なぜ我々はLoonを作ったのか:変化を止めないAIデータ用ストレージエンジン。
このブログはzilliz.comに掲載されたものを許可を得て再掲載しています。
要点
これは長く、深いエンジニアリング・ダイブになるので、詳細に入る前に重要なポイントを挙げておく。
- AIデータセットは静的なテーブルではない。チームがエンベッディング・モデルを入れ替えたり、スパース・ベクトルを追加したり、キャプションを修正したり、ラベルを埋め戻したり、インデックスを再構築したり、オフライン分析を実行したりすると、同じ行が変化し続ける。
- 従来のストレージレイアウトは3つの点で破綻している。長いベクトル列はバックフィルにコストがかかること、単一のファイルフォーマットではスキャンとポイントリードの両方にうまく対応できないこと、プライベートデータベースストレージは外部パイプラインに真実の余分なコピーを作成させること、である。
- LoonはMilvusとZilliz Vector Lakebaseの新しいストレージエンジンである。ハイブリッドファイル形式、行IDアライメント、データセットのバージョン管理状態を定義するマニフェストを中心に構築されている。
- 常にデータをコピー、書き換え、再インポートすることなく、単一のベクトルデータセットでオンライン検索、オフライン分析、バックフィル、コンパクション、外部コンピューティングをサポートすることを目標としています。
はじめに
しばらくの間、ベクター・データベースに対する一つの反論があった。
従来のデータベースはすでに整数、文字列、JSON、ブロブ、インデックスを格納している。 _vector_ 、その横にANNインデックスを構築し、それで終わりにしてはどう だろうか?
初期のセマンティック検索であれば、それで十分だ。ベクトル列とインデックスがあれば、デモや小さなRAGアプリケーション、あるいは内部検索機能をサポートできる。問題は、データセットがテーブルのようにではなく、AIデータシステムのように振る舞い始めたときに現れる。
プロダクション・ベクター・データセットには、行、主キー、スカラー・フィールド、クエリ可能なカラムがある。その意味では、データベースのテーブルのように見える。しかし、データレイクのスケールとワークフローの形状も持っている。何億ものレコードを含むこともある。Spark、Ray、DuckDB、トレーニングパイプライン、評価ジョブ、データ品質システムによって繰り返し読み込まれ、書き換えられる。
また、オブジェクトストレージにも依存する。ソースオブジェクトは、多くの場合、S3、GCS、OSS、または他のオブジェクトストアに残っているビデオ、画像、PDF、オーディオファイル、またはウェブドキュメントである。データベースは、参照、メタデータ、派生機能、インデックスを保存する。そして、従来のストレージモデルがファーストクラスのオブジェクトとして管理するために構築されていなかったものを追加する。密な埋め込み、疎なベクトル、キャプション、ベクトルインデックス、テキストインデックス、削除ログ、統計、モデルのバージョン、パーサーのバージョン、外部ブロブ参照、そしてそれらすべての間のバージョン関係だ。
ベクター列を追加するだけでいい」というのは、ここで破綻し始める。問題は、データベースがベクトルバイトを格納できるかどうかではない。多くのシステムは可能だ。より難しい問題は、ベクターデータがどのように変化し、どのようにクエリされ、AIデータスタック全体でどのように共有されるかを、ストレージモデルが扱えるかどうかだ。
これが、Milvusと Zilliz Vector Lakebase (Zillizクラウドの次の進化形)の新しいストレージエンジンであるLoonを構築した理由 だ。
Loonは3つのアイデアで設計されている:
- 列の種類によって物理フォーマットを使い分ける。
- これらのカラムは、共有された行IDスペースを通じて整列される。
- マニフェストを使ってデータセットのバージョン管理状態を定義する。
なぜこれらの要素が重要なのかを理解するために、一般的なマルチモーダルワークフローから始めましょう。
ベクトル・データセットが本当に完成することはない。
AIチームがマルチモーダル・トレーニング用のビデオ・データセットを構築しているところを想像してほしい。
長い動画がオブジェクトストレージにアップロードされる。パイプラインは、シーンの変化、ショットの境界、またはタイムウィンドウに基づいてクリップにカットする。長すぎたり短すぎたり、ぼやけていたり、重複していたり、低品質だったりするクリップはフィルタリングされる。残ったクリップは、美的モデルによって採点され、別のモデルによってキャプションが付けられ、視覚言語モデルによって埋め込まれ、検索、重複排除、学習データフィルタリングのためにベクトルデータベースに保存される。
このワークフローは一見シンプルに見える:
video
→ clips
→ metadata
→ aesthetic_score
→ caption
→ embedding
→ search / dedup / training data filtering
しかし、データセットは完全な形で到着するわけではない。
- 最初の週は、テーブルには
clip_id、video_id、start_offset、durationしかないかもしれない。 - 2週目には、
aesthetic_scoreが追加される。 - 3週目には、キャプションモデルが実行され、各クリップに
caption。 - 4週目には、最初の埋め込みモデルがオンラインになり、各クリップに768次元のCLIP埋め込みが追加されます。
- 1ヶ月後、チームはモデルを切り替え、
embedding_v2、今度は1024次元の埋め込みを行います。 - 2ヶ月後、ハイブリッド検索が要件となったため、チームはスパースベクトル列を追加しました。
- 3ヶ月後、キャプションは人間によるレビューを受け、その場で修正されなければならない。
データセットが完成することはなかった。同じ行の新しい解釈が蓄積され続けたのだ。
これがベクトルデータと従来のビジネスデータとの違いの核心の一つである。同じ行が何度も何度も再処理される。マルチモーダルデータセットは数百万レコードではなく、数億、数十億レコードになることが多い。LAION-5Bは、数十億の画像とテキストのペアで、それぞれにメタデータ、キャプション、埋め込みがある。つまり、難しいのは最初の挿入ではない。難しいのは、データセットが進化し始めた後に起こるすべてのことだ。この進化は3つの問題を露呈する。
第一の問題:長いカラムは書き込み増幅を高価にする
