Mengapa Kami Membangun Loon: Mesin Penyimpanan untuk Data AI yang Tidak Pernah Berhenti Berubah.
Blog ini awalnya diterbitkan di zilliz.com dan telah diterbitkan ulang dengan izin.
Poin-poin penting
Ini adalah pembahasan teknik yang panjang dan mendalam, jadi inilah poin-poin penting sebelum kita membahas detailnya.
- Kumpulan data AI bukanlah tabel statis. Baris yang sama terus berubah ketika tim mengganti model penyematan, menambahkan vektor yang jarang, merevisi keterangan, mengisi ulang label, membangun kembali indeks, dan menjalankan analisis offline.
- Tata letak penyimpanan tradisional rusak dalam tiga cara: kolom vektor yang panjang membuat pengisian ulang menjadi mahal, format file tunggal tidak dapat melayani pemindaian dan pembacaan titik dengan baik, dan penyimpanan basis data pribadi memaksa saluran pipa eksternal untuk membuat salinan ekstra dari kebenaran.
- Loon adalah mesin penyimpanan baru untuk Milvus dan Zilliz Vector Lakebase. Mesin ini dibangun berdasarkan format file hibrida, penyelarasan ID baris, dan Manifes yang mendefinisikan status versi set data.
- Tujuannya adalah untuk memungkinkan dataset vektor tunggal untuk mendukung pencarian online, analisis offline, pengisian ulang, pemadatan, dan komputasi eksternal tanpa terus-menerus menyalin, menulis ulang, atau mengimpor ulang data.
Pendahuluan
Untuk sementara waktu, ada satu argumen yang menentang basis data vektor yang terdengar masuk akal.
Basis data tradisional sudah menyimpan bilangan bulat, string, JSON, gumpalan, dan indeks. Mengapa tidak menambahkan tipe _vector_ , membangun indeks ANN di sampingnya, dan menyebutnya sebagai hari?
Untuk pencarian semantik awal, hal ini bekerja dengan cukup baik. Kolom vektor ditambah indeks dapat mendukung demo, aplikasi RAG kecil, atau fitur pencarian internal. Masalahnya muncul kemudian, ketika dataset mulai berperilaku kurang seperti tabel dan lebih seperti sistem data AI.
Dataset vektor produksi memiliki baris, kunci utama, bidang skalar, dan kolom yang dapat ditanyakan. Dalam hal ini, dataset ini terlihat seperti tabel basis data. Namun, dataset ini juga memiliki skala dan bentuk alur kerja seperti data lake. Ini mungkin berisi ratusan juta catatan. Data lake berulang kali dibaca dan ditulis ulang oleh Spark, Ray, DuckDB, pipeline pelatihan, pekerjaan evaluasi, dan sistem kualitas data.
Hal ini juga tergantung pada penyimpanan objek. Objek sumber sering kali berupa video, gambar, PDF, file audio, atau dokumen web yang disimpan di S3, GCS, OSS, atau penyimpanan objek lainnya. Basis data menyimpan referensi, metadata, fitur turunan, dan indeks. Kemudian menambahkan hal-hal yang tidak dapat dikelola oleh model penyimpanan tradisional sebagai objek kelas satu: penyematan padat, vektor yang jarang, keterangan, indeks vektor, indeks teks, log hapus, statistik, versi model, versi parser, referensi gumpalan eksternal, dan hubungan versi di antara semuanya.
Di situlah "cukup tambahkan kolom vektor" mulai rusak. Masalahnya bukan apakah database dapat menyimpan byte vektor. Banyak sistem yang bisa. Pertanyaan yang lebih sulit adalah apakah model penyimpanan dapat menangani bagaimana data vektor berubah, bagaimana data vektor ditanyakan, dan bagaimana data vektor dibagikan di seluruh tumpukan data AI.
Inilah alasan kami membangun Loon, mesin penyimpanan baru untuk Milvus dan Zilliz Vector Lakebase (evolusi berikutnya dari Zilliz Cloud).
Loon dirancang dengan tiga ide:
- Gunakan format fisik yang berbeda untuk berbagai jenis kolom.
- Menyelaraskan kolom-kolom tersebut melalui ruang ID baris bersama.
- Gunakan Manifest untuk mendefinisikan status versi kumpulan data.
Untuk mengetahui mengapa bagian-bagian tersebut penting, mari kita mulai dengan alur kerja multimodal yang umum.
Dataset vektor tidak pernah benar-benar selesai.
Bayangkan sebuah tim AI sedang membangun set data video untuk pelatihan multimodal.
Sebuah video panjang diunggah ke penyimpanan objek. Sebuah pipeline memotongnya menjadi beberapa klip berdasarkan perubahan adegan, batas pengambilan gambar, atau jendela waktu. Klip yang terlalu panjang atau terlalu pendek, buram, terduplikasi, atau berkualitas rendah disaring. Klip yang tersisa dinilai oleh model estetika, diberi teks oleh model lain, disematkan oleh model bahasa visi, dan disimpan dalam basis data vektor untuk pencarian, deduplikasi, dan pemfilteran data pelatihan.
Pada tingkat tinggi, alur kerja terlihat sederhana:
video
→ clips
→ metadata
→ aesthetic_score
→ caption
→ embedding
→ search / dedup / training data filtering
Namun, dataset tidak datang dalam bentuk yang lengkap.
- Pada minggu pertama, tabel mungkin hanya berisi
clip_id,video_id,start_offset, danduration. - Pada minggu kedua, tim menambahkan
aesthetic_score. - Pada minggu ketiga, model teks berjalan, dan setiap klip mendapatkan
caption. - Pada minggu keempat, model penyematan pertama berjalan secara online, dan setiap klip mendapatkan penyematan CLIP 768 dimensi.
- Sebulan kemudian, tim mengganti model dan mengisi ulang
embedding_v2, sekarang dengan 1024 dimensi. - Dua bulan kemudian, pencarian hibrida menjadi sebuah persyaratan, sehingga tim menambahkan kolom vektor yang jarang.
- Tiga bulan kemudian, keterangan menjalani peninjauan manusia dan harus diperbaiki di tempat.
Dataset tidak pernah selesai. Ia terus mengumpulkan interpretasi baru dari baris yang sama.
Itulah salah satu perbedaan utama antara data vektor dan data bisnis tradisional. Baris yang sama akan diproses ulang berulang kali. Dan skala mengubah hal ini dari ketidaknyamanan menjadi masalah penyimpanan: kumpulan data multimodal sering kali bukan jutaan catatan tetapi ratusan juta atau miliaran. LAION-5B adalah referensi yang berguna untuk bentuknya - miliaran pasangan gambar-teks, masing-masing dengan metadata, keterangan, dan penyematan. Jadi, bagian yang sulit bukanlah penyisipan pertama. Bagian yang sulit adalah segala sesuatu yang terjadi setelah kumpulan data mulai berevolusi. Evolusi itu memperlihatkan tiga masalah.
Masalah pertama: kolom yang panjang membuat amplifikasi penulisan menjadi mahal
Format kolom seperti Parquet sangat baik untuk banyak beban kerja analitis. Format ini bekerja dengan baik ketika skema cukup stabil, data lebih sering dibaca daripada ditulis ulang, pemindaian hanya menyentuh sebagian kecil kolom, dan kompresi menjadi penting. Itulah dunia di mana banyak format analitik dioptimalkan.
Baris vektor jauh lebih lebar daripada baris analitik
TPC-H lineitem adalah garis dasar yang baik. Format ini memiliki 16 kolom: kunci bilangan bulat, nilai desimal, tanggal, string pendek, dan kolom komentar kecil. Satu baris yang belum dikompresi berukuran sekitar 150 byte. Setelah dikompresi, ukurannya mungkin jauh lebih kecil. Dengan kelompok baris 64 MB, sistem penyimpanan dapat mengemas ratusan ribu baris ke dalam satu kelompok.
