrão de acesso.- O vídeo em bruto deve permanecer no armazenamento de objectos. A base de dados deve armazenar uma referência, uma soma de verificação, um tipo MIME, uma versão do analisador e uma relação ao nível da linha.
- Os índices vectoriais, os índices de texto, as estatísticas e os registos de eliminação são objectos derivados com a sua própria semântica de versão.
Estes objectos partilham uma linha lógica, mas não devem partilhar todos a mesma disposição física ou ciclo de vida.
- Se forem forçados a uma disposição de tabela normal, as actualizações tornam-se dispendiosas.
- Se forem forçados a um formato de ficheiro colunar, as leituras de pontos tornam-se dispendiosas.
- Se forem tratados como ficheiros de objectos não relacionados, a gestão de versões torna-se frágil.
Assim, o modelo de armazenamento tem de partir do facto de o conjunto de dados ser heterogéneo.
Isto conduz a três requisitos de conceção:
- Primeiro, diferentes grupos de colunas devem ser armazenados em diferentes formatos físicos.
- Em segundo lugar, esses grupos de colunas necessitam de um espaço de ID de linha partilhado, para que possam continuar a comportar-se como uma única tabela lógica.
- Terceiro, o conjunto de dados precisa de um Manifesto versionado que declare quais os ficheiros, índices, registos, estatísticas e referências de objectos que pertencem à vista atual.
Este é o design por detrás do Loon, o nosso novo motor de armazenamento por detrás do Milvus e do Zilliz Cloud.
Loon: um motor de armazenamento por trás do Milvus e do Zilliz Cloud para conjuntos de dados vectoriais em evolução
Para resolver todos os problemas acima referidos, criámos o Loon, o novo motor de armazenamento do Milvus e do Zilliz Vetor Lakebase (a próxima evolução do Zilliz Cloud), concebido para conjuntos de dados vectoriais em evolução.
O nome segue a tradição de nomes de aves do Zilliz. Um mergulhão é uma ave de mergulho que vive em lagos, o que se enquadra bem no objetivo do sistema: uma base de dados vetorial não deve ter de mover, analisar ou reescrever um lago inteiro de dados sempre que executa uma consulta, preenche uma coluna ou cria um índice. Deve primeiro compreender a versão atual do conjunto de dados, incluindo as suas colunas, índices, estatísticas, registos de eliminação e referências a objectos, e depois ler apenas a parte de que realmente necessita.
Os formatos de arquivo híbridos, o alinhamento de ID de linha e o Manifesto não são três recursos separados. Eles resultam do mesmo pressuposto de design: um conjunto de dados vetorial é inerentemente heterogéneo.
Três peças, um modelo de armazenamento
Os formatos de ficheiro híbridos reconhecem que colunas diferentes têm padrões de acesso diferentes. Os campos escalares são bons para pesquisas e filtros. Os campos vectoriais necessitam de uma pesquisa eficiente ao nível da linha. Os objectos em bruto, como vídeos, PDFs, imagens e ficheiros de áudio, pertencem ao armazenamento de objectos e não aos ficheiros de dados da base de dados.
O alinhamento de ID de linha reconhece que estas colunas podem estar fisicamente separadas, mas continuam a descrever as mesmas linhas lógicas. Uma legenda, uma incorporação, um vetor esparso e um URI de vídeo podem residir em ficheiros e formatos diferentes, mas têm de ser reunidos como um único resultado.
O Manifesto reconhece que o conjunto de dados não é escrito uma vez e deixado sozinho. Será modificado por vários sistemas, em várias versões, para várias tarefas. Índices, estatísticas, logs de exclusão, referências a objetos externos e grupos de colunas devem aparecer na mesma visualização versionada.
É por isso que o Loon não é apenas um formato de ficheiro vetorial mais rápido. Um formato mais rápido ajuda na pesquisa de pontos, mas não resolve a evolução do esquema ou a coordenação de vários mecanismos. O alinhamento do ID da linha permite que as colunas divididas se comportem como uma única tabela, mas não especifica quais os ficheiros que pertencem à versão atual. Um Manifesto pode descrever o estado de um conjunto de dados, mas sem grupos de colunas e alinhamento de ID de linha, ele não pode representar de forma limpa diferentes layouts físicos dentro de uma coleção lógica.
O modelo de armazenamento precisa de todos os três: formatos diferentes para grupos de colunas diferentes, um espaço de ID de linha compartilhado para reconstruir linhas e um Manifesto com versão que informa a cada leitor e escritor qual é o conjunto de dados atual.
Onde o Loon se encaixa no Milvus e no Zilliz Vetor Lakebase
No Milvus, ele substitui a antiga camada de armazenamento binlog de segmentos por um modelo construído em torno de abstrações de Manifesto, ColumnGroup, formato de arquivo e sistema de arquivos. No Zilliz Vetor Lakebase (a próxima evolução do Zilliz Cloud), a mesma direção aplica-se à arquitetura do Vetor Lakebase: manter a base de dados vetorial a servir o caminho rapidamente, tornando os dados subjacentes mais fáceis de evoluir, analisar e coordenar com sistemas externos.
Os componentes de nível superior do Milvus ainda mantêm as suas funções familiares. O proxy lida com o roteamento. O QueryCoord e o DataCoord tratam do agendamento. IndexNode constrói índices. As APIs voltadas para aplicações de coleções, inserções, pesquisas e pesquisas híbridas não precisam expor arquivos Manifest ou ColumnGroups.