Parquetのようなカラム型フォーマットは、多くの分析ワークロードに適している。スキーマがかなり安定しており、データが書き換えられるより読み取られる頻度が高く、スキャンはカラムのサブセットにしか触れず、圧縮が重要な場合にうまく機能する。これは、多くの分析フォーマットが最適化された世界である。
ベクター行は分析行よりはるかに広い
TPC-Hlineitem 。整数キー、10進値、日付、短い文字列、小さなコメントフィールドの16列がある。非圧縮の1行はおよそ150バイトである。圧縮後はもっと小さくなる。64MBの行グループなら、ストレージシステムは何十万もの行を一つのグループにまとめることができる。
ベクターデータセットはそのようには見えない。
LAIONスタイルの画像-テキストデータセットは、今日多くのAIパイプラインが生成するものにずっと近い。各行には、URL、キャプション、幅、高さ、品質スコア、ラベルなど、通常のメタデータが残っている。しかし、エンベッディングが追加されると、行の物理的な形状が変わる。
768次元のCLIPベクトルは、fp16で約1.5KB、fp32で約3KBです。この1列は、TPC-H(lineitem )の行全体よりもはるかに大きくなる可能性がある。
そして、768次元は、今日の基準からすれば、珍しくも大きくもない。1024次元や2048次元のエンベッディングは、マルチモーダルパイプラインでは一般的です。OpenAIのtext-embedding-3-large は3072次元まであり、これはfp32で1ベクトルあたり約12KBです。
この差は歴然だ:
| データセット形状 | おおよその行サイズ | 行を支配するもの |
|---|---|---|
| TPC-H 行項目 | ~非圧縮で150バイト | スカラーと短い文字列フィールド |
| 768次元fp16ベクトルを持つLAIONスタイルの行 | ~1.5キロバイト以上 | 埋め込み |
| 768ディムfp32ベクトルによるLAIONスタイルの行 | ~3KB以上 | エンベッディング |
| 3072ディムのfp32ベクトルによる行 | ベクターだけで ~12 KB+ | 埋め込み |
多くのAIデータセットでは、ベクトル列は単なるフィールドではない。物理的には行の大部分を占める。これはスキーマ進化のコストを変える。
ベクトル列を1つ追加すると、数百ギガバイトになることもある
あるデータセットに1億のビデオクリップがあるとする。新たに1024次元のfp32エンベッディング列を追加することは、およそ400GBの生のベクトルデータを書き込むことを意味します。これには統計、インデックス、メタデータの更新、オブジェクト・ストレージのオーバーヘッド、検証、サービングパスの統合は含まれない。

もしチームが毎月、embedding_v2 、sparse_vector 、または再ランク機能など、1つか2つのベクトル的なカラムを追加する場合、スキーマの進化は、数百ギガバイトまたはテラバイト単位で測定される定期的なdaAtaエンジニアリング作業になる。
小さな論理更新が、大規模な物理的書き換えの引き金になることもある
更新も同様に重要である。
カラム型システムでは、古いデータは通常、そのままでは更新されない。削除ログに何が変更されたかが記録され、後でコンパクションが新しいファイルに生きた行を書き換える。このモデルは、行が小さい場合には管理しやすい。
ベクターデータでは、小さな論理更新が大きな物理的書き換えの引き金になる。
人間のレビュージョブは、キャプションの数百バイトを修正するだけかもしれない。しかし、キャプション、密なベクター、疎なベクター、その他の派生フィーチャーが同じ物理ファイルのライフサイクルを共有している場合、システムはベクターも書き換えてしまうかもしれません。論理的な変更は小さい。物理的なI/Oは巨大になる可能性がある。
これがベクター・ストレージにおける書き込み増幅の問題である。高価なのは、ベクターが大きいことだけではない。大きな派生フィールドと小さな変更可能フィールドが、それらを1つのユニットとして扱うストレージレイアウトによって、しばしば結びつけられてしまうことだ。
AIデータセットの場合、バックフィルは日常的な作業だ。
従来の分析テーブルでは、スキーマの進化はたまにしか起こらないかもしれない。AIデータセットの場合、それは日常的な作業である。キャプションモデルはアップグレードされる。埋め込みモデルは置き換えられる。スパースベクトルが後から追加される。再ランク機能が現れる。人間のラベルが修正される。ガバナンスタグが埋め戻される。インデックスが再構築される。
これらの操作は単純な追加ではない。既存の行を修正したり、拡張したりすることが多い。
そのため、ベクトル・ストレージはスキャンのスループットだけを最適化することはできない。また、バックフィルと部分更新をより安価にしなければならない。
第2の問題:同じデータでスキャンとポイントリードをサポートしなければならない
データが書き込まれた後、読み込みパスが分岐する。同じベクトル・データセットには通常、分析スキャンとポイント・リードという2つの異なるアクセス・パターンがある。
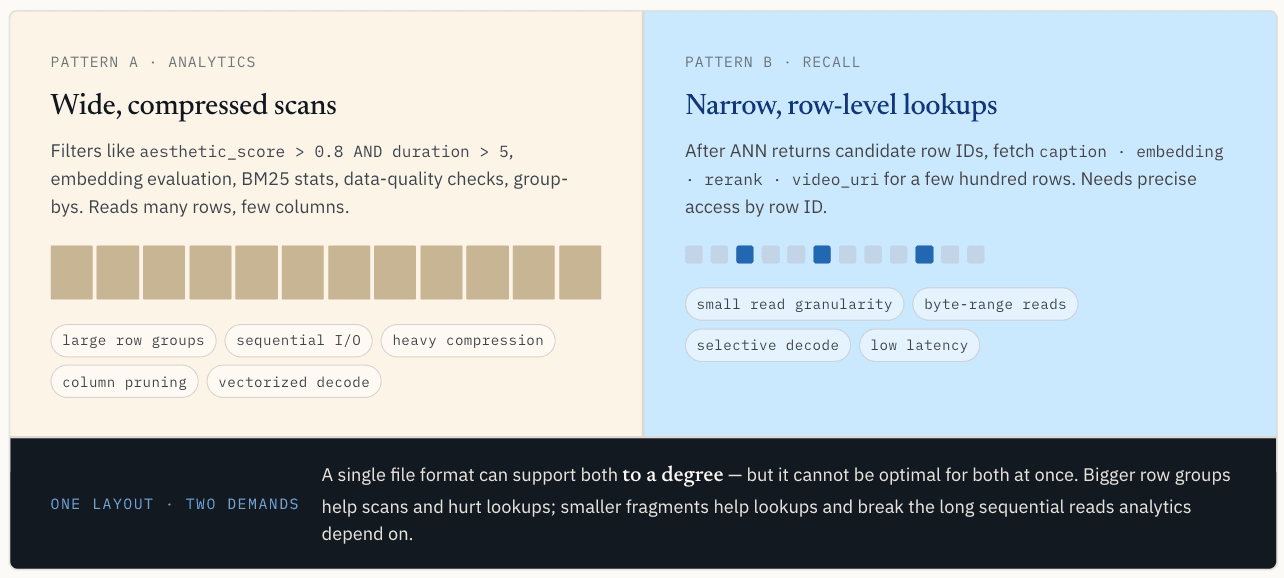
分析ワークロードは、ワイドで圧縮されたスキャンを必要とする。
パイプラインは、次のようなフィルタを実行する:
WHERE aesthetic_score > 0.8 AND duration > 5
あるいは、オフライン解析、完全埋め込み評価、BM25統計、ビットマップ構築、データ品質チェック、カウント、グループバイなどを実行することもある。
このパターンでは、多くの行を読み込むが、列はわずかしか読み込まない。シーケンシャルI/O、より大きな行グループ、圧縮、列プルーニング、バッチデコーディング、ベクトル化実行を好む。
大きな行グループはここで役立つ。1回のI/Oリクエストで大量の有用なデータを取り出せるようにし、圧縮効率を向上させ、オーバーヘッドを償却するのに十分な連続データを実行エンジンに提供する。複数の列をまとめて読み込む場合、スキャンスループットのためにそれらを整理しておくことは、ベクトル化実行時のキャッシュミスを減らすのにも役立ちます。
Parquetはこのパスに強い。
ANNの結果は狭い行レベルのルックアップが必要
ANN検索で候補行IDが返された後、システムはしばしば以下のようなフィールドをフェッチする必要がある:
caption
embedding
rerank feature
video_uri
metadata
このパターンでは、読み込む行数は数百から数千と少ないが、行IDによる正確なアクセスが必要である。特定の行と列を特定し、必要なバイト範囲のみを取得し、数レコードを取得するためだけに行グループ全体を取得することは避けたい。