Kumpulan data vektor tidak terlihat seperti itu.
Dataset gambar-teks gaya LAION jauh lebih dekat dengan apa yang dihasilkan oleh banyak pipeline AI saat ini. Setiap baris masih memiliki metadata biasa: URL, keterangan, lebar, tinggi, skor kualitas, label, dan sebagainya. Tetapi setelah penyematan ditambahkan, bentuk fisik baris berubah.
Vektor CLIP 768 dimensi membutuhkan sekitar 1,5 KB dalam fp16 atau 3 KB dalam fp32. Satu kolom tersebut bisa jauh lebih besar daripada seluruh baris TPC-H lineitem.
Dan 768 dimensi bukanlah hal yang tidak biasa atau besar menurut standar saat ini. Penyematan 1024 atau 2048 dimensi adalah hal yang umum dalam jaringan pipa multimodal. OpenAI's text-embedding-3-large mencapai 3072 dimensi, yaitu sekitar 12 KB per vektor dalam fp32.
Perbandingannya sangat mencolok:
| Bentuk dataset | Perkiraan ukuran baris | Apa yang mendominasi baris |
|---|---|---|
| Item baris TPC-H | ~150 byte tidak terkompresi | bidang skalar dan string pendek |
| Baris gaya LAION dengan vektor fp16 768-dim | ~1,5 KB+ | penyematan |
| Baris gaya LAION dengan vektor fp32 768-dim | ~3 KB+ | penyematan |
| Baris dengan vektor fp32 berukuran 3072-dim | ~12 KB+ untuk vektornya saja | penyematan |
Dalam banyak set data AI, kolom vektor bukan sekadar bidang. Secara fisik, kolom vektor adalah sebagian besar baris. Hal ini mengubah biaya evolusi skema.
Menambahkan satu kolom vektor dapat berarti ratusan gigabyte
Misalkan sebuah kumpulan data memiliki 100 juta klip video. Menambahkan kolom penyematan fp32 1024 dimensi baru berarti menulis sekitar 400 GB data vektor mentah. Itu belum termasuk statistik, indeks, pembaruan metadata, overhead penyimpanan objek, validasi, atau integrasi jalur penayangan.

Jika tim menambahkan satu atau dua kolom seperti vektor setiap bulan, seperti embedding_v2, sparse_vector, atau fitur peringkat ulang, evolusi skema menjadi pekerjaan rekayasa daAta berulang yang diukur dalam ratusan gigabyte atau terabyte.
Pembaruan logis yang kecil dapat memicu penulisan ulang fisik yang besar
Pembaruan juga sama pentingnya.
Dalam sistem kolumnar, data lama biasanya tidak diperbarui pada tempatnya. Log penghapusan mencatat apa yang berubah, dan pemadatan kemudian menulis ulang baris langsung ke dalam file baru. Model tersebut dapat dikelola ketika baris-barisnya kecil.
Dengan data vektor, pembaruan logis yang kecil dapat memicu penulisan ulang fisik yang besar.
Pekerjaan tinjauan manusia mungkin hanya mengoreksi beberapa ratus byte dalam teks. Tetapi jika keterangan, vektor padat, vektor jarang, dan fitur turunan lainnya memiliki siklus hidup file fisik yang sama, sistem mungkin akan menulis ulang vektor-vektor tersebut juga. Perubahan logisnya kecil. I / O fisik bisa sangat besar.
Ini adalah masalah amplifikasi tulis dalam penyimpanan vektor. Bagian yang mahal bukan hanya karena vektornya besar. Bidang turunan yang besar dan bidang kecil yang dapat diubah sering kali disatukan oleh tata letak penyimpanan yang memperlakukannya sebagai satu unit.
Untuk set data AI, pengisian ulang adalah beban kerja rutin
Untuk tabel analitik tradisional, evolusi skema mungkin hanya terjadi sesekali. Untuk dataset AI, ini adalah rutinitas. Model keterangan ditingkatkan. Model penyematan diganti. Vektor jarang ditambahkan kemudian. Fitur peringkat ulang muncul. Label manusia diperbaiki. Tag tata kelola diisi ulang. Indeks dibangun kembali.
Operasi-operasi ini bukanlah penambahan sederhana. Mereka sering memodifikasi atau memperluas baris yang ada.
Itulah sebabnya penyimpanan vektor tidak bisa hanya mengoptimalkan throughput pemindaian. Penyimpanan ini juga harus membuat pengisian ulang dan pembaruan parsial menjadi lebih murah.
Masalah kedua: data yang sama harus mendukung pemindaian dan pembacaan titik
Setelah data ditulis, jalur baca akan terpecah. Kumpulan data vektor yang sama biasanya memiliki dua pola akses yang berbeda: pemindaian analitik dan pembacaan titik.
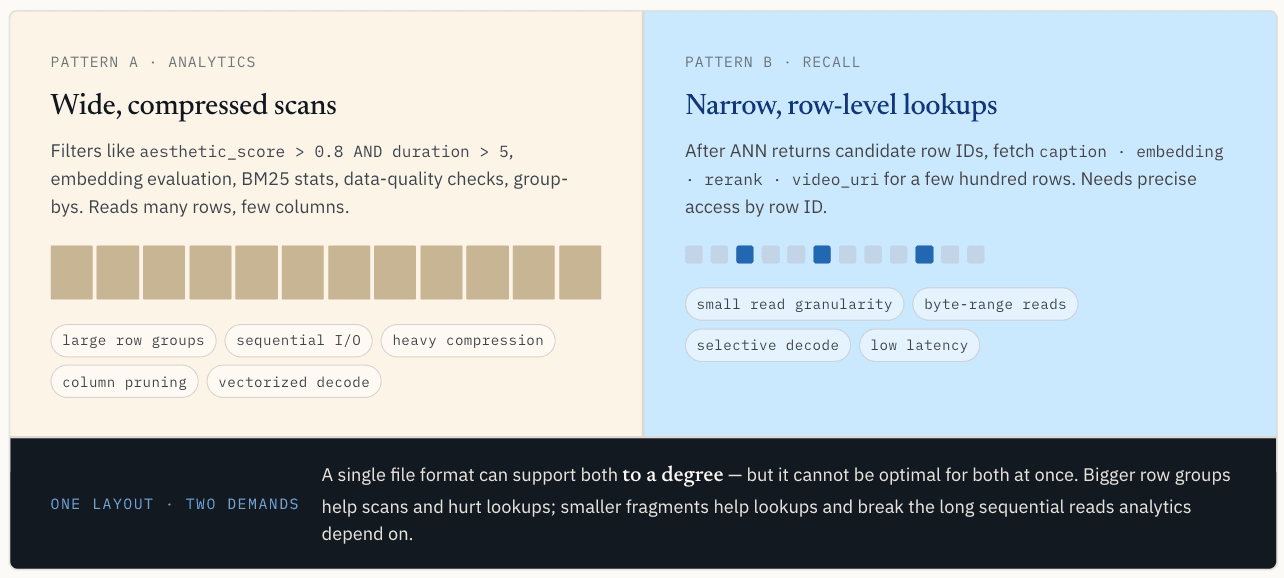
Beban kerja analitik menginginkan pemindaian yang lebar dan terkompresi
Pipeline dapat menjalankan filter seperti:
WHERE aesthetic_score > 0.8 AND duration > 5
Atau dapat menjalankan analisis offline, evaluasi penyematan penuh, statistik BM25, konstruksi bitmap, pemeriksaan kualitas data, jumlah, dan group-bys.
Pola ini membaca banyak baris tetapi hanya beberapa kolom. Pola ini menyukai I/O berurutan, grup baris yang lebih besar, kompresi, pemangkasan kolom, decoding batch, dan eksekusi vektor.