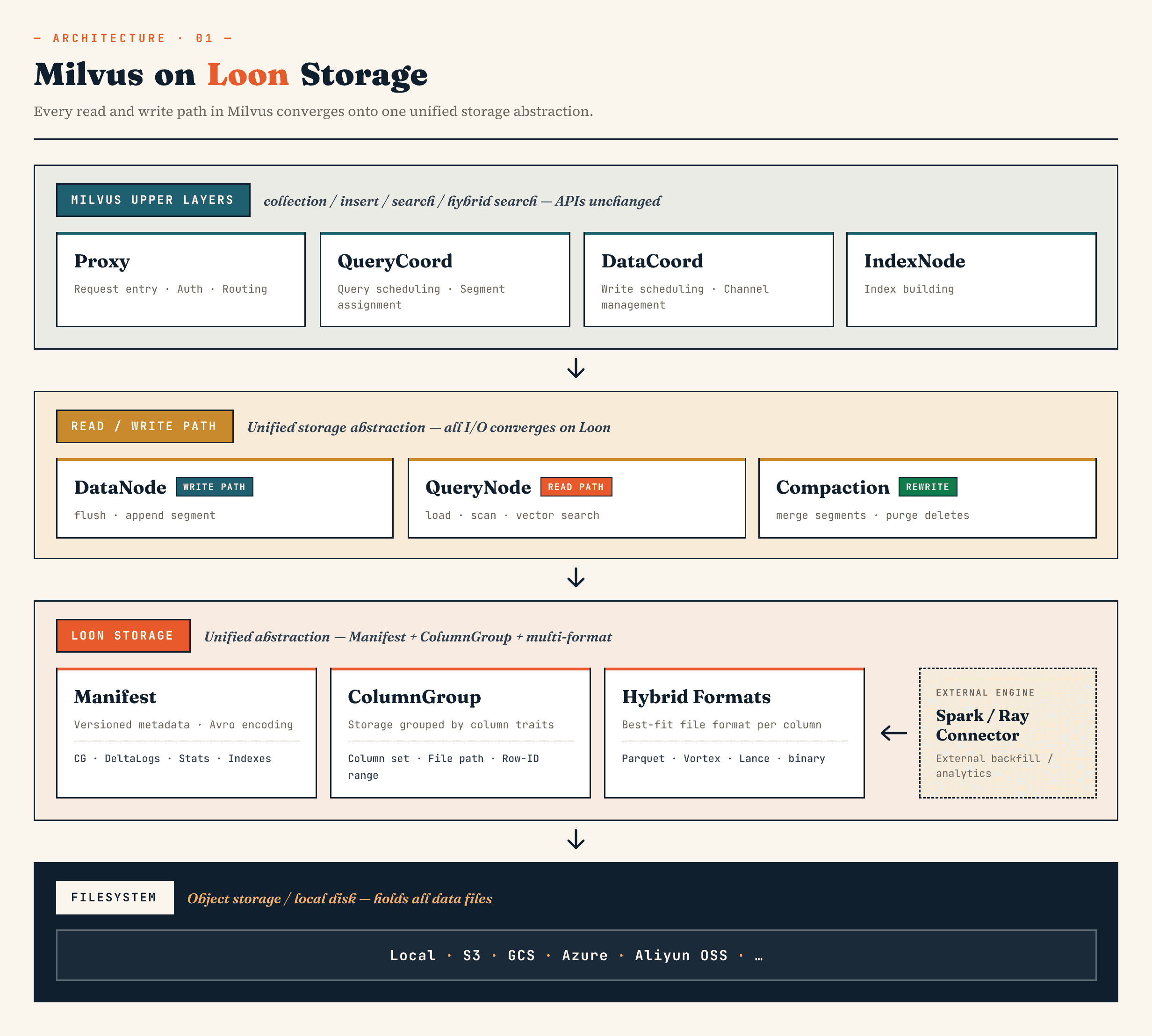
A mudança está por baixo.
O DataNode, o QueryNode, o segcore, a compactação e os conectores externos podem operar por meio da mesma abstração de armazenamento. Isso é importante porque o conjunto de dados não é mais escrito e lido apenas pelo banco de dados. Pode ser alargado por sistemas de computação externos e consumido simultaneamente pela pesquisa em linha.