ポイント・ルックアップは、スキャニングとはほぼ逆の嗜好を持つ。ポイント・ルックアップは、読み取り粒度を小さくしたいのである。理想的には、ストレージレイヤーは、行IDによって関連するセグメントまたはバイト範囲を見つけ、その範囲のみを読み取り、結果に必要なデータのみをデコードすることができます。
圧縮にもまた、異なるトレードオフがある。スキャンの場合、システムが多くのデータを読み取り、I/Oを節約できるため、圧縮を重くする価値があることが多い。ポイント・ルックアップの場合、1つの行を取得するために、より大きな圧縮ブロックをデコードする必要がある場合、圧縮が不利になることがある。
1つのレイアウトで両方のパスを最適化することはできない
これが核心的な対立点である。スカラー・フィルタリングとアナリティクスは、広く、圧縮され、スキャンに適したレイアウトを求める。ベクター・ルックアップは、狭く、正確で、行アドレス指定可能なレイアウトを求める。
1つのファイルフォーマットで両方をある程度サポートすることはできますが、両方同時に最適化することはできません。
すべての列がParquetに存在する場合、スカラースキャンは快適である。しかし、リコール後のANNルックアップは難しくなる。システムが必要とするのは数百のベクトル、キャプション、またはメタデータレコードだけかもしれないが、ストレージレイヤーはほとんどが無関係な行を含む大きな行グループを読み込まなければならないかもしれない。
ローカルSSDでは、キャッシュとmmapがこのコストの一部を隠すことができる。データがオブジェクト・ストレージに格納されると、コストはより目に見えるものになる。キャッシュ・ミスはすべてリモート・レンジ・リードになる可能性がある。候補行が多くの行グループに散らばっている場合、1つのクエリで複数の読み込みが発生し、それぞれがクエリが必要とする以上のデータを読み込むことになります。レイアウトが悪い場合、1,000の候補行をフェッチすると、数十から数百メガバイト、極端な場合はそれ以上の不要なI/Oが発生します。
行グループを小さくすると、ポイント検索には役立ちますが、スキャンには不利になります。小さすぎる断片は圧縮効率を低下させ、メタデータのオーバーヘッドを増加させ、分析エンジンが依存する長いシーケンシャルリードを壊してしまう。
つまり問題は、魔法の行グループサイズを見つけることではない。問題は、同じデータセットが2つの異なるストレージシステムのように振る舞うことを求められていることだ。
ハイブリッド検索は1つのクエリに両方のパスを強制する
ハイブリッド検索は、競合を無視しにくくする。一つのクエリはまずスカラーフィルターを適用する:
aesthetic_score > 0.8 AND duration > 5
次にANN検索を実行する。
次に、キャプション、ベクトル、メタデータを行IDでフェッチする。
ユーザーにとって、これは1つの検索リクエストである。ストレージレイヤーにとっては、これは分析スキャンであり、低レイテンシーのランダムルックアップである。
だからこそ、ベクターストレージには、より優れたParquet設定以上のものが必要なのだ。実際にどのように読み込まれるかに応じて、異なるカラムを配置する方法が必要なのだ。
3つ目の問題:データセットは1つのエンジンの中には存在しない
最初の2つの問題はデータベース内部で起こる。3つ目はシステム間の境界で起こる。

AIデータパイプラインは多くのシステムにまたがる
動画のワークフローでは、ベクターデータベース自体で起こることはほとんどない。
生の動画はオブジェクトストレージに保存される。クリップ生成はSparkまたはRayで実行される。美的スコアリングはGPUサービスで実行されるかもしれない。キャプション付けはLLM推論パイプラインで実行される。エンベッディングは別のGPUジョブで生成されるかもしれない。スパース・ベクトルはSPLADEサービスから来るかもしれない。オフライン評価、トレーニングデータフィルタリング、ヒューマンレビュー、ガバナンスのジョブはすべて別の場所で実行される。
ベクトル・データベースはオンライン検索に役立つが、データセットは多くのシステムによって生成、修正、評価、拡張される。
プライベート・ストレージ形式は真実のコピーを複数作成する
データベースだけが読み書きできるプライベートな物理フォーマットを使用する場合、すべての外部ジョブはエクスポート、変換、コピー、インポートを必要とする。同じコレクションがデータベース、Sparkのテンポラリディレクトリ、評価出力、ローカルのバックフィルディレクトリに存在する可能性があります。そこで本当の疑問が生じる:
- どのコピーが真実のソースなのか?
- どれが先月のキャプションモデルを含むのか?
- どの行がすでに人間のレビューによって修正されているか?
- どのスパース・ベクトル列がどのモデルによって生成されたのか?
- バックフィル後も有効なベクトルインデックスはどれか?
- この行はどの元のビデオオブジェクトを参照していますか?
小規模であれば、チームは命名規則と手作業によるチェックで乗り切れることもある。数億行、数テラバイトのエンベッディングでは、一貫性の問題になります。
ベクターデータセットには、バージョン管理された共有状態が必要です。
レイクハウス・システムは、構造化データのこの問題のバージョンに対処した。Iceberg、Delta Lake、Hudiは、単にファイルを保存するだけではない。それらの中心的な貢献は、複数のエンジンに同じテーブルの状態を共有させることだ。
ベクターデータベースも同様の機能を必要としているが、状態はより複雑である。テーブルファイルやパーティションだけでなく、ベクターインデックス、テキストインデックス、スパースフィーチャー、削除ログ、統計、行ID範囲、外部ブロブへの参照なども含まなければならない。
問題は、単に "Sparkはmilvusファイルを読めるか?"ではない。
Sparkがスパースベクトル列を埋め戻した後、Milvusはその列がどのバージョンに属し、どの行をカバーし、どのモデルがそれを生成し、いつオンラインクエリがそれを安全に使用できるかをどのように知ることができるのか、という問題である。
答えはストレージモデルにある。
パッチだけでは不十分な理由
これらを3つの別々のエンジニアリングの問題として扱いたくなる。
- 書き込み増幅?バッチングを追加する。
- ポイントリード?キャッシュを追加する。
- 外部システム?エクスポートとインポートのツールを追加する。
これらのパッチは助けになるが、根本的な問題には対処できない。

ビデオの例では、clip_id 、video_id 、duration 、aesthetic_score は短いスカラーフィールドである。これらはフィルタリングや分析に役立つ。