Grup baris yang besar membantu di sini. Mereka membiarkan satu permintaan I/O menarik sejumlah besar data yang berguna, meningkatkan efisiensi kompresi, dan menyediakan mesin eksekusi dengan data yang cukup berdekatan untuk mengamortisasi overhead. Ketika beberapa kolom dibaca bersama-sama, menjaga mereka tetap teratur untuk throughput pemindaian juga membantu mengurangi kesalahan cache selama eksekusi vektor.
Parket kuat dalam hal ini.
Hasil ANN membutuhkan pencarian tingkat baris yang sempit
Setelah pencarian ANN mengembalikan ID baris kandidat, sistem sering kali perlu mengambil bidang seperti:
caption
embedding
rerank feature
video_uri
metadata
Pola ini membaca lebih sedikit baris, sering kali ratusan atau ribuan, tetapi membutuhkan akses yang tepat berdasarkan ID baris. Sistem ingin menemukan baris dan kolom tertentu, mengambil hanya rentang byte yang diperlukan, dan menghindari menarik seluruh grup baris hanya untuk mengambil beberapa record.
Pencarian titik memiliki preferensi yang hampir berlawanan dengan pemindaian. Ia menginginkan perincian pembacaan yang lebih kecil. Idealnya, lapisan penyimpanan dapat menemukan segmen atau rentang byte yang relevan dengan ID baris, hanya membaca rentang tersebut, dan memecahkan kode hanya data yang diperlukan untuk hasilnya.
Kompresi juga memiliki tradeoff yang berbeda. Untuk pemindaian, kompresi yang lebih berat sering kali sepadan karena sistem membaca banyak data dan menghemat I/O. Untuk pencarian titik, kompresi dapat menjadi beban jika mengambil satu baris memerlukan penguraian blok terkompresi yang jauh lebih besar.
Satu tata letak tidak dapat mengoptimalkan untuk kedua jalur
Ini adalah konflik intinya. Pemfilteran skalar dan analitik menginginkan tata letak yang lebar, terkompresi, dan mudah dipindai. Pencarian vektor menginginkan tata letak yang sempit, tepat, dan dapat dialamatkan ke baris.
Satu format file dapat mendukung keduanya sampai tingkat tertentu, tetapi tidak dapat optimal untuk keduanya secara bersamaan.
Jika semua kolom berada di Parket, pemindaian skalar akan menjadi nyaman. Tetapi pencarian ANN setelah pemanggilan kembali menjadi lebih sulit. Sistem mungkin hanya membutuhkan beberapa ratus vektor, keterangan, atau catatan metadata, sementara lapisan penyimpanan mungkin harus membaca kelompok baris besar yang sebagian besar berisi baris yang tidak relevan.
Pada SSD lokal, cache dan mmap dapat menyembunyikan sebagian dari biaya ini. Setelah data disimpan dalam penyimpanan objek, biaya menjadi lebih terlihat. Setiap cache yang terlewat dapat menjadi pembacaan jarak jauh. Jika baris kandidat tersebar di banyak kelompok baris, satu kueri dapat memicu beberapa pembacaan, masing-masing menarik lebih banyak data daripada yang dibutuhkan kueri. Dalam tata letak yang kurang baik, mengambil 1.000 baris kandidat dapat dengan mudah menghasilkan puluhan atau ratusan megabyte I/O yang tidak perlu, dan dalam kasus yang ekstrim, lebih banyak lagi.
Membuat kelompok baris menjadi lebih kecil akan membantu pencarian titik, tetapi akan mengganggu pemindaian. Terlalu banyak fragmen kecil akan mengurangi efisiensi kompresi, meningkatkan overhead metadata, dan memecah pembacaan berurutan yang panjang yang diandalkan oleh mesin analitik.
Jadi, masalahnya bukan tentang menemukan satu ukuran kelompok baris ajaib. Masalahnya adalah dataset yang sama diminta untuk berperilaku seperti dua sistem penyimpanan yang berbeda.
Pencarian hibrida memaksa kedua jalur ke dalam satu kueri
Pencarian hibrida membuat konflik lebih sulit untuk diabaikan. Sebuah kueri tunggal dapat menerapkan filter skalar terlebih dahulu:
aesthetic_score > 0.8 AND duration > 5
Kemudian menjalankan pencarian ANN.
Kemudian mengambil keterangan, vektor, dan metadata berdasarkan ID baris.
Bagi pengguna, ini adalah satu permintaan pencarian. Bagi lapisan penyimpanan, ini adalah pemindaian analitis dan pencarian acak latensi rendah.
Itulah mengapa penyimpanan vektor membutuhkan lebih dari sekadar pengaturan Parket yang lebih baik. Diperlukan cara untuk menempatkan kolom yang berbeda sesuai dengan bagaimana mereka benar-benar dibaca.
Masalah ketiga: kumpulan data tidak berada di dalam satu mesin
Dua masalah pertama terjadi di dalam database. Masalah ketiga terjadi pada batas antar sistem.

Pipeline data AI menjangkau banyak sistem
Dalam alur kerja video, sangat sedikit yang terjadi di dalam basis data vektor itu sendiri.
Video mentah berada dalam penyimpanan objek. Pembuatan klip dapat berjalan di Spark atau Ray. Penilaian estetika dapat berjalan dalam layanan GPU. Captioning dapat berjalan dalam pipa inferensi LLM. Penyematan dapat dihasilkan oleh pekerjaan GPU lain. Vektor yang jarang dapat berasal dari layanan SPLADE. Evaluasi offline, pemfilteran data pelatihan, tinjauan manusia, dan pekerjaan tata kelola dapat berjalan di tempat lain.
Basis data vektor melayani pencarian online, tetapi kumpulan data diproduksi, dikoreksi, dievaluasi, dan diperluas oleh banyak sistem.
Format penyimpanan pribadi membuat banyak salinan kebenaran
Jika basis data menggunakan format fisik privat yang hanya dapat dibaca dan ditulis olehnya, setiap pekerjaan eksternal membutuhkan ekspor, konversi, salinan, dan impor. Koleksi yang sama mungkin ada di database, di direktori sementara Spark, di output evaluasi, dan di direktori isi ulang lokal. Kemudian pertanyaan yang sebenarnya menjadi:
- Salinan mana yang merupakan sumber kebenaran?
- Yang mana yang berisi model keterangan dari bulan lalu?
- Baris mana yang telah dikoreksi oleh peninjauan manusia?
- Kolom vektor jarang mana yang dihasilkan oleh model yang mana?
- Indeks vektor mana yang masih valid setelah pengisian ulang?
- Objek video asli mana yang dirujuk oleh baris ini?
Dalam skala kecil, tim terkadang dapat bertahan dengan konvensi penamaan dan pemeriksaan manual. Dengan ratusan juta baris dan terabyte penyematan, hal ini menjadi masalah konsistensi.
Kumpulan data vektor membutuhkan status versi bersama
Sistem Lakehouse mengatasi masalah ini untuk data terstruktur. Iceberg, Delta Lake, dan Hudi bukan hanya tentang menyimpan file. Kontribusi utama mereka adalah memungkinkan beberapa mesin berkoordinasi di sekitar status tabel yang sama.
Basis data vektor sekarang membutuhkan kemampuan yang sama, tetapi keadaannya lebih kompleks. Ini harus mencakup tidak hanya file tabel dan partisi, tetapi juga indeks vektor, indeks teks, fitur yang jarang, menghapus log, statistik, rentang ID baris, dan referensi ke gumpalan eksternal.
Pertanyaannya bukan sekadar, "Bisakah Spark membaca file Milvus?"
Pertanyaannya adalah, setelah Spark mengisi ulang kolom vektor yang jarang, bagaimana Milvus mengetahui versi mana yang dimiliki kolom tersebut, baris mana yang dicakupnya, model mana yang membuatnya, dan kapan kueri online dapat menggunakannya dengan aman?