Num nível elevado, as camadas têm o seguinte aspeto:
Manifest
→ ColumnGroup
→ file format layer
→ filesystem abstraction
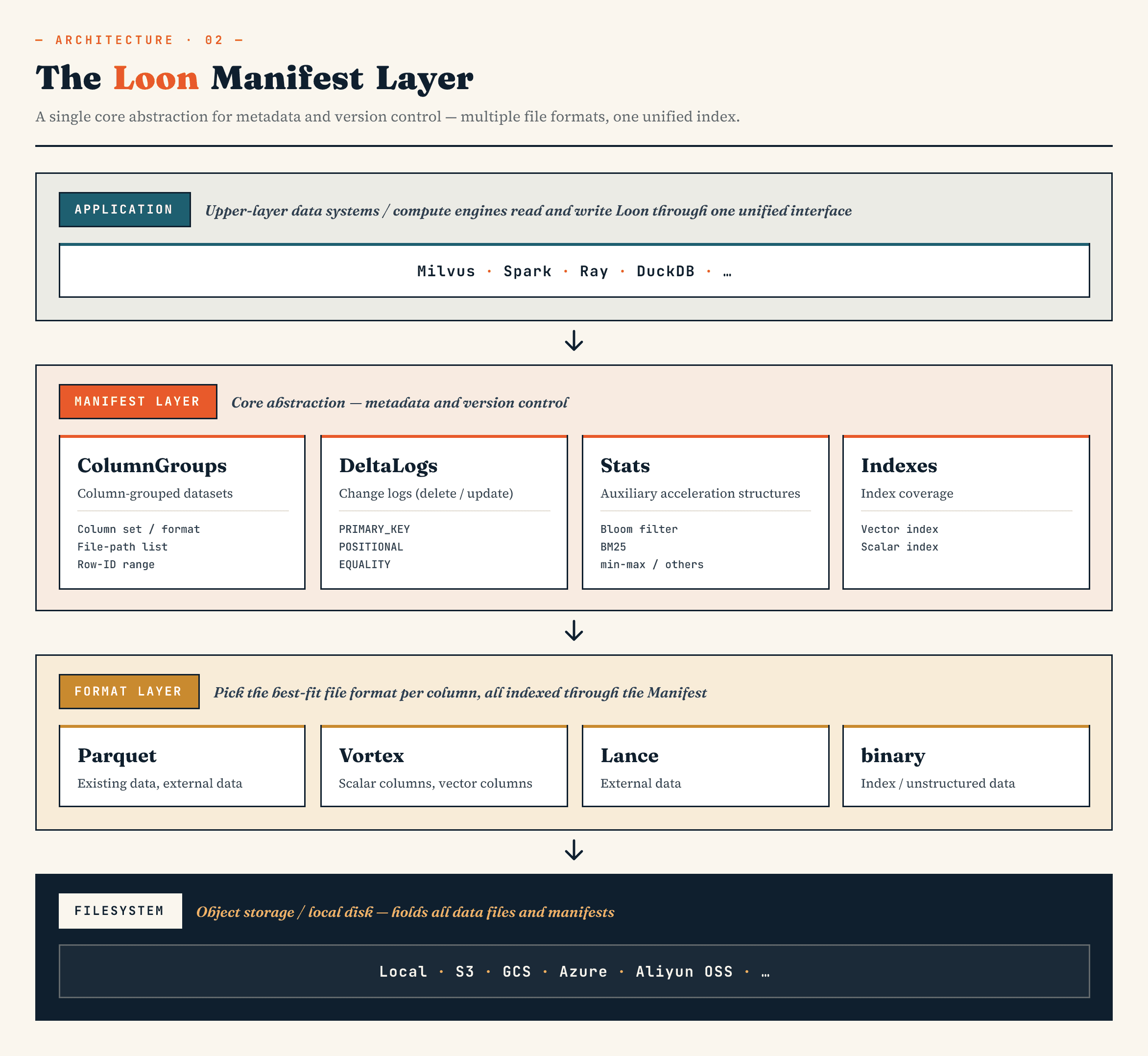
O Manifesto descreve o estado versionado do conjunto de dados. Os ColumnGroups mapeiam uma coleção lógica em grupos físicos de colunas. A camada de formato de ficheiro permite que cada ColumnGroup escolha um formato apropriado. A abstração do sistema de ficheiros funciona no armazenamento de objectos e no armazenamento local.
O ponto importante é que os formatos de arquivo híbridos, o alinhamento de ID de linha e o Manifesto não são recursos separados. Juntos, eles definem o modelo de armazenamento.
Com esse modelo em vigor, podemos analisar as três opções de design uma a uma: como o Loon armazena diferentes ColumnGroups, como os alinha de volta em linhas e como o Manifesto transforma esses arquivos em um conjunto de dados com versão.
Projeto 1: usar o formato de arquivo certo para o grupo de colunas certo
Colunas diferentes têm padrões de acesso diferentes. Elas não devem ser forçadas a usar o mesmo formato de arquivo.
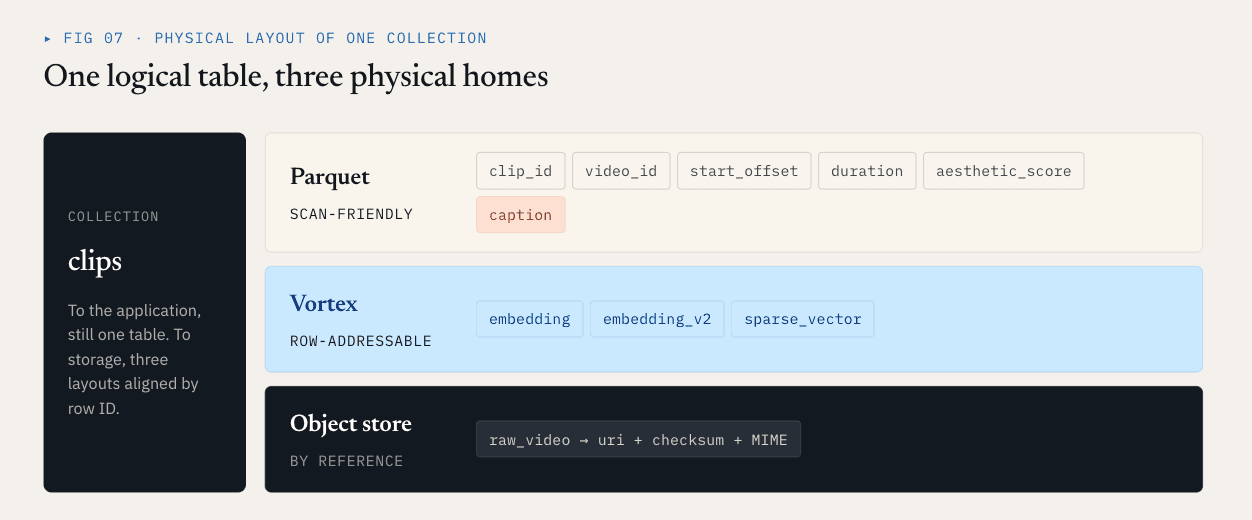
O Loon separa uma coleção lógica em ColumnGroups.