captionはテキストである。BM25、レビュー、修正、埋め戻しに使われる。embeddingは長くて密なベクトルである。これはANNの想起に使用され、後に行レベルのルックアップやリランキングに使用される。embedding_v2は新しいモデル出力であり、多くの場合、元のデータが挿入された後、バックフィルされる。sparse_vectorハイブリッド検索をサポートし、独自のアクセスパターンを持つ。- 生映像はオブジェクト・ストレージに保存する。データベースは、参照、チェックサム、MIMEタイプ、パーサーバージョン、行レベルのリレーションシップを保存する。
- ベクター インデックス、テキスト インデックス、統計、および削除ログは、独自のバージョン セマンティクスを持つ派生オブジェクトです。
これらのオブジェクトは論理的な行を共有しますが、物理的なレイアウトやライフサイクルは同じであってはなりません。
- これらのオブジェクトが1つの通常のテーブルレイアウトに押し込められると、更新にコストがかかります。
- 1つのカラムナー・ファイル・フォーマットに押し込められると、ポイント・リードが高価になる。
- 関連性のないオブジェクトファイルとして扱えば、バージョン管理は脆弱になる。
したがって、ストレージモデルは、データセットが異種であるという事実から出発しなければならない。
そのため、3つの設計要件がある:
- 第一に、異なる列グループは異なる物理フォーマットに格納されるべきである。
- 第二に、これらのカラム・グループには共有の行IDスペースが必要である。
- 第三に、データセットには、どのファイル、インデックス、ログ、統計、オブジェクト参照が現在のビューに属するかを宣言する、バージョン管理されたマニフェストが必要である。
これがMilvusとZilliz Cloudを支える新しいストレージエンジンLoonの設計です。
Loon:進化するベクトルデータセットのためのMilvusとZilliz Cloudを支えるストレージエンジン
上記のすべての問題を解決するために、私たちはMilvusとZilliz Vector Lakebase(Zillizクラウドの次の進化形)のために、進化するベクトルデータセットのために設計された新しいストレージエンジン、Loonを構築しました。
この名前はZillizの鳥の名前の伝統に従っています。ベクターデータベースは、クエリーを実行したり、カラムを埋め戻したり、インデックスを構築したりするたびに、データの湖全体を移動したり、スキャンしたり、書き換えたりする必要はないはずだ。まず、カラム、インデックス、統計情報、削除ログ、オブジェクト参照を含む現在のデータセットのバージョンを理解し、次に実際に必要な部分のみを読み込む。
ハイブリッド・ファイル・フォーマット、行IDアライメント、マニフェストは、3つの独立した機能ではない。ベクトル・データセットは本質的に異種混在である、という同じ設計前提に由来しています。
3つのピース、1つのストレージモデル
ハイブリッド・ファイル・フォーマットは、異なるカラムには異なるアクセス・パターンがあることを認めている。スカラー・フィールドはスキャンやフィルターに適している。ベクターフィールドは効率的な行レベルのルックアップが必要。動画、PDF、画像、音声ファイルなどの生のオブジェクトは、データベースのデータファイル内ではなく、オブジェクトストレージに属する。
行IDアライメントは、これらの列が物理的に分離されていても、同じ論理行を記述していることを認めます。キャプション、エンベッディング、スパースベクター、およびビデオURIは、異なるファイルやフォーマットに存在するかもしれませんが、それでも1つの結果としてまとめられる必要があります。
マニフェストは、データセットが一度書かれただけで放置されるものではないことを認めている。データセットは複数のシステムによって、複数のバージョンにわたって、複数のタスクのために修正される。インデックス、統計情報、削除ログ、外部オブジェクト参照、カラムグループは、すべて同じバージョンのビューに表示されなければならない。
これが、Loon が単なる高速なベクター・ファイル・フォーマットではない理由だ。より高速なフォーマットはポイント・ルックアップを助けるが、スキーマの進化やマルチエンジンの連携を解決するものではない。行IDの整列は、分割された列を単一のテーブルとして動作させるが、どのファイルが現在のバージョンに属するかは特定しない。マニフェストはデータセットの状態を記述できますが、列グループと行IDアライメントがなければ、1つの論理コレクション内の異なる物理レイアウトをきれいに表現することはできません。
異なるカラムグループに対する異なるフォーマット、行を再構築するための共有行IDスペース、そしてデータセットが現在どのような状態であるかをすべてのリーダとライタに伝えるバージョン化されたマニフェストだ。
MilvusとLakebaseにおけるLoonの位置づけ
Milvusでは、古いセグメントビンログストレージレイヤーを、Manifest、ColumnGroup、ファイルフォーマット、ファイルシステムの抽象化を中心に構築されたモデルに置き換える。Zilliz Vector Lakebase(ZillizCloudの次の進化形)では、Vector Lakebaseアーキテクチャに同じ方向性が適用されます:ベクターデータベースのサービングパスを高速に保ちながら、基礎となるデータの進化、分析、外部システムとの連携を容易にします。
Milvusの上位コンポーネントは、従来通りの役割を担っている。Proxyはルーティングを処理します。QueryCoordとDataCoordはスケジューリングを処理します。IndexNodeはインデックスを構築する。コレクション、インサート、検索、ハイブリッド検索用のアプリケーション向けAPIはマニフェストファイルやColumnGroupを公開する必要はありません。
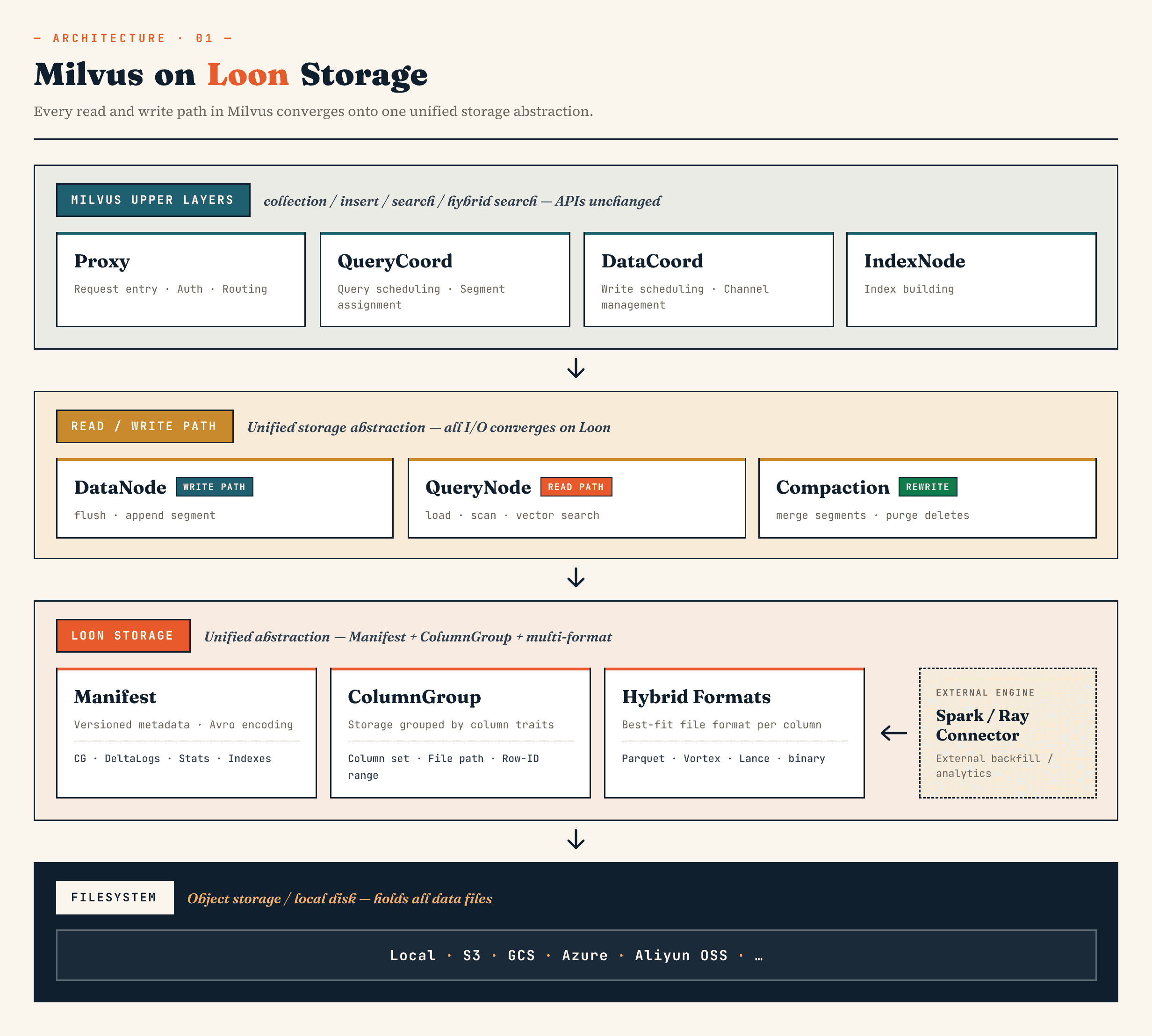
変更はその下にあります。
DataNode、QueryNode、segcore、コンパクション、外部コネクターは同じストレージ抽象化を通して操作できる。なぜなら、データセットはもはやデータベースによってのみ書き込まれ、読み込まれるものではないからです。データセットは外部コンピューティングシステムによって拡張され、オンライン検索によって同時に消費される可能性があるからだ。
ハイレベルでは、レイヤーは次のようになる:
Manifest
→ ColumnGroup
→ file format layer
→ filesystem abstraction