Jawabannya ada pada model penyimpanan.
Mengapa tambalan saja tidak cukup
Sangat menggoda untuk memperlakukan ini sebagai tiga masalah teknik yang terpisah.
- Menulis amplifikasi? Tambahkan batching.
- Titik baca? Tambahkan cache.
- Sistem eksternal? Tambahkan alat ekspor dan impor.
Patch-patch tersebut dapat membantu, tetapi tidak mengatasi masalah yang mendasarinya: kumpulan data vektor secara fisik heterogen.

Dalam contoh video, clip_id, video_id, duration, dan aesthetic_score adalah bidang skalar pendek. Bidang-bidang ini berguna untuk penyaringan dan analisis.
captionadalah teks. Ini dapat digunakan untuk BM25, tinjauan, koreksi, dan pengisian ulang.embeddingadalah vektor yang panjang dan padat. Ini digunakan untuk pemanggilan kembali ANN dan kemudian untuk pencarian atau pemeringkatan ulang tingkat baris.embedding_v2adalah keluaran model baru, sering kali diisi ulang lama setelah data asli dimasukkan.sparse_vectormendukung pencarian hibrida dan memiliki pola aksesnya sendiri.- Video mentah harus tetap berada di penyimpanan objek. Basis data harus menyimpan referensi, checksum, tipe MIME, versi parser, dan hubungan tingkat baris.
- Indeks vektor, indeks teks, statistik, dan log hapus adalah objek turunan dengan semantik versinya sendiri.
Objek-objek ini berbagi baris logis, tetapi mereka tidak boleh memiliki tata letak fisik atau siklus hidup yang sama.
- Jika mereka dipaksa menjadi satu tata letak tabel biasa, pembaruan akan menjadi mahal.
- Jika dipaksakan menjadi satu format file kolom, pembacaan titik menjadi mahal.
- Jika mereka diperlakukan sebagai file objek yang tidak terkait, manajemen versi menjadi rapuh.
Jadi model penyimpanan harus dimulai dari fakta bahwa kumpulan data bersifat heterogen.
Hal ini mengarah pada tiga persyaratan desain:
- Pertama, kelompok kolom yang berbeda harus disimpan dalam format fisik yang berbeda.
- Kedua, kelompok-kelompok kolom tersebut membutuhkan ruang ID baris bersama, sehingga mereka masih dapat berperilaku sebagai satu tabel logis.
- Ketiga, kumpulan data membutuhkan Manifest berversi yang menyatakan file, indeks, log, statistik, dan referensi objek mana yang termasuk dalam tampilan saat ini.
Ini adalah desain di balik Loon, mesin penyimpanan baru kami di balik Milvus dan Zilliz Cloud.
Loon: mesin penyimpanan di balik Milvus dan Zilliz Cloud untuk kumpulan data vektor yang terus berkembang
Untuk mengatasi semua masalah di atas, kami membangun Loon, mesin penyimpanan baru untuk Milvus dan Zilliz Vector Lakebase (evolusi berikutnya dari Zilliz Cloud), yang dirancang untuk kumpulan data vektor yang terus berkembang.
Nama ini mengikuti tradisi penamaan burung Zilliz. Loon adalah burung penyelam yang hidup di danau, yang memetakan dengan baik tujuan sistem: basis data vektor seharusnya tidak perlu memindahkan, memindai, atau menulis ulang seluruh danau data setiap kali menjalankan kueri, mengisi ulang kolom, atau membangun indeks. Pertama-tama, database harus memahami versi kumpulan data saat ini, termasuk kolom, indeks, statistik, menghapus log, dan referensi objek, kemudian hanya membaca bagian yang benar-benar dibutuhkan.
Format file hibrida, perataan ID baris, dan Manifest bukanlah tiga fitur yang terpisah. Mereka berasal dari asumsi desain yang sama: kumpulan data vektor pada dasarnya heterogen.
Tiga bagian, satu model penyimpanan
Format file hibrida mengakui bahwa kolom yang berbeda memiliki pola akses yang berbeda. Bidang skalar bagus untuk pemindaian dan filter. Bidang vektor membutuhkan pencarian tingkat baris yang efisien. Objek mentah seperti video, PDF, gambar, dan file audio termasuk dalam penyimpanan objek, bukan di dalam file data basis data.
Penjajaran ID baris mengakui bahwa kolom-kolom ini mungkin terpisah secara fisik, namun tetap menggambarkan baris logis yang sama. Caption, embedding, vektor jarang, dan URI video mungkin berada dalam file dan format yang berbeda, tetapi mereka masih harus disatukan sebagai satu hasil.
Manifes mengakui bahwa dataset tidak ditulis sekali dan ditinggalkan begitu saja. Dataset ini akan dimodifikasi oleh banyak sistem, di berbagai versi, untuk berbagai tugas. Indeks, statistik, log hapus, referensi objek eksternal, dan grup kolom harus muncul dalam tampilan versi yang sama.
Inilah sebabnya mengapa Loon bukan sekadar format file vektor yang lebih cepat. Format yang lebih cepat membantu pencarian titik, tetapi tidak menyelesaikan evolusi skema atau koordinasi multi-mesin. Penjajaran ID baris memungkinkan kolom yang terpisah berperilaku sebagai tabel tunggal, tetapi tidak menentukan file mana yang termasuk dalam versi saat ini. Manifes dapat mendeskripsikan status kumpulan data, tetapi tanpa kelompok kolom dan penyelarasan ID baris, Manifes tidak dapat dengan jelas merepresentasikan tata letak fisik yang berbeda di dalam satu koleksi logis.
Model penyimpanan membutuhkan ketiganya: format yang berbeda untuk kelompok kolom yang berbeda, ruang ID baris bersama untuk merekonstruksi baris, dan Manifes berversi yang memberi tahu setiap pembaca dan penulis tentang dataset saat ini.
Di mana Loon cocok dengan Milvus dan Zilliz Vector Lakebase
Di Milvus, ia menggantikan lapisan penyimpanan binlog segmen lama dengan model yang dibangun di sekitar Manifest, ColumnGroup, format file, dan abstraksi sistem berkas. Di Zilliz Vector Lakebase (evolusi berikutnya dari Zilliz Cloud), arah yang sama berlaku untuk arsitektur Vector Lakebase: menjaga jalur penyajian basis data vektor tetap cepat sambil membuat data yang mendasarinya lebih mudah untuk dikembangkan, dianalisis, dan dikoordinasikan dengan sistem eksternal.
Komponen Milvus tingkat atas masih mempertahankan peran mereka yang sudah dikenal. Proxy menangani perutean. QueryCoord dan DataCoord menangani penjadwalan. IndexNode membangun indeks. API yang berhadapan dengan aplikasi untuk koleksi, sisipan, pencarian, dan pencarian hibrida tidak perlu mengekspos file Manifes atau ColumnGroup.