- Os campos escalares, campos de filtro, chaves de negócio e campos estatísticos são frequentemente analisados, filtrados, agregados ou utilizados para planeamento de consultas. Beneficiam de compressão, redução de colunas e compatibilidade com o ecossistema. O Parquet é uma boa opção para estas colunas.
- Os vectores densos, os vectores esparsos e as caraterísticas de rerank são frequentemente lidos após a chamada ANN por ID de linha. Necessitam de acesso aleatório de baixa latência, leituras precisas de intervalos de bytes e descodificação selectiva. Um layout orientado a segmentos é mais adequado. O Loon utiliza o Vortex nesta direção.
- Os objectos brutos, como vídeos, PDFs, imagens e ficheiros de áudio, não devem ser incorporados nos ficheiros de dados da base de dados vetorial. Devem permanecer no armazenamento de objectos. A base de dados regista referências, somas de verificação, tipos MIME, versões do analisador e relações ao nível das linhas.
Para o exemplo do vídeo, uma apresentação física pode ter o seguinte aspeto:
Parquet ColumnGroup:
clip_id / video_id / start_offset / duration / aesthetic_score / caption
Vortex ColumnGroups:
embedding
embedding_v2
sparse_vector
Object storage:
raw video objects
Para a aplicação, isto continua a ser uma coleção. Para a camada de armazenamento, diferentes partes dessa coleção utilizam diferentes formatos físicos. Isto reduz diretamente as reescritas desnecessárias. A adição de embedding_v2 pode tornar-se um novo vetor ColumnGroup mais uma confirmação de Manifesto. Não é necessário reescrever a coluna de legenda, os metadados escalares ou a coluna de incorporação existente.
A mesma ideia aplica-se a vectores esparsos, caraterísticas rerank ou outros campos derivados. Se uma nova coluna puder ser fisicamente independente e alinhada por ID de linha, ela não precisará arrastar colunas não relacionadas pelo mesmo caminho de reescrita.
O Loon também adapta o uso de formatos de arquivo.
Para o Parquet, as configurações padrão nem sempre são ideais para dados vetoriais pesados. Um grupo de linhas de 64 MB pode ser muito grande para pesquisa de pontos porque uma pequena leitura aleatória pode puxar muito mais dados do que o necessário. O Loon limita os grupos de linhas a 1 MB em caminhos relevantes e desativa codificações, como a codificação de dicionário em colunas de vetor, quando elas não ajudam os dados vetoriais de aparência aleatória.
Para o Vortex, o trabalho mais importante é o layout. O Loon usa um layout que equilibra a eficiência da varredura e a pesquisa de pontos. Dentro de um grupo de linhas, os segmentos de colunas relacionadas podem ser colocados próximos uns dos outros para suportar a varredura. Para executar operações, as leituras de subsegmentos permitem que o sistema busque apenas os bytes relevantes, em vez de extrair um segmento inteiro.
O Loon também suporta a integração do Lance somente leitura, de modo que os conjuntos de dados existentes do Lance podem ser montados como ColumnGroups quando a compatibilidade for importante.
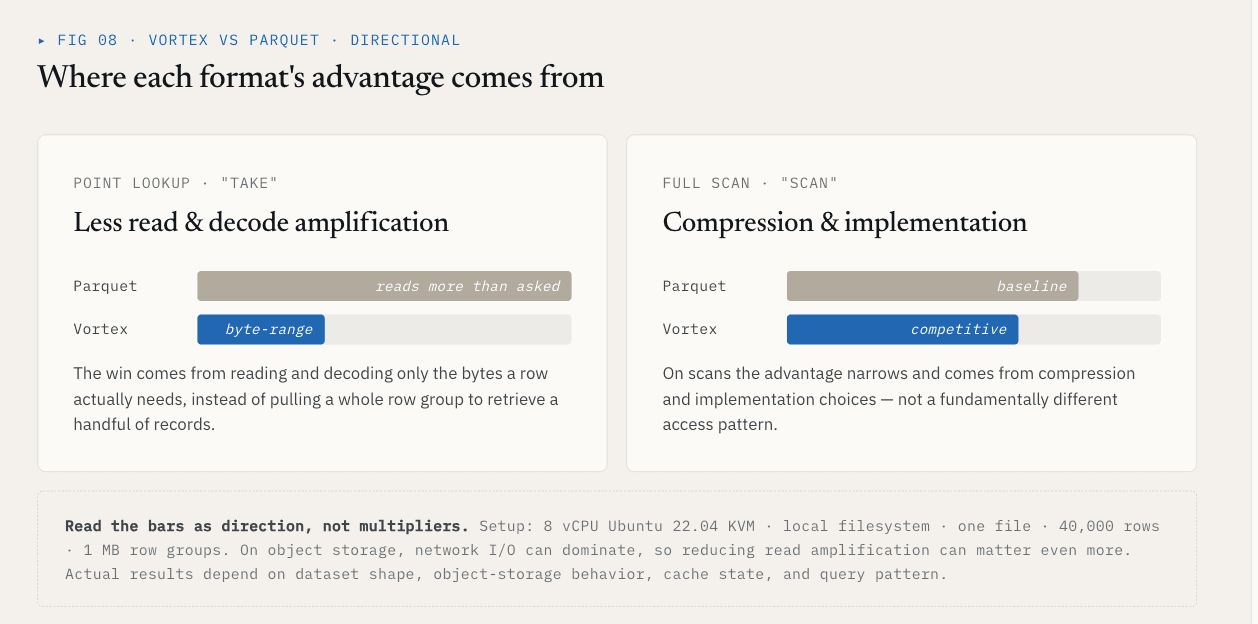
O que o benchmark mostra
Em um teste local, usando um único arquivo com 40.000 linhas e o esquema {id: int64, name: utf8, value: float64, vector: list<float32>[128]}, o Vortex mostrou esses resultados contra o Parquet com grupos de linhas de 1 MB:
| Operação | Vortex | Parquet | Diferença |
|---|---|---|---|
| Pegar, K=1000 linhas aleatórias | 5,8 ms | 144 ms | 25x mais rápido |
| Pesquisa completa de colunas vectoriais | 21 ms | 142 ms | 6,76x mais rápido |
| Tamanho do ficheiro, ~21 MB de dados em bruto | 6,62 MB | 7,16 MB | 7% mais pequeno |
O resultado do take vem da redução da quantidade de dados irrelevantes que devem ser lidos e descodificados. O resultado da digitalização vem da compressão e das escolhas de implementação.