マニフェストは、データセットのバージョン管理された状態を記述する。ColumnGroupsは、論理的なコレクションを列の物理的なグループにマッピングします。ファイル・フォーマット・レイヤーは、各ColumnGroupに適切なフォーマットを選択させます。ファイルシステムの抽象化は、オブジェクト・ストレージとローカル・ストレージにまたがって機能する。
重要な点は、ハイブリッド・ファイル・フォーマット、行IDアライメント、マニフェストは別々の機能ではないということです。これらは一緒になってストレージ・モデルを定義します。
Loonがどのように異なるColumnGroupsを保存するか、どのようにそれらを行に整列させるか、そしてどのようにManifestがそれらのファイルをバージョン管理されたデータセットに変えるかです。
設計 1: 適切な列グループに適切なファイル形式を使用する
列によってアクセスパターンは異なります。それらを同じファイル形式に強制するべきではない。
Loonは論理的なコレクションをColumnGroupに分離します。
- スカラーフィールド、フィルターフィールド、ビジネスキー、統計フィールドは、スキャン、フィルター、集計、クエリ計画に使用されることが多い。これらのフィールドは、圧縮、カラムのプルーニング、エコシステムの互換性から恩恵を受けます。Parquetはこれらの列に適しています。
- 密なベクトル、疎なベクトル、再ランク特徴量は、行IDによるANNリコール後に読み込まれることが多い。これらは、低レイテンシのランダムアクセス、正確なバイト範囲の読み出し、選択的なデコードを必要とする。セグメント指向のレイアウトが適している。Loonはこの方向でVortexを使用している。
- 動画、PDF、画像、音声ファイルなどの生のオブジェクトは、ベクターデータベースのデータファイルに埋め込むべきではありません。それらはオブジェクトストレージに残すべきです。データベースは、参照、チェックサム、MIMEタイプ、パーサーのバージョン、行レベルの関係を記録します。
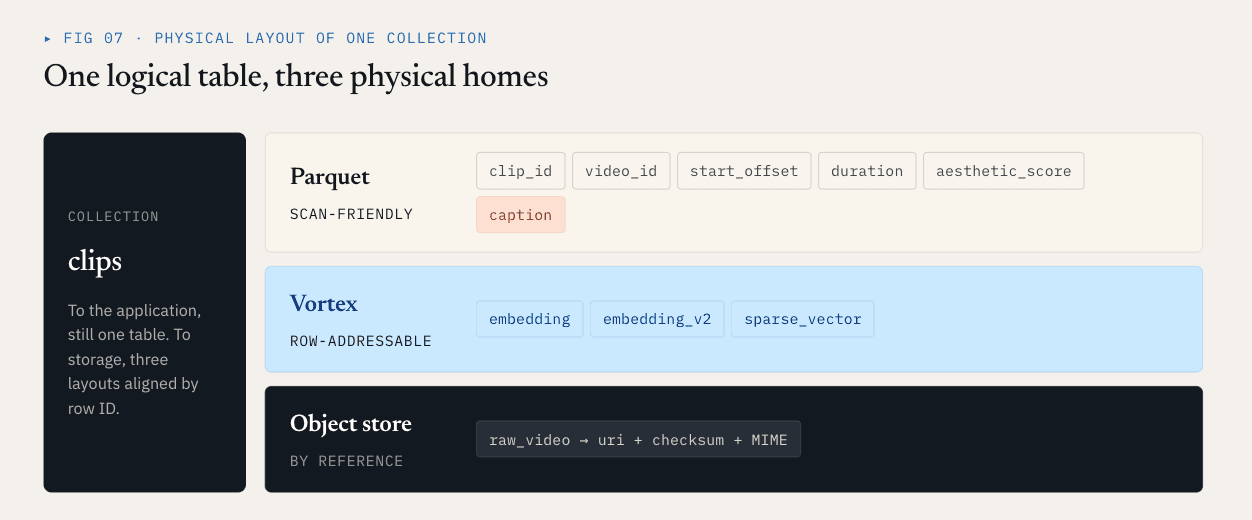
ビデオの例では、物理的なレイアウトはこのようになります:
Parquet ColumnGroup:
clip_id / video_id / start_offset / duration / aesthetic_score / caption
Vortex ColumnGroups:
embedding
embedding_v2
sparse_vector
Object storage:
raw video objects
アプリケーションにとっては、これはまだ1つのコレクションである。アプリケーションにとって、これはまだ1つのコレクションである。ストレージ・レイヤーにとって、そのコレクションの異なる部分は、異なる物理フォーマットを使用する。これは、不要な書き換えを直接的に減らします。embedding_v2 を追加すると、新しいベクトルColumnGroupとManifestコミットになります。キャプション・カラム、スカラー・メタデータ、既存のエンベッディング・カラムを書き換える必要はない。
同じ考え方が、スパースベクトル、リランクフィーチャ、その他の派生フィールドにも適用されます。新しい列が物理的に独立し、行IDで整列できる場合、無関係な列を同じ書き換えパスでドラッグする必要はない。
Loonはファイルフォーマットの使用にも適応する。
Parquetの場合、デフォルトの設定はベクターが多いデータには必ずしも理想的とは言えない。64MBの行グループはポイント検索には大きすぎる可能性があり、少量のランダムリードで必要以上のデータが引き出される可能性があるからだ。Loonは、関連するパスの行グループを1MBに制限し、ベクトル列のディクショナリ・エンコーディングなどのエンコーディングが、ランダムなベクトル・データに役立たない場合は無効にします。
Vortexにとって、より重要な作業はレイアウトだ。Loonは、スキャン効率とポイント・ルックアップのバランスをとるレイアウトを採用している。行グループ内では、スキャンをサポートするために、関連する列のセグメントを近くに配置することができる。オペレーションを実行するために、サブセグメント・リードを使用することで、システムはセグメント全体をプルするのではなく、関連するバイトのみをフェッチすることができる。
Loon は、読み取り専用の Lance 統合もサポートしているため、互換性が重要な場合は、既存の Lance データセットを ColumnGroups としてマウントすることができます。
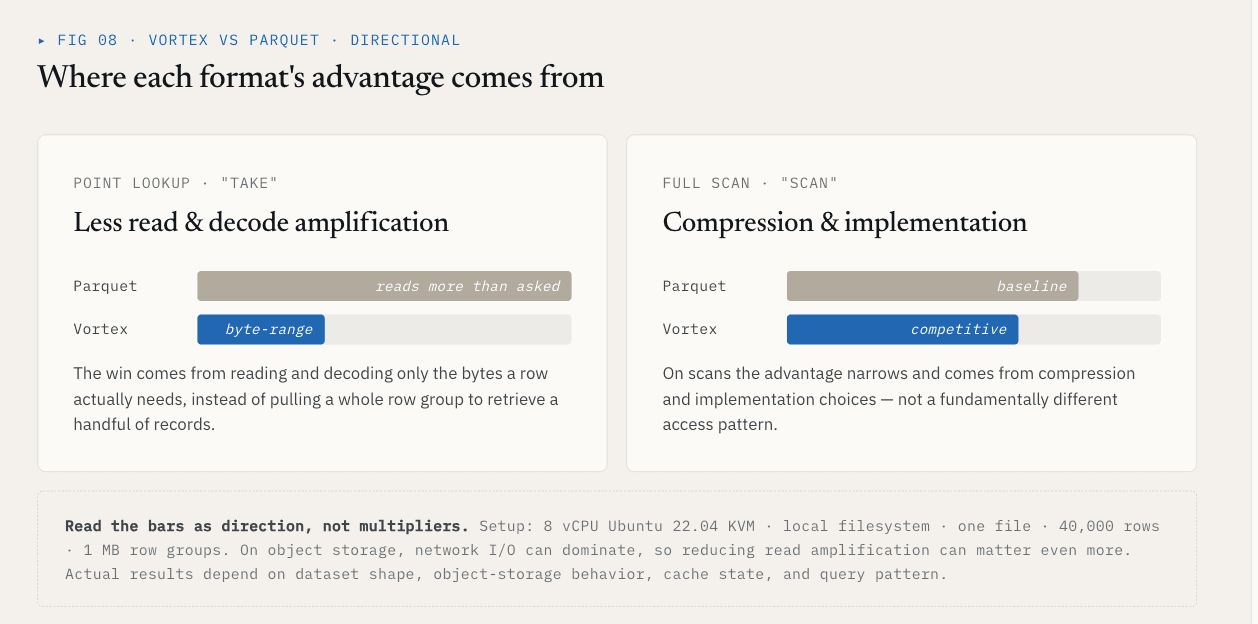
ベンチマークの結果
40,000行の単一ファイルとスキーマ({id: int64, name: utf8, value: float64, vector: list<float32>[128]} )を使用したローカルテストにおいて、Vortexは1MBの行グループを使用したParquetに対して以下のような結果を示しました:
| 操作 | Vortex | Parquet | 差分 |
|---|---|---|---|
| Take、K=1000ランダム行 | 5.8 ms | 144 ms | 25倍高速 |
| ベクトル列フルスキャン | 21ミリ秒 | 142 ms | 6.76倍高速 |
| ファイルサイズ(~21 MBの生データ | 6.62 MB | 7.16 MB | 7%小さい |
take の結果は、読み取りとデコードが必要な無関係なデータの量を減らしたことによる。スキャンの結果は、圧縮と実装の選択に由来する。
これらの数値は、セットアップに添付されたままであるべきだ:8 vCPU Ubuntu 22.04 KVM、ローカルファイルシステム、1ファイル、40,000行、1MB行グループ、上記のスキーマ。オブジェクト・ストレージでは、ネットワークI/Oが支配的になることがあるため、リード増幅を減らすことがより重要になります。実際の結果は、データセットの形状、オブジェクトストレージの動作、キャッシュの状態、クエリーパターンによって異なります。
重要なのは、すべての列がVortexを使うべきだということではありません。
重要なのは、ベクトルデータセットにはColumnGroupレベルでのファイルフォーマットの選択が必要であるということです。
デザイン2:行IDを通して物理ファイルを整列させる
ハイブリッド・ファイル・フォーマットは1つの問題を解決します:異なるカラムが、そのカラムに最適なフォーマットで使用できるようになります。
しかし、これによって2つ目の問題が発生します。スカラーフィールドがParquetに、ベクトルがVortexに、そして未加工のオブジェクトがオブジェクトストレージに存在する場合、システムはそれらを1つのコレクションとしてどのように扱うのだろうか?