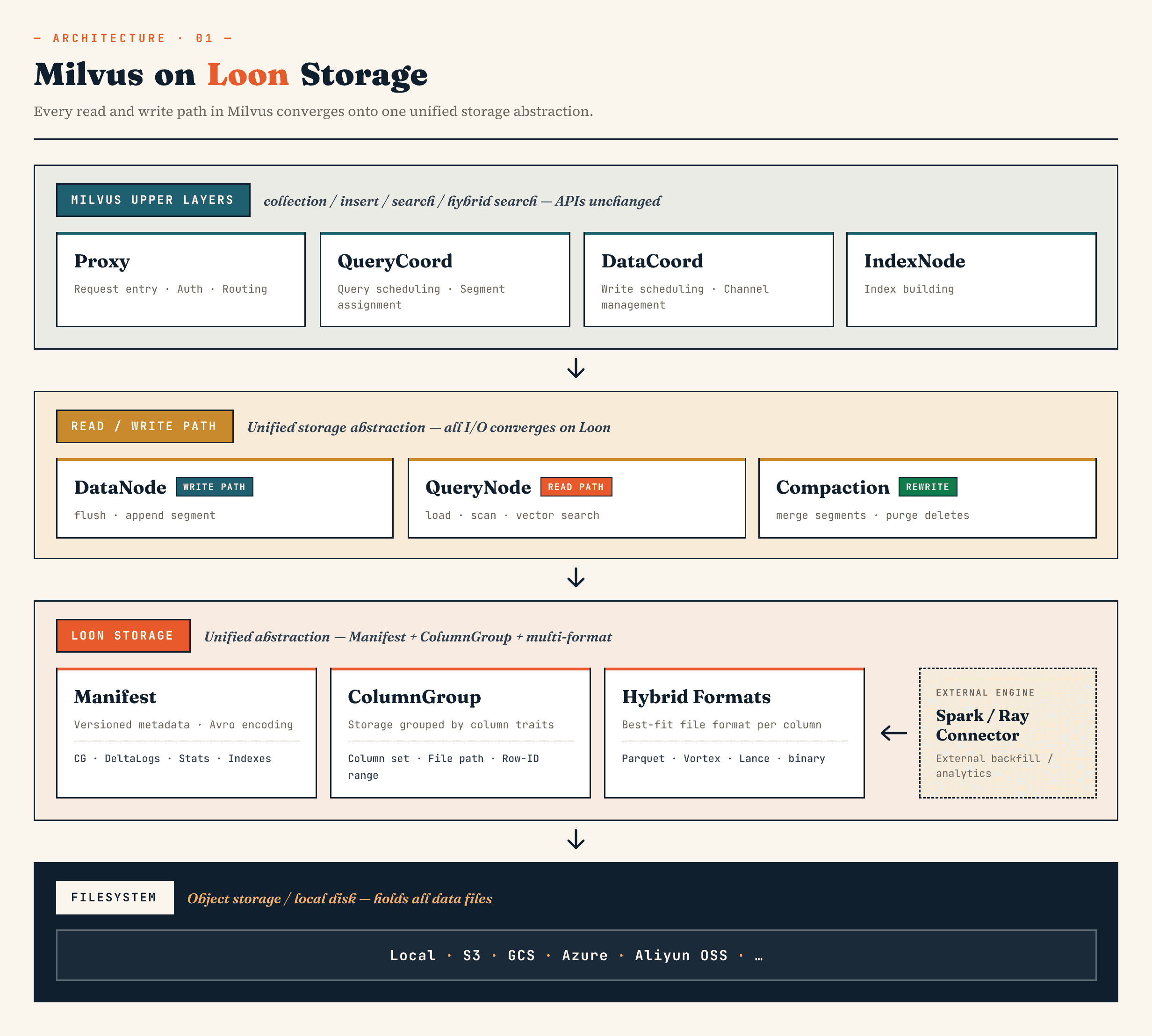
Perubahannya ada di bawahnya.
DataNode, QueryNode, segcore, pemadatan, dan konektor eksternal dapat beroperasi melalui abstraksi penyimpanan yang sama. Hal ini penting karena kumpulan data tidak lagi ditulis dan hanya dibaca oleh database. Dataset ini dapat diperluas oleh sistem komputasi eksternal dan dikonsumsi oleh pencarian online secara bersamaan.
Pada tingkat tinggi, lapisan-lapisannya terlihat seperti ini:
Manifest
→ ColumnGroup
→ file format layer
→ filesystem abstraction
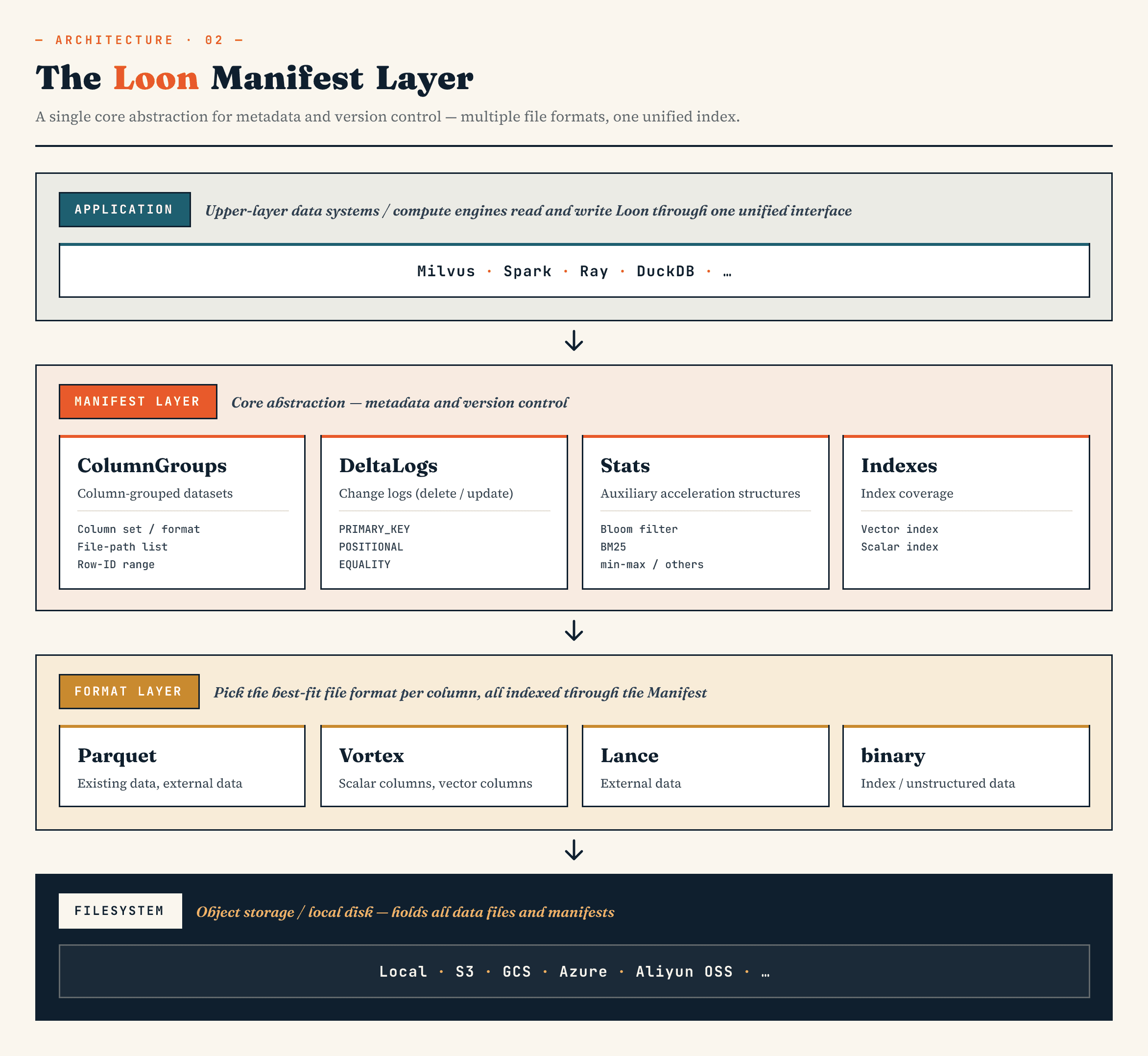
Manifes menggambarkan status versi dari kumpulan data. ColumnGroups memetakan koleksi logis ke dalam kelompok-kelompok kolom secara fisik. Lapisan format file memungkinkan setiap ColumnGroup memilih format yang sesuai. Abstraksi sistem berkas bekerja di seluruh penyimpanan objek dan penyimpanan lokal.
Poin pentingnya adalah bahwa format file hibrida, penyelarasan ID baris, dan Manifes bukanlah fitur yang terpisah. Bersama-sama, ketiganya mendefinisikan model penyimpanan.