Estes números devem permanecer ligados à sua configuração: 8 vCPU Ubuntu 22.04 KVM, sistema de arquivos local, um arquivo, 40.000 linhas, grupos de linhas de 1 MB e o esquema acima. No armazenamento de objetos, a E/S de rede pode dominar, portanto, reduzir a amplificação de leitura pode ser ainda mais importante. Os resultados reais dependem da forma do conjunto de dados, do comportamento do armazenamento de objectos, do estado da cache e do padrão de consulta.
O ponto mais amplo não é que todas as colunas devam usar o Vortex.
A questão é que os conjuntos de dados vetoriais precisam de uma escolha de formato de arquivo no nível do ColumnGroup.
Projeto 2: alinhar arquivos físicos através de IDs de linha
Os formatos de ficheiro híbridos resolvem um problema: as diferentes colunas podem agora viver nos formatos que melhor lhes convêm.
Mas isso cria um segundo problema. Se campos escalares vivem no Parquet, vetores vivem no Vortex e objetos brutos vivem no armazenamento de objetos, como o sistema ainda os trata como uma coleção?
O Loon resolve isso com o alinhamento de ID de linha.
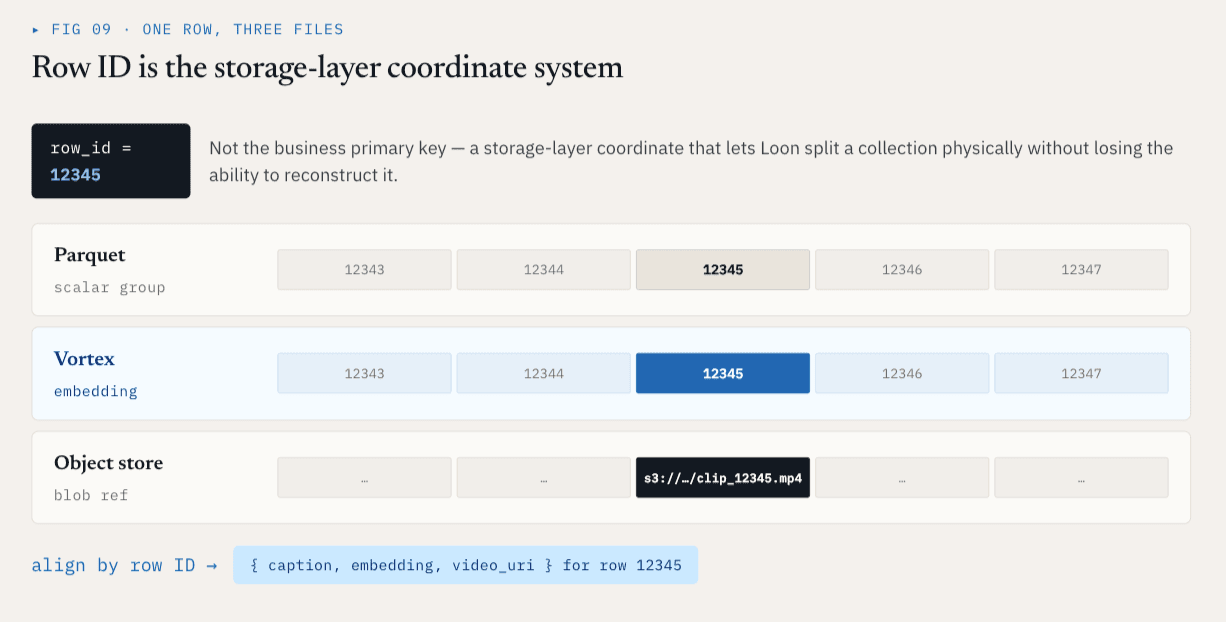
O ID da linha é o sistema de coordenadas da camada de armazenamento
Cada ColumnGroupFile físico regista o caminho do ficheiro e o intervalo de ID de linha que cobre:
path
start_index
end_index
Diferentes ColumnGroups podem cobrir o mesmo espaço de ID de linha mesmo que estejam em arquivos e formatos diferentes.
Para a ID de linha 12345, os metadados escalares podem estar num Parquet ColumnGroup, a incorporação pode estar num Vortex ColumnGroup e o vídeo em bruto pode ser representado por uma referência de armazenamento de objectos. Logicamente, eles ainda são uma linha. Isto dá ao nível de armazenamento um sistema de coordenadas estável.
O ID da linha não é a chave primária do negócio. É o sistema de coordenadas da camada de armazenamento que permite ao Loon dividir uma coleção fisicamente sem perder a capacidade de reconstruí-la logicamente.
Novas colunas não precisam reescrever colunas antigas
Adicionar embedding_v2 não requer reescrever a legenda original, os metadados ou embedding_v1 ColumnGroups. O Loon pode escrever um novo vetor ColumnGroup, registrar o intervalo de IDs de linha que ele cobre e confirmar essa alteração por meio do Manifesto.