Loonは行IDのアライメントでこれを解決する。
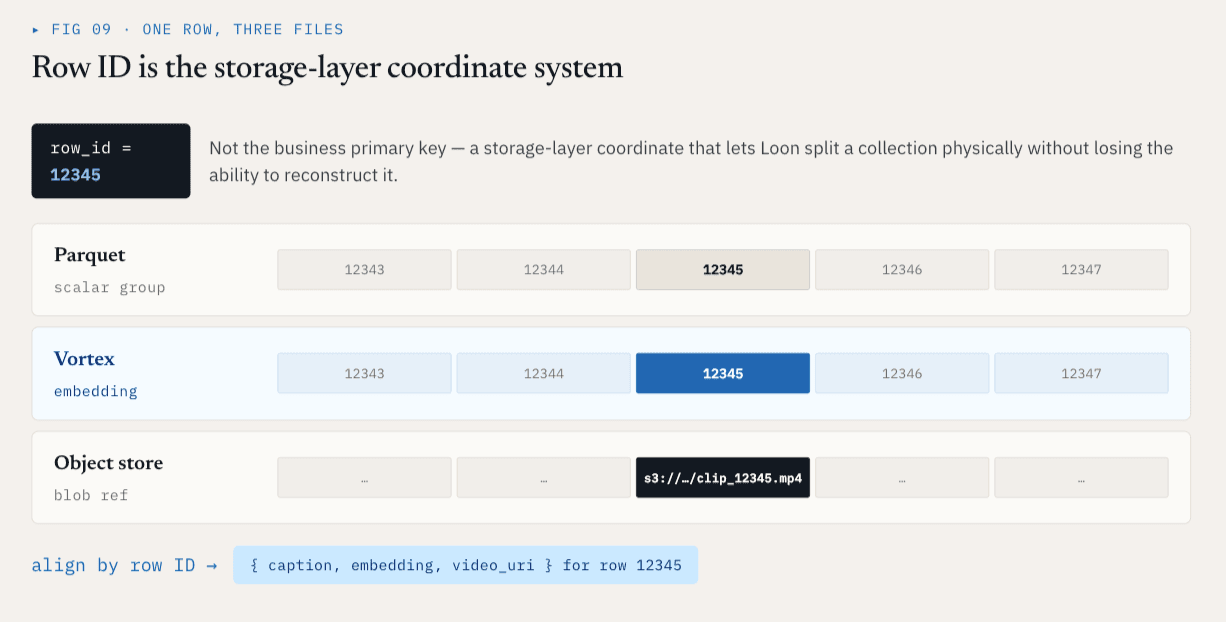
行IDはストレージ層の座標系です。
各物理ColumnGroupFileは、ファイルパスと、それがカバーする行IDの範囲を記録します:
path
start_index
end_index
異なるColumnGroupは、異なるファイルやフォーマットであっても、同じ行ID空間をカバーすることができます。
行ID12345 、スカラーメタデータはParquet ColumnGroupに、エンベッディングはVortex ColumnGroupに、そして生映像はオブジェクトストレージ参照で表現されることがあります。論理的には、これらはまだ1つの行である。これは、ストレージ層に安定した座標系を与える。
行IDはビジネスの主キーではない。それは、Loonが論理的に再構築する能力を失うことなく、物理的にコレクションを分割できるようにするストレージ層の座標系である。
新しいカラムは古いカラムを書き換える必要がない
embedding_v2 を追加しても、元のキャプション、メタデータ、embedding_v1 ColumnGroups を書き換える必要はありません。Loonは、新しいベクトルColumnGroupを記述し、それがカバーする行IDの範囲を記録し、マニフェストを通じてその変更をコミットできます。
同じことが、スパースベクトル、リランクフィーチャ、または後で到着するその他の派生フィールドにも適用されます。
新しいColumnGroupが正しい行ID範囲をカバーする限り、無関係なデータを強制的に移動させることなく、同じ論理コレクションに参加できます。
削除とコンパクションはよりターゲットを絞ることができます。
行IDの整列は削除にも役立ちます。
削除は、まず削除ログで表現できます。行は論理レベルでは見えなくなり、物理的なクリーンアップはコンパクションまで延期されます。最終的にコンパクションが実行されると、影響を受ける行に関連付けられた全てのColumnGroupを書き換える必要はありません。クリーンアップが必要なColumnGroupに集中することができます。
すべての列が同じコストプロファイルを持つわけではないので、これは重要です。短いスカラーのColumnGroupを書き換えるのと、数百ギガバイトの密なベクトルを書き換えるのとでは、大きく異なります。
ハイブリッド検索は必要な列だけをフェッチできる
行IDのアライメントは、ハイブリッド検索をハイブリッドファイル形式の上で実用的にするものでもある。
ANN検索が候補となる行IDを返した後、システムは最終結果に必要なフィールド(キャプション、メタデータ、ベクトル、リランク・フィーチャー、オブジェクト参照)のみをフェッチすることができる。
例えば、あるクエリーは、以下のようなフィールドを必要とする:
caption
embedding
video_uri
これらのフィールドは、異なる ColumnGroups に存在します。Loon は、行 ID 範囲で関連ファイルを検索し、必要なバイト範囲を読み取り、結果を組み立てることができます。
行 ID のアライメントがなければ、ハイブリッド フォーマットは別々のファイルが並んでいるだけです。行IDアライメントがあれば、これらは1つの論理的なコレクションとして動作します。
Packed Readerは上位レイヤから分割を隠す
これを使用可能にするランタイムコンポーネントは、Packed Readerである。
上位レイヤーは、統一されたArrow RecordBatchストリームを見る。その下で、データは異なるファイルフォーマットの複数のColumnGroupから来るかもしれない。Packed Readerは、これらの違いを隠し、行IDの範囲によってデータを整列し、制御されたメモリ使用でマルチファイルI/Oをスケジュールします。
また、行IDによる直接のtake 。行IDのセットが与えられると、関連するColumnGroupFilesを探し出し、範囲読み込みを行い、要求されたフィールドを返す。
ビデオワークフローでは、ANN クエリはcaption 、embedding 、video_uri を必要とする。Packed Reader は、無関係な列に触れることなく、スカラー ColumnGroup とベクトル ColumnGroup をフェッチすることができます。
これが、"別々のファイル "と "複数の物理レイアウトを持つテーブル "の違いです。
デザイン3:マニフェストを真実のソースにする
ハイブリッド・ファイル・フォーマットは、データが物理的にどのように格納されるかを定義します。行IDのアライメントは、分離されたColumnGroupが単一の論理テーブルを形成する方法を決定します。どのファイル、ログ、統計、インデックス、オブジェクト参照が現在のバージョンのデータセットに属するのか?これがマニフェストの仕事である。

オブジェクト・ストレージのディレクトリだけでは不十分
オブジェクト・ストレージはデータベース・カタログではない。ディレクトリには、古いファイル、新しいファイル、失敗したジョブ出力、一時ファイル、削除ログ、古いスナップショットから参照されたままのファイル、クリーンアップ待ちのファイルなどが含まれる可能性があります。ファイルが存在しても、それが現在のデータセットのバージョンに属しているとは限りません。
Loon のデータセットは、次のようなディレクトリで構成されています:
_metadata/
_data/
_delta/
_stats/
_index/
しかし、ディレクトリ構造は真実の源ではありません。マニフェストがそうである。読者はディレクトリを列挙したり、たまたま存在したファイルから状態を推測したりすべきではない。彼らは現在のマニフェストを読み、それが宣言しているバージョン別ビューに従うべきである。
マニフェストはデータセットの1つのバージョン・ビューを定義する
マニフェストは、あるバージョンのデータセットを定義する。その記録は
- どのColumnGroupsが存在するか
- どの行IDの範囲をカバーしているか
- 各ColumnGroupが使用する物理フォーマット
- ファイルの保存場所
- どの削除ログが有効か
- どの統計が利用可能か
- どのインデックスが存在するか
- どの外部ブロブを参照しているか
- これらの統計情報またはインデックスがカバーする列と行の範囲はどれか
更新のたびに新しいマニフェスト・バージョンが書き込まれる。バージョンNを開いた読者は、バージョンNのデータセットの安定したビューを見ることができる。