Dengan adanya model tersebut, kita dapat melihat tiga pilihan desain satu per satu: bagaimana Loon menyimpan ColumnGroup yang berbeda, bagaimana Loon menyelaraskannya kembali ke dalam baris, dan bagaimana Manifest mengubah berkas-berkas tersebut menjadi kumpulan data berversi.
Desain 1: gunakan format file yang tepat untuk grup kolom yang tepat
Kolom yang berbeda memiliki pola akses yang berbeda. Mereka tidak boleh dipaksakan ke dalam format file yang sama.
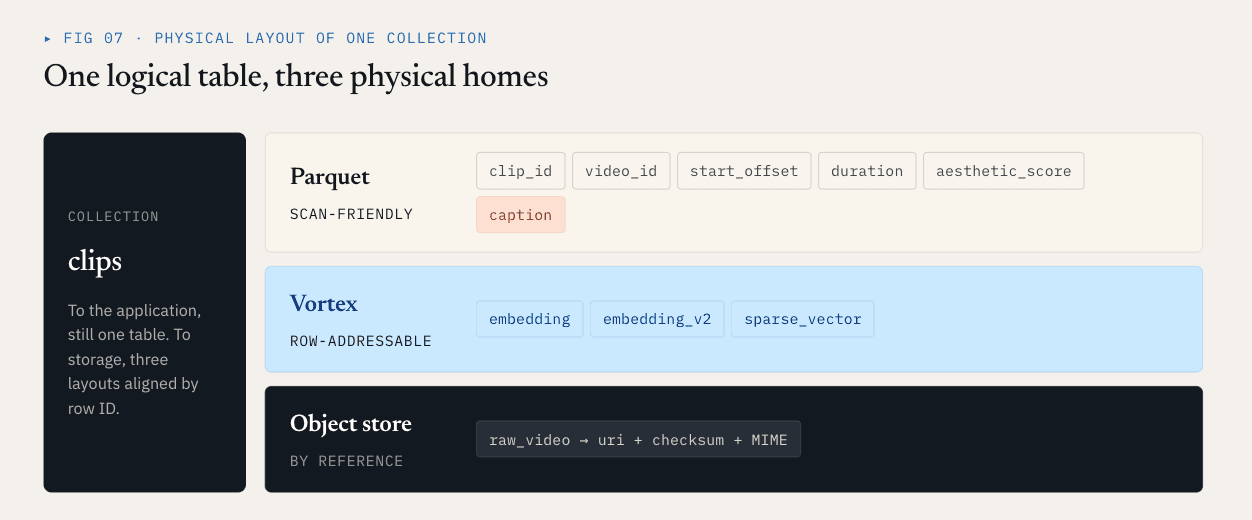
Loon memisahkan koleksi logis ke dalam ColumnGroups.
- Kolom skalar, kolom filter, kunci bisnis, dan kolom statistik sering kali dipindai, difilter, digabungkan, atau digunakan untuk perencanaan kueri. Mereka mendapat manfaat dari kompresi, pemangkasan kolom, dan kompatibilitas ekosistem. Parket sangat cocok untuk kolom-kolom ini.
- Vektor padat, vektor jarang, dan fitur peringkat ulang sering kali dibaca setelah pemanggilan ANN berdasarkan ID baris. Mereka membutuhkan akses acak latensi rendah, pembacaan rentang byte yang tepat, dan decoding selektif. Tata letak yang berorientasi pada segmen lebih cocok. Loon menggunakan Vortex ke arah ini.
- Objek mentah seperti video, PDF, gambar, dan file audio tidak boleh disematkan ke dalam file data basis data vektor. File-file tersebut harus tetap berada dalam penyimpanan objek. Basis data mencatat referensi, checksum, jenis MIME, versi parser, dan hubungan tingkat baris.
Untuk contoh video, tata letak fisik mungkin terlihat seperti ini:
Parquet ColumnGroup:
clip_id / video_id / start_offset / duration / aesthetic_score / caption
Vortex ColumnGroups:
embedding
embedding_v2
sparse_vector
Object storage:
raw video objects
Untuk aplikasi, ini masih merupakan satu koleksi. Untuk lapisan penyimpanan, bagian yang berbeda dari koleksi itu menggunakan format fisik yang berbeda. Hal ini secara langsung mengurangi penulisan ulang yang tidak perlu. Menambahkan embedding_v2 dapat menjadi vektor baru ColumnGroup ditambah dengan sebuah Manifes commit. Hal ini tidak memerlukan penulisan ulang kolom keterangan, metadata skalar, atau kolom penyematan yang sudah ada.
Ide yang sama berlaku untuk vektor jarang, fitur peringkat ulang, atau kolom turunan lainnya. Jika kolom baru dapat berdiri sendiri secara fisik dan disejajarkan dengan ID baris, maka kolom tersebut tidak perlu menyeret kolom yang tidak terkait melalui jalur penulisan ulang yang sama.
Loon juga mengadaptasi penggunaan format file.
Untuk Parket, pengaturan default tidak selalu ideal untuk data vektor yang berat. Grup baris 64 MB bisa jadi terlalu besar untuk pencarian titik karena pembacaan acak yang kecil dapat menarik lebih banyak data daripada yang dibutuhkan. Loon memperketat kelompok baris menjadi 1 MB pada jalur yang relevan dan menonaktifkan penyandian, seperti penyandian kamus pada kolom vektor, bila tidak membantu data vektor yang terlihat acak.
Untuk Vortex, pekerjaan yang lebih penting adalah tata letak. Loon menggunakan tata letak yang menyeimbangkan efisiensi pemindaian dan pencarian titik. Dalam kelompok baris, segmen dari kolom terkait dapat ditempatkan berdekatan untuk mendukung pemindaian. Untuk melakukan operasi, pembacaan sub-segmen memungkinkan sistem untuk mengambil hanya byte yang relevan daripada menarik seluruh segmen.
Loon juga mendukung integrasi Lance yang hanya dapat dibaca, sehingga kumpulan data Lance yang ada dapat dipasang sebagai ColumnGroup ketika kompatibilitas menjadi hal yang penting.