O mesmo se aplica a vectores esparsos, caraterísticas de rerank ou outros campos derivados que chegam mais tarde.
Desde que o novo ColumnGroup cubra o intervalo de ID de linha correto, pode juntar-se à mesma coleção lógica sem forçar a movimentação de dados não relacionados.
As eliminações e a compactação podem ser mais direcionadas
O alinhamento do ID de linha também ajuda com as exclusões.
Uma eliminação pode ser expressa primeiro através de um registo de eliminação. A linha torna-se invisível ao nível lógico, enquanto a limpeza física é adiada até à compactação. Quando a compactação é executada, nem sempre é necessário reescrever todos os ColumnGroup ligados às linhas afectadas. Ele pode se concentrar nos ColumnGroup que precisam de limpeza.
Isso é importante porque nem todas as colunas têm o mesmo perfil de custo. Reescrever um ColumnGroup escalar curto é muito diferente de reescrever centenas de gigabytes de vetores densos.
A pesquisa híbrida pode buscar apenas as colunas necessárias
O alinhamento de ID de linha também é o que torna a pesquisa híbrida prática em cima de formatos de arquivo híbridos.
Depois de a pesquisa ANN devolver as IDs de linha candidatas, o sistema pode ir buscar apenas os campos necessários para o resultado final: legendas, metadados, vectores, caraterísticas de rerank ou referências de objectos.
Por exemplo, uma consulta pode necessitar:
caption
embedding
video_uri
Esses campos podem estar em diferentes ColumnGroups. O Loon pode localizar os arquivos relevantes por intervalo de ID de linha, ler os intervalos de bytes necessários e montar o resultado.
Sem o alinhamento de ID de linha, os formatos híbridos seriam apenas arquivos separados lado a lado. Com o alinhamento de ID de linha, eles se comportam como uma única coleção lógica.
O Packed Reader esconde a divisão da camada superior
O componente de tempo de execução que torna isso utilizável é o Packed Reader.
A camada superior vê um fluxo Arrow RecordBatch unificado. Por baixo, os dados podem vir de vários ColumnGroups em diferentes formatos de ficheiro. O Packed Reader oculta essas diferenças, alinha os dados por intervalos de ID de linha e programa a E/S de vários ficheiros com utilização controlada da memória.
Também suporta take direto por ID de linha. Dado um conjunto de IDs de linha, ele localiza os ColumnGroupFiles relevantes, emite leituras de intervalo e retorna os campos solicitados.
Para o fluxo de trabalho de vídeo, uma consulta ANN pode precisar de caption, embedding, e video_uri. O Packed Reader pode ir buscar o ColumnGroup escalar e o ColumnGroup vetorial sem tocar em colunas não relacionadas.
Esta é a diferença entre "ficheiros separados" e "uma tabela com várias disposições físicas".
Conceção 3: tornar o Manifesto a fonte da verdade
Os formatos de ficheiro híbridos definem a forma como os dados são fisicamente armazenados. O alinhamento do ID de linha determina como os ColumnGroups separados ainda formam uma única tabela lógica. Mas o sistema ainda precisa de responder a uma questão maior: que ficheiros, registos, estatísticas, índices e referências de objectos pertencem à versão atual do conjunto de dados? Essa é a tarefa do Manifesto.

Os diretórios de armazenamento de objectos não são suficientes
O armazenamento de objectos não é um catálogo de bases de dados. Um diretório pode conter ficheiros antigos, novos ficheiros, resultados de tarefas falhadas, ficheiros temporários, registos de eliminação, ficheiros ainda referenciados por instantâneos mais antigos e ficheiros à espera de limpeza. O fato de um arquivo existir não significa que ele pertence à versão atual do conjunto de dados.
Um conjunto de dados Loon pode ser organizado em diretórios como:
_metadata/
_data/
_delta/
_stats/
_index/
Mas a estrutura de diretórios não é a fonte da verdade. O Manifesto é. Os leitores não devem listar diretórios e inferir o estado a partir de quaisquer ficheiros que existam. Eles devem ler o Manifesto atual e seguir a visão versionada que ele declara.
O Manifesto define uma visão versionada do conjunto de dados
O Manifesto define o conjunto de dados numa determinada versão. Regista:
- quais os ColumnGroups existentes
- quais os intervalos de ID de linha que abrangem
- o formato físico que cada ColumnGroup utiliza
- onde se encontram os ficheiros
- que registos de eliminação estão activos
- que estatísticas estão disponíveis
- quais os índices existentes
- que blobs externos são referenciados
- que colunas e intervalos de linhas essas estatísticas ou índices cobrem
Cada atualização escreve uma nova versão do Manifesto. Um leitor que abre a versão N vê uma visão estável do conjunto de dados na versão N. Um escritor pode preparar a versão N+1 sem perturbar os leitores que ainda estão a usar a versão N.
O Manifesto rastreia mais do que arquivos de tabela
No Loon, o corpo do Manifesto é codificado com Apache Avro e organizado em torno de quatro secções principais.
- ColumnGroups descreve as colunas, formatos, arquivos e intervalos de ID de linha.
- DeltaLogs descreve as exclusões. Diferentes tipos de eliminação abrangem diferentes fontes de alteração, tais como eliminações de chave primária de clientes, eliminações posicionais de compactação interna ou eliminações de igualdade de motores externos.
- As estatísticas incluem metadados de planeamento, como filtros bloom, estatísticas BM25 e valores mínimos/máximos.
- Os índices descrevem o tipo de índice, os parâmetros, as colunas abrangidas e os intervalos de ID de linha. Isso pode incluir índices vetoriais, como HNSW ou IVF, índices de texto, índices invertidos, índices de bitmap e estruturas relacionadas.