マニフェストが追跡するのはテーブル ファイルだけではない
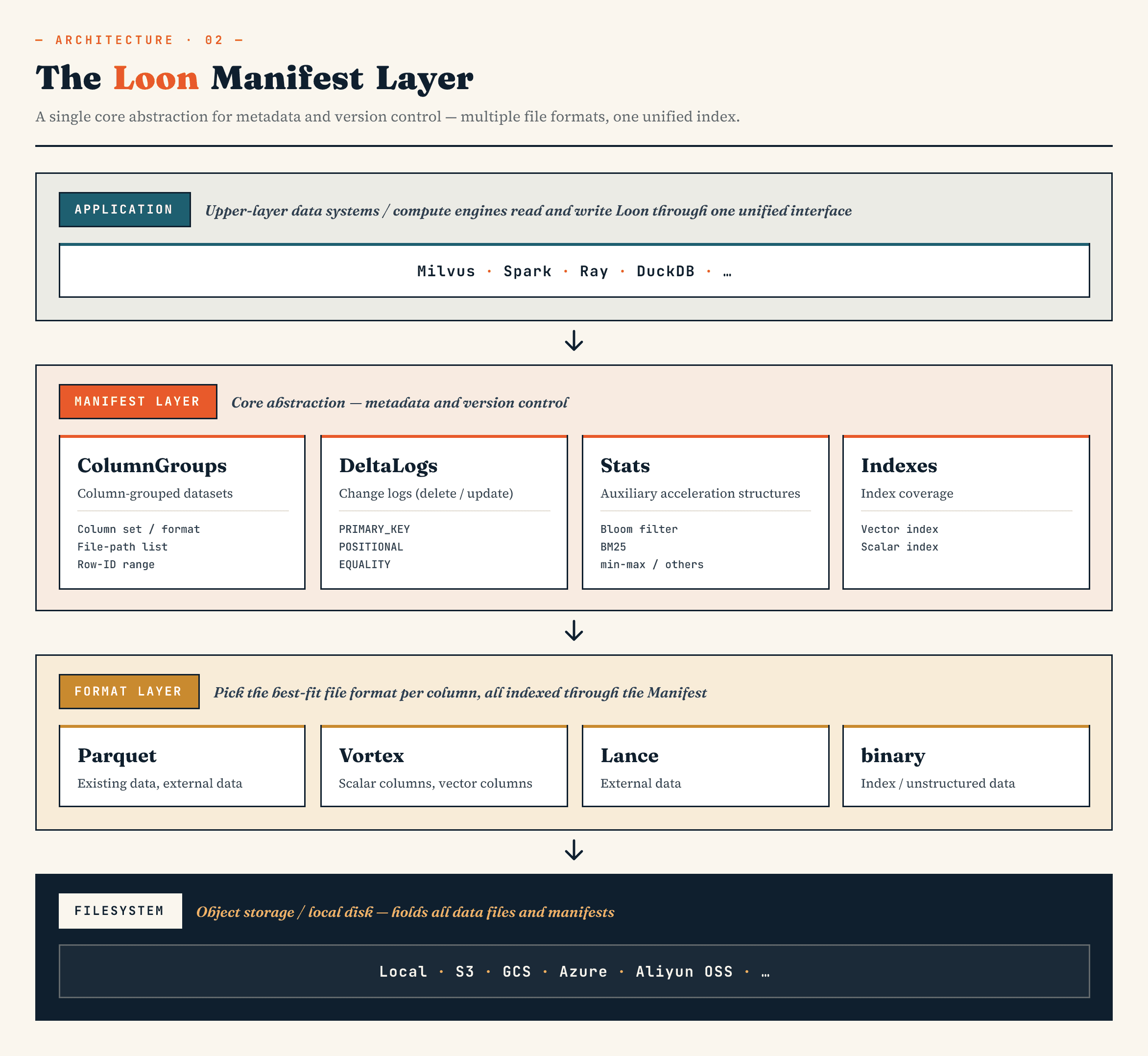
Loonでは、マニフェスト本体はApache Avroでエンコードされ、4つの主要セクションで構成される。
- ColumnGroupsは、カラム、フォーマット、ファイル、行IDの範囲を記述する。
- DeltaLogs は削除を記述する。異なる削除タイプは、クライアントからの主キー削除、内部コンパクションからの位置削除、外部エンジンからの等価削除など、異なる変更源をカバーします。
- 統計には、ブルームフィルタ、BM25統計、最小/最大値などの計画メタデータが含まれます。
- インデックスは、インデックス・タイプ、パラメータ、対象列、行IDの範囲を記述します。これには、HNSWやIVFなどのベクトルインデックス、テキストインデックス、転置インデックス、ビットマップインデックス、および関連構造が含まれる。
これが Loon が従来のテーブルマニフェストと異なる点である。
ベクターデータセットはデータファイルやパーティションだけでなく、ベクターインデックスも追跡する必要がある。また、ベクトルインデックス、テキストインデックス、スパースフィーチャー、削除ログ、統計、外部オブジェクト参照、およびそれらを接続する行 ID 範囲も追跡する必要がある。
マニフェストはデータベース以外からも書き込み可能でなければなりません。
最も重要なのは、マニフェストが何を含むかだけではありません。誰が書き込めるかです。
- データベースだけがマニフェストを書き込める場合、それは内部メタデータのままです。よりクリーンなメタデータであっても、1つのエンジンのプライベートなメタデータであることに変わりはありません。
- 外部エンジンが新しいColumnGroups、stats、およびManifestエントリを生成できる場合、Manifestは調整インターフェースになります。
- 例えば、Sparkジョブはスパース・ベクトル列を埋め戻すことができます。これは新しいColumnGroupを書き込み、行カバレッジと統計情報を記録し、新しいManifestをコミットします。オンラインクエリは、ジョブ中に古いバージョンを読み続けることができます。コミットが成功すると、新しいバージョンが見えるようになります。
これはIcebergやDelta Lakeに似ているが、オブジェクトモデルはより広い。ベクターデータセットは、テーブルファイルやパーティションだけでなく、ベクターインデックス、テキストインデックス、スパースフィーチャー、削除ログ、統計情報、ブロブ参照、行ID範囲を追跡する必要がある。
楽観的コミットでバージョン更新をシンプルに
コミットごとに新しいマニフェスト・バージョンが書き込まれます。ライターはバージョンNに基づいて新しいコンテンツを構築し、manifest-{N+1}.avro 。オブジェクト・ストレージの条件付き書き込みまたは世代一致セマンティクスにより、そのバージョンが既に存在する場合、コミットが失敗することがあります。その後、ライターは新しいバージョンに対して再試行できる。
これにより、Loonは、すべての更新を重く、一貫性の強い調整パスで強制することなく、楽観的な並行性を実現する。マニフェストがなければ、マルチフォーマットやマルチエンジンのストレージは、結局、命名規則と手作業による調整になってしまう。それは小さなデータセットには有効かもしれない。TBスケールのベクトルデータには通用しない。
マニフェストは、異種ファイルを複数のシステムが安全に読み取り更新できるデータセットに変えるものだ。
ストレージがバージョン管理されると、ユーザーにとって何が変わるか
アプリケーション開発者にとって、Loonが新たなAPIの負担になることはないはずだ。
コレクション、インサート、検索、ハイブリッド検索など、使い慣れたMilvusのコンセプトはそのまま使える。通常のアプリケーション開発において、マニフェストファイル、ColumnGroups、行ID範囲、ファイルレイアウトについて考える必要はない。
変化はその下にある。ストレージは、AIデータセットが実際にどのように進化していくかをより意識するようになる。
新しいエンベッディングを追加しても、古いデータは移動しない
以前は、既存のコレクションにembedding_v2 、データをエクスポートし、新しいモデルをトレーニングし、ベクトルを生成し、SDK経由でコレクションを再インポートまたは一括更新する必要がありました。この経路は、バージョン追跡、失敗したジョブの再試行、インデックスの再構築、配信の影響、整合性チェックなど、多くの運用作業を発生させる。
Loonを使用すれば、スキーマの進化と新しいColumnGroupのコミットで済みます。新しい埋め込みカラムは、独自の物理的なColumnGroupとして記述され、行IDで整列され、マニフェストを通じて可視化されます。古いキャプション列、スカラメタデータ列、および元の埋め込み列は、移動する必要はありません。
バックフィルは、クライアント側の更新ループを必要としません。
AIデータの更新の多くは、バックフィルです。あるチームは、ハイブリッド検索が重要になった後に、スパースベクトルを追加するかもしれない。新しいモデルがトレーニングされた後、再ランク機能を追加する。人間のレビュー後にキャプションを修正する。ポリシーの更新後にガバナンスタグを追加することもある。
従来のレイアウトでは、データがSparkやRay、その他の外部エンジンによって生成された場合でも、これらの変更はクライアントSDKの更新やデータベースのみの書き込みパスによって行われることが多い。
Loonでは、外部の計算システムが新しいColumnGroupを生成し、マニフェストを通じてコミットすることができます。データベースは、もはやすべての書き換えのための唯一のエントリポイントである必要はありません。
オフライン分析では、別の真実のコピーを必要としない
以前は、チームはオフラインで評価や分析を行うために、オンラインコレクションをParquetにダンプすることがよくありました。これでは、同じデータセットにオンラインコレクションと解析コピーの2つのバージョンができてしまいます。キャプションが修正され、エンベッディングが再生成され、削除ログが適用され、インデックスが再構築されると、チームはどちらのコピーが最新かを確認しなければなりません。