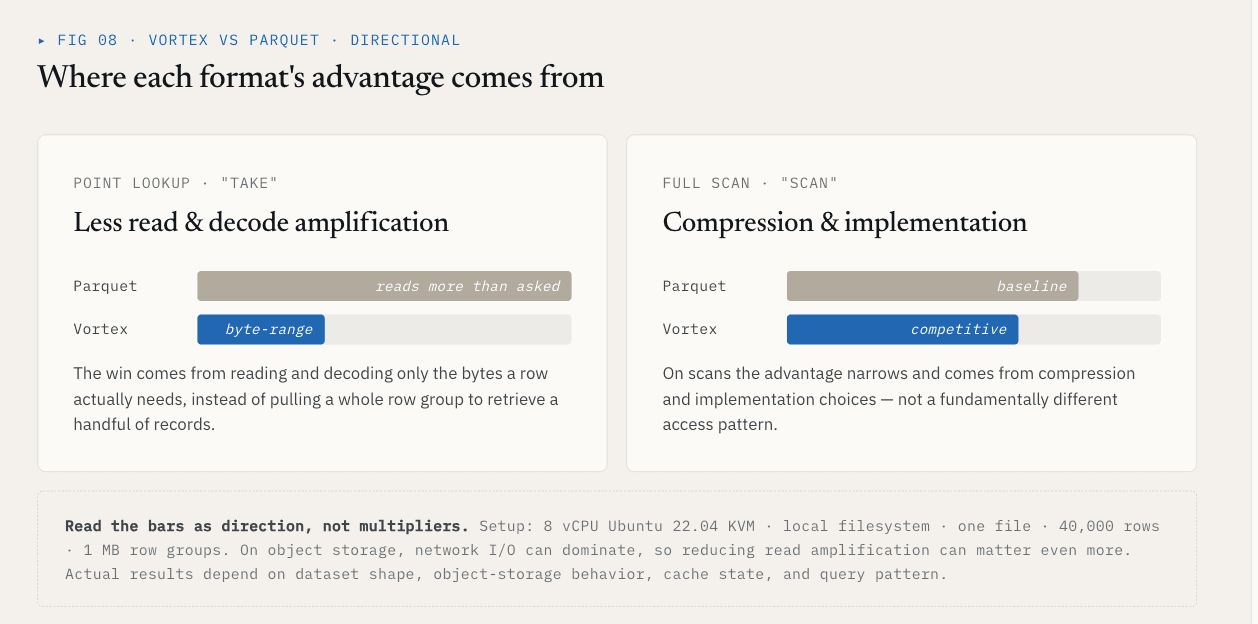
Apa yang ditunjukkan oleh benchmark
Dalam satu pengujian lokal, menggunakan satu file dengan 40.000 baris dan skema {id: int64, name: utf8, value: float64, vector: list<float32>[128]}, Vortex menunjukkan hasil ini terhadap Parquet dengan kelompok baris 1 MB:
| Operasi | Vortex | Parket | Perbedaan |
|---|---|---|---|
| Ambil, K = 1000 baris acak | 5,8 ms | 144 ms | 25x lebih cepat |
| Pemindaian kolom vektor penuh | 21 ms | 142 ms | 6,76x lebih cepat |
| Ukuran file, ~21 MB data mentah | 6,62 MB | 7,16 MB | 7% lebih kecil |
Hasil take berasal dari pengurangan jumlah data yang tidak relevan yang harus dibaca dan diterjemahkan. Hasil pemindaian berasal dari kompresi dan pilihan implementasi.
Angka-angka ini harus tetap melekat pada pengaturannya: 8 vCPU Ubuntu 22.04 KVM, sistem berkas lokal, satu berkas, 40.000 baris, kelompok baris 1 MB, dan skema di atas. Pada penyimpanan objek, I/O jaringan dapat mendominasi, sehingga mengurangi amplifikasi pembacaan dapat menjadi lebih penting. Hasil yang sebenarnya tergantung pada bentuk dataset, perilaku penyimpanan objek, status cache, dan pola kueri.
Poin yang lebih luas bukanlah bahwa setiap kolom harus menggunakan Vortex.
Intinya adalah bahwa kumpulan data vektor memerlukan pilihan format file di tingkat ColumnGroup.
Desain 2: menyelaraskan file fisik melalui ID baris
Format file hibrida menyelesaikan satu masalah: kolom yang berbeda sekarang dapat hidup dalam format yang paling sesuai dengan mereka.
Namun, hal ini menimbulkan masalah kedua. Jika bidang skalar berada di Parquet, vektor berada di Vortex, dan objek mentah berada di penyimpanan objek, bagaimana sistem masih memperlakukannya sebagai satu koleksi?
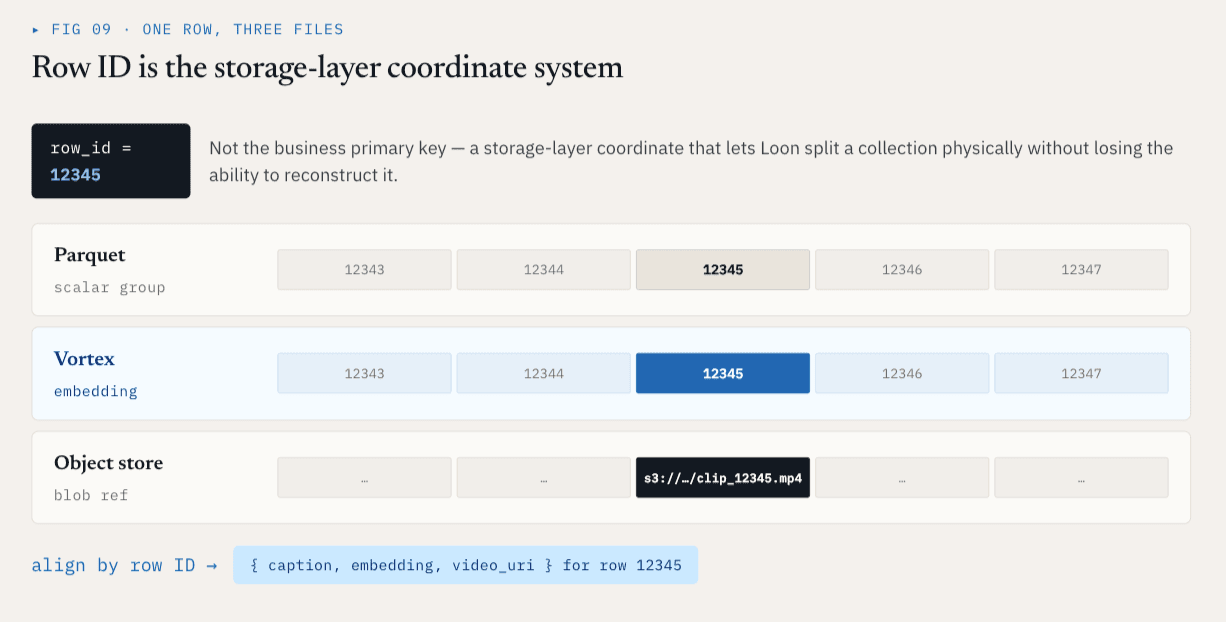
Loon memecahkan masalah ini dengan penyelarasan ID baris.
ID Baris adalah sistem koordinat lapisan penyimpanan
Setiap ColumnGroupFile fisik mencatat jalur file dan rentang ID baris yang dicakupnya:
path
start_index
end_index
ColumnGroup yang berbeda dapat mencakup ruang ID baris yang sama meskipun berada dalam file dan format yang berbeda.
Untuk ID baris 12345, metadata skalar mungkin berada di dalam ColumnGroup Parket, penyematan mungkin di dalam ColumnGroup Vortex, dan video mentah mungkin diwakili oleh referensi penyimpanan objek. Secara logika, mereka masih satu baris. Hal ini memberikan lapisan penyimpanan sistem koordinat yang stabil.
ID Baris bukanlah kunci utama bisnis. Ini adalah sistem koordinat lapisan penyimpanan yang memungkinkan Loon membagi koleksi secara fisik tanpa kehilangan kemampuan untuk merekonstruksi secara logis.
Kolom baru tidak harus menulis ulang kolom lama
Menambahkan embedding_v2 tidak perlu menulis ulang keterangan asli, metadata, atau embedding_v1 ColumnGroups. Loon dapat menulis vektor baru ColumnGroup, mencatat rentang ID baris yang dicakupnya, dan mengomit perubahan tersebut melalui Manifes.
Hal yang sama berlaku untuk vektor yang jarang, fitur peringkat ulang, atau bidang turunan lainnya yang datang kemudian.
Selama ColumnGroup baru mencakup rentang ID baris yang tepat, ia dapat bergabung dengan koleksi logis yang sama tanpa memaksa data yang tidak terkait untuk dipindahkan.
Penghapusan dan pemadatan bisa lebih tepat sasaran
Penyelarasan ID baris juga membantu dengan penghapusan.
Penghapusan pertama-tama dapat dinyatakan melalui log penghapusan. Baris menjadi tidak terlihat pada tingkat logis, sementara pembersihan fisik ditunda sampai pemadatan. Ketika pemadatan akhirnya berjalan, ia tidak selalu perlu menulis ulang setiap ColumnGroup yang terkait dengan baris yang terpengaruh. Ia dapat fokus pada ColumnGroup yang perlu dibersihkan.