É aqui que o Loon difere de um manifesto de tabela tradicional.
Um conjunto de dados vetorial precisa de seguir não só os ficheiros de dados e as partições. Ele também precisa rastrear índices vetoriais, índices de texto, recursos esparsos, logs de exclusão, estatísticas, referências a objetos externos e os intervalos de ID de linha que os conectam.
O Manifesto deve ser gravável por mais do que a base de dados
A parte mais importante não é apenas o que o Manifesto contém. É quem o pode escrever.
- Se apenas o banco de dados puder escrever o Manifesto, ele permanecerá como metadados internos. Metadados mais limpos, mas ainda privados de um motor.
- Se os motores externos puderem gerar novos ColumnGroups, estatísticas e entradas de Manifesto, o Manifesto torna-se uma interface de coordenação.
- Um trabalho Spark, por exemplo, pode preencher uma coluna de vetor esparso. Ele grava um novo ColumnGroup, registra a cobertura de linha e as estatísticas e faz o commit de um novo Manifesto. As consultas online podem continuar lendo a versão antiga durante o trabalho. Quando o commit é bem-sucedido, a nova versão torna-se visível.
O espírito é semelhante ao do Iceberg e do Delta Lake, mas o modelo de objeto é mais amplo. Um conjunto de dados vetorial precisa de controlar índices vectoriais, índices de texto, caraterísticas esparsas, registos de eliminação, estatísticas, referências de blob e intervalos de ID de linha, e não apenas ficheiros de tabela e partições.
Os commits otimistas mantêm as atualizações de versão simples
Cada commit escreve uma nova versão do Manifesto. Um escritor pode criar um novo conteúdo com base na versão N e, em seguida, tentar escrever manifest-{N+1}.avro. A escrita condicional do armazenamento de objectos ou a semântica de correspondência de gerações podem fazer com que o commit falhe se essa versão já existir. O escritor pode então tentar novamente com a versão mais recente.
Isso dá ao Loon uma concorrência otimista sem forçar cada atualização através de um caminho de coordenação pesado e fortemente consistente. Sem um Manifesto, o armazenamento multi-formato e multi-motor eventualmente se transforma em convenções de nomes e reconciliação manual. Isso pode funcionar para pequenos conjuntos de dados. Não funciona para dados vetoriais em escala TB.
O Manifesto é o que transforma ficheiros heterogéneos num conjunto de dados que vários sistemas podem ler e atualizar em segurança.
O que muda para os utilizadores quando o armazenamento passa a ser versionado
Para os desenvolvedores de aplicativos, o Loon não deve se tornar um novo fardo para a API.
Os utilizadores devem continuar a trabalhar com conceitos familiares do Milvus: colecções, inserções, pesquisa e pesquisa híbrida. Não devem precisar de pensar em ficheiros Manifest, ColumnGroups, intervalos de ID de linhas ou layout de ficheiros durante o desenvolvimento normal de aplicações.
A mudança está por baixo. O armazenamento torna-se mais consciente da forma como os conjuntos de dados de IA evoluem efetivamente.
A adição de uma nova incorporação não deve mover os dados antigos
Anteriormente, adicionar embedding_v2 a uma coleção existente exigia frequentemente a exportação de dados, a formação de um novo modelo, a geração de vectores e, em seguida, a reimportação ou atualização em massa da coleção através do SDK. Esse caminho cria muito trabalho operacional: rastreamento de versão, tentativas de trabalho com falha, reconstruções de índice, impacto de veiculação e verificações de consistência.
Com o Loon, isso pode se tornar uma evolução de esquema mais um novo commit de ColumnGroup. A nova coluna de incorporação pode ser escrita como seu próprio ColumnGroup físico, alinhada por ID de linha e tornada visível através do Manifesto. A antiga coluna de legenda, a coluna de metadados escalares e a coluna de incorporação original não precisam ser movidas.
Os backfills não devem exigir um ciclo de atualização do lado do cliente
Muitas atualizações de dados de IA são backfills. Uma equipa pode adicionar vectores esparsos depois de a pesquisa híbrida se tornar importante. Pode adicionar caraterísticas de rerank depois de um novo modelo ser treinado. Pode corrigir legendas após revisão humana. Pode adicionar etiquetas de governação após uma atualização da política.
Em um layout tradicional, essas alterações geralmente ocorrem por meio de atualizações do SDK do cliente ou caminhos de gravação somente no banco de dados, mesmo quando os dados são produzidos pelo Spark, Ray ou outro mecanismo externo.
Com o Loon, os sistemas de computação externos podem produzir novos ColumnGroups e confirmá-los por meio do Manifesto. O banco de dados não precisa mais ser o único ponto de entrada para cada reescrita.
A análise offline não deve exigir outra cópia da verdade
Anteriormente, as equipas descarregavam frequentemente uma coleção online no Parquet para avaliação ou análise offline. Isto cria duas versões do mesmo conjunto de dados: a coleção online e a cópia de análise. Quando as legendas são corrigidas, os embeddings são gerados novamente, os registos de eliminação são aplicados ou os índices são reconstruídos, a equipa tem de perguntar qual é a cópia atual.
Com um modelo de armazenamento baseado em manifesto, os mecanismos de análise podem ler a mesma exibição de conjunto de dados com versão que o sistema de servidor. Eles podem projetar apenas as colunas necessárias, verificar apenas os intervalos de linhas relevantes e trabalhar com uma versão declarada do conjunto de dados em vez de um instantâneo exportado manualmente.