マニフェストベースのストレージモデルでは、解析エンジンは、サービング・システムと同じバージョン管理されたデータセット・ビューを読むことができる。必要な列のみを投影し、関連する行範囲のみをスキャンし、手動でエクスポートされたスナップショットではなく、宣言されたデータセットのバージョンに対して作業することができます。
削除と訂正は、変更されたものだけに触れるべきである。
AIデータセットでは、削除、キャプションの修正、ラベルの修正、ガバナンスの更新は日常的に行われる。すべての長いベクトル列を同じ書き換えパスで強制するべきではありません。
Loon では、ログの削除はまず論理削除として扱われる。後でコンパクションを行うことで、無関係なデータを書き換えることなく、影響を受けた ColumnGroup をクリーンアップできます。短いテキストフィールドが変更された場合、同じ論理行を共有しているからといって、ストレージレイヤーが何百ギガバイトもの高密度ベクトルを書き換える必要はない。
外部エンジンはワークフローの一部となる。
より大きな変化は、外部エンジンがもはやベクターデータベースの外のシステムとして扱われなくなったことだ。
Spark、Ray、評価ジョブ、ラベリングシステム、ガバナンスパイプラインは既にデータの多くを生成し、修正している。ストレージレイヤーは、常にエクスポート、コピー、再インポートするのではなく、単一の真実のソースを中心にコラボレーションすることを可能にする必要がある。
Manifestのバージョンはそれを可能にする。マニフェストは、オンラインサービス、オフライン分析、バックフィルジョブ、コンパクションにデータセットの共有ビューを提供する。
これらは内部ストレージの詳細のように聞こえるかもしれないが、チームがAIデータセットをいかに迅速に反復できるかに影響する。モデルの変更、フィーチャーの埋め戻し、キャプションの修正、品質フィルター、インデックスの再構築はすべて、同じ質問に依存している。
これがストレージモデルの実用的な価値である。
LoonはMilvus 3.0ベータとZilliz Vector Lakebaseで利用できる。
LoonはMilvus 3.0ベータ版で利用可能であり、Zilliz Cloudの次の進化であるZilliz Vector Lakebaseのストレージレイヤーの一部でもある。そして、このリリースは3つのコア分野にフォーカスしている:
- マニフェスト。目標は、書き込み、バックフィル、削除、統計、インデックス更新が、読者が一貫して開くことができるバージョン管理されたデータセット・ビューを生成することである。読者にとって、これはクエリが特定のマニフェスト・バージョンを開き、データセットの安定したビューを見ることができることを意味する。ライターにとって、これは新しいデータファイル、削除ログ、統計情報、インデックスファイルを最初に準備し、バージョン管理されたコミットによって可視化できることを意味します。
- ColumnGroupとフォーマットのサポート。Parquetはスカラーとエコシステムに適したカラムをサポートします。Vortexはベクトルを多用するアクセスパターンをサポートする。Lanceは、既存のLanceデータセットとの互換性のために、読み取り専用モードで統合することができる。
- レイクのインデックス。スカラー統計、フィルタリング・インデックス、テキスト転置インデックスは、行範囲によるマニフェスト・ベースのプランニングに参加できる。レイクネイティブのベクトルインデックスはより複雑です。HNSWとIVFはオブジェクトストレージ上での動作が異なり、特にHNSWはランダムアクセスとキャッシュの局所性に敏感です。特にHNSWはランダムアクセスとキャッシュの局所性に敏感であり、ローカルSSD用に設計されたレイアウトを単純に再利用して同じ結果を期待することはできない。
課題はまだある
- SparkとRayは、すべてのバックフィルをクライアントSDKのループを通して強制することなく、ColumnGroupsとManifestコミットを生成することができるはずなので、外部書き込みパスは重要です。
- 多くのチームがすでにIceberg、Delta Lake、Trino、DuckDB、Athenaなどのカタログやクエリエンジンを使用しているため、Lakehouseの相互運用性は重要である。ベクターデータは、ベクター検索のパフォーマンスを失うことなく、そのエコシステムに参加できなければならない。
- グラフ・インデックスと転置構造は、オブジェクト・ストレージ上でのアクセス・パターンが異なるため、インデックス・レイアウトは重要である。
- 生の動画、PDF、画像、音声ファイルには、派生するベクターデータセットに合わせた参照管理、バージョン管理、削除動作が必要なため、ラージオブジェクトのセマンティクスが重要になる。
正確なリリース動作、デフォルト設定、移行パスは、関連するMilvusとZilliz Cloudのリリースノートに従ってください。しかし、ストレージの方向性は明確だ。ベクターデータベースには、サービングレイヤーの下にバージョン管理されたレイクネイティブな基盤が必要だ。
Zilliz Vector Lakebaseの下でLoonを試す
現在のスタックが、オンライン・サービング、オフライン分析、バックフィル、外部データレイク・ワークフローを別々のシステムに分離しているなら、Zilliz Vector Lakebaseは一見の価値がある。Zilliz Cloudで試すことができる。新規メール登録で100ドル分のクレジットを無料で差し上げます。ユースケースについてのご相談も大歓迎です。
また、Milvus 3.0のリリースをフォローし、オープンソースエンジンでLoonがどのように進化していくかを確認することもできます。
Zilliz Vector Lakebaseがもたらすもの:
- 様々なリアルタイムのパフォーマンスとコストのトレードオフのための階層化されたサービング
- 常時コンピュート不要の大規模ワークロードや探索的ワークロードのためのオンデマンド検索
- 外部データレイク検索により、既存のデータレイクデータに直接インデックスを付け、検索することができます。
- ベクトル、テキスト、JSON、地理空間データにわたるフルスペクトル検索と、ハイブリッド検索および再ランク付け
- Vortex上に構築された統合されたレイクネイティブストレージ。ベクトルが多いデータに対して、より高速で低コストのランダムリードを実現するために設計されたオープンフォーマット。
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word