As eliminações e correcções devem tocar apenas no que foi alterado
As eliminações, correcções de legendas, correcções de etiquetas e actualizações de governação são rotina nos conjuntos de dados de IA. Elas não devem forçar cada coluna de vetor longo a passar pelo mesmo caminho de reescrita.
Com o Loon, a eliminação de registos pode ser tratada primeiro como uma eliminação lógica. A compactação posterior pode limpar os ColumnGroups afetados sem reescrever dados não relacionados. Se um campo de texto curto for alterado, a camada de armazenamento não deve ter que reescrever centenas de gigabytes de vetores densos só porque eles compartilham a mesma linha lógica.
Os motores externos passam a fazer parte do fluxo de trabalho, não são um escape
A maior mudança é que os motores externos já não são tratados como sistemas fora da base de dados vetorial.
Spark, Ray, trabalhos de avaliação, sistemas de rotulagem e pipelines de governação já produzem e modificam grande parte dos dados. A camada de armazenamento deve permitir que eles colaborem em torno de uma única fonte de verdade, em vez de exportar, copiar e reimportar constantemente.
É isso que uma versão do Manifest torna possível. Ela oferece ao serviço online, à análise offline, aos trabalhos de backfill e à compactação uma visão compartilhada do conjunto de dados.
Estes podem parecer detalhes de armazenamento interno, mas afectam a rapidez com que as equipas podem iterar em conjuntos de dados de IA. Cada alteração de modelo, preenchimento de caraterísticas, correção de legendas, filtro de qualidade e reconstrução de índices depende da mesma pergunta: "O sistema pode atualizar o conjunto de dados sem mover dados que não precisa de mover?
É esse o valor prático do modelo de armazenamento.
O Loon está disponível no Milvus 3.0 beta e no Zilliz Vetor Lakebase
O Loon está disponível na versão beta do Milvus 3.0 e também faz parte da camada de armazenamento do Zilliz Vetor Lakebase, a próxima evolução do Zilliz Cloud. E esta versão centra-se em três áreas principais:
- O Manifesto. O objetivo é que as escritas, backfills, eliminações, estatísticas e actualizações de índices produzam visualizações de conjuntos de dados com versões que os leitores possam abrir de forma consistente. Para os leitores, isso significa que uma consulta pode abrir uma versão específica do Manifesto e ver uma exibição estável do conjunto de dados. Para os escritores, isso significa que novos arquivos de dados, logs de exclusão, estatísticas ou arquivos de índice podem ser preparados primeiro e, em seguida, tornados visíveis por meio de um commit com controle de versão.
- O ColumnGroup e o suporte ao formato. O Parquet suporta colunas escalares e amigáveis ao ecossistema. O Vortex suporta padrões de acesso vectoriais pesados. O Lance pode ser integrado no modo somente leitura para compatibilidade com os conjuntos de dados existentes do Lance.
- O Índice em Lake. As estatísticas escalares, os índices de filtragem e os índices invertidos de texto podem participar no planeamento baseado no Manifesto por intervalo de linhas. Os índices vectoriais nativos de Lake estão mais envolvidos. O HNSW e o IVF têm comportamentos diferentes no armazenamento de objectos, e o HNSW em particular é sensível ao acesso aleatório e à localidade da cache. Não pode simplesmente reutilizar um layout concebido para um SSD local e esperar o mesmo resultado.
Ainda há trabalho pela frente
- Os caminhos de escrita externos são importantes porque o Spark e o Ray devem ser capazes de produzir ColumnGroups e Manifest commits sem forçar cada backfill através de um loop do SDK do cliente.
- A interoperabilidade do Lakehouse é importante porque muitas equipas já utilizam catálogos e motores de consulta como o Iceberg, Delta Lake, Trino, DuckDB e Athena. Os dados vetoriais devem ser capazes de participar desse ecossistema sem perder o desempenho da pesquisa vetorial.
- A disposição dos índices é importante porque os índices gráficos e as estruturas invertidas têm padrões de acesso diferentes no armazenamento de objectos.
- A semântica de objectos grandes é importante porque os vídeos em bruto, os PDF, as imagens e os ficheiros de áudio requerem uma gestão de referências, um controlo de versões e um comportamento de eliminação que se alinham com o conjunto de dados vectoriais derivados.
O comportamento exato da versão, as definições predefinidas e o caminho de migração devem seguir as notas de versão relevantes do Milvus e do Zilliz Cloud. A direção do armazenamento, no entanto, é clara: os bancos de dados vetoriais precisam de uma base versionada e nativa de lago sob a camada de serviço.
Experimente o Loon no Zilliz Vetor Lakebase
Se a sua pilha atual separa o serviço online, a análise offline, os backfills e os fluxos de trabalho de data lake externos em sistemas diferentes, vale a pena dar uma vista de olhos ao Zilliz Vetor Lakebase. Pode experimentá-lo no Zilliz Cloud. Os novos registos de trabalho por e-mail recebem 100 dólares de créditos gratuitos. Também pode falar connosco sobre o seu caso de utilização.
Também pode seguir o lançamento do Milvus 3.0 para ver como o Loon evolui no motor de código aberto.
O Zilliz Vetor Lakebase reúne:
- Serviço em camadas para diferentes compensações de custo e desempenho em tempo real
- Pesquisa sob demanda para cargas de trabalho exploratórias ou de grande escala sem computação sempre ativa
- Pesquisa externa no lago de dados, para que possa indexar e pesquisar diretamente nos dados existentes no lago
- Pesquisa de espetro total em vetores, texto, JSON e dados geoespaciais, com recuperação híbrida e reranking
- Armazenamento unificado nativo do lago criado no Vortex, um formato aberto projetado para leituras aleatórias mais rápidas e de baixo custo em dados vetoriais pesados
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word