Hal ini penting karena tidak semua kolom memiliki profil biaya yang sama. Menulis ulang sebuah ColumnGroup skalar pendek sangat berbeda dengan menulis ulang ratusan gigabyte vektor padat.
Pencarian hibrida hanya dapat mengambil kolom yang dibutuhkannya
Penyelarasan ID baris juga yang membuat pencarian hibrida menjadi praktis di atas format file hibrida.
Setelah pencarian ANN mengembalikan ID baris kandidat, sistem hanya dapat mengambil kolom yang diperlukan untuk hasil akhir: keterangan, metadata, vektor, fitur peringkat, atau referensi objek.
Sebagai contoh, sebuah kueri mungkin membutuhkan:
caption
embedding
video_uri
Bidang-bidang tersebut mungkin berada di dalam ColumnGroup yang berbeda. Loon dapat menemukan file yang relevan berdasarkan rentang ID baris, membaca rentang byte yang diperlukan, dan mengumpulkan hasilnya.
Tanpa penyelarasan ID baris, format hibrida hanya akan menjadi file terpisah yang duduk berdampingan. Dengan penyelarasan ID baris, mereka berperilaku sebagai koleksi logis tunggal.
Packed Reader menyembunyikan pemisahan dari lapisan atas
Komponen runtime yang membuat ini dapat digunakan adalah Packed Reader.
Lapisan atas melihat aliran Arrow RecordBatch terpadu. Di bawahnya, data mungkin berasal dari beberapa ColumnGroup dalam format file yang berbeda. Packed Reader menyembunyikan perbedaan-perbedaan tersebut, menyelaraskan data berdasarkan rentang ID baris, dan menjadwalkan I / O multi-file dengan penggunaan memori yang terkontrol.
Ini juga mendukung take langsung dengan ID baris. Diberikan satu set ID baris, ia menemukan ColumnGroupFiles yang relevan, mengeluarkan pembacaan rentang, dan mengembalikan bidang yang diminta.
Untuk alur kerja video, kueri ANN mungkin memerlukan caption, embedding, dan video_uri. Pembaca yang Dikemas dapat mengambil ColumnGroup skalar dan ColumnGroup vektor tanpa menyentuh kolom yang tidak terkait.
Itulah perbedaan antara "file terpisah" dan "tabel dengan beberapa tata letak fisik."
Desain 3: Jadikan Manifes sebagai sumber kebenaran
Format file hibrida menentukan bagaimana data disimpan secara fisik. Penjajaran ID baris menentukan bagaimana KolomKolom yang terpisah masih membentuk satu tabel logis. Tetapi sistem masih perlu menjawab pertanyaan yang lebih besar: file, log, statistik, indeks, dan referensi objek mana yang termasuk dalam versi dataset saat ini? Itu adalah tugas Manifes.

Direktori penyimpanan objek tidak cukup
Penyimpanan objek bukanlah katalog basis data. Sebuah direktori dapat berisi file lama, file baru, output pekerjaan yang gagal, file sementara, log hapus, file yang masih direferensikan oleh snapshot yang lebih lama, dan file yang menunggu pembersihan. Fakta bahwa sebuah file ada bukan berarti file tersebut termasuk dalam versi kumpulan data saat ini.
Dataset Loon dapat diatur ke dalam direktori seperti:
_metadata/
_data/
_delta/
_stats/
_index/
Tetapi struktur direktori bukanlah sumber kebenaran. Manifes adalah sumber kebenaran. Pembaca tidak boleh membuat daftar direktori dan menyimpulkan status dari file apa pun yang ada. Mereka harus membaca Manifes saat ini dan mengikuti tampilan berversi yang dideklarasikannya.
Manifes mendefinisikan satu tampilan versi dari dataset
Manifes mendefinisikan dataset dalam versi tertentu. Ia mencatat
- ColumnGroup mana yang ada
- rentang ID baris mana yang dicakupnya
- format fisik apa yang digunakan oleh setiap ColumnGroup
- di mana berkas-berkas itu berada
- log penghapusan mana yang aktif
- statistik mana yang tersedia
- indeks mana yang ada
- gumpalan eksternal mana yang direferensikan
- kolom dan rentang baris mana yang dicakup oleh statistik atau indeks tersebut
Setiap pembaruan menulis versi Manifes yang baru. Pembaca yang membuka versi N akan melihat tampilan dataset yang stabil pada versi N. Penulis dapat menyiapkan versi N+1 tanpa mengganggu pembaca yang masih menggunakan versi N.
Manifes melacak lebih dari sekadar file tabel
Di Loon, badan Manifest dikodekan dengan Apache Avro dan diorganisasikan di sekitar empat bagian utama.
- ColumnGroups mendeskripsikan kolom, format, file, dan rentang ID baris.
- DeltaLogs mendeskripsikan penghapusan. Jenis penghapusan yang berbeda mencakup sumber perubahan yang berbeda, seperti penghapusan kunci utama dari klien, penghapusan posisi dari pemadatan internal, atau penghapusan kesetaraan dari mesin eksternal.
- Statistik mencakup metadata perencanaan seperti filter bloom, statistik BM25, dan nilai min/max.
- Indeks menjelaskan jenis indeks, parameter, kolom yang tercakup, dan rentang ID baris. Ini dapat mencakup indeks vektor seperti HNSW atau IVF, indeks teks, indeks terbalik, indeks bitmap, dan struktur terkait.
Di sinilah Loon berbeda dari manifes tabel tradisional.
Dataset vektor tidak hanya perlu melacak file data dan partisi. Dataset ini juga perlu melacak indeks vektor, indeks teks, fitur yang jarang, log yang dihapus, statistik, referensi objek eksternal, dan rentang ID baris yang menghubungkannya.
Manifes harus dapat ditulis oleh lebih dari database
Bagian yang paling penting bukan hanya apa isi Manifest. Melainkan siapa yang dapat menulisnya.
- Jika hanya database yang dapat menulis Manifes, maka itu tetap merupakan metadata internal. Metadata yang lebih bersih, tetapi masih bersifat pribadi untuk satu mesin.
- Jika mesin eksternal dapat menghasilkan ColumnGroups, statistik, dan entri Manifes baru, Manifes menjadi antarmuka koordinasi.
- Sebuah pekerjaan Spark, misalnya, dapat mengisi ulang kolom vektor yang jarang. Ini menulis ColumnGroup baru, mencatat cakupan baris dan statistik, dan membuat Manifest baru. Kueri online dapat terus membaca versi lama selama pekerjaan berlangsung. Setelah komit berhasil, versi baru akan terlihat.
Hal ini mirip dengan semangat Iceberg dan Delta Lake, tetapi model objeknya lebih luas. Dataset vektor perlu melacak indeks vektor, indeks teks, fitur yang jarang, menghapus log, statistik, referensi gumpalan, dan rentang ID baris, bukan hanya file tabel dan partisi.
Komitmen yang optimis menjaga pembaruan versi tetap sederhana
Setiap komit menulis versi Manifes yang baru. Seorang penulis dapat membuat konten baru berdasarkan versi N, lalu mencoba menulis manifest-{N+1}.avro. Penyimpanan objek penulisan bersyarat atau semantik pencocokan-generasi dapat membuat komit gagal jika versi tersebut sudah ada. Penulis kemudian dapat mencoba kembali dengan versi yang lebih baru.
Hal ini memberikan konkurensi yang optimis kepada Loon tanpa memaksa setiap pembaruan melalui jalur koordinasi yang berat dan sangat konsisten. Tanpa Manifest, penyimpanan multi-format dan multi-engine pada akhirnya berubah menjadi konvensi penamaan dan rekonsiliasi manual. Hal ini dapat bekerja untuk kumpulan data yang kecil. Hal ini tidak bekerja untuk data vektor skala TB.
Manifes inilah yang mengubah file heterogen menjadi kumpulan data yang dapat dibaca dan diperbarui dengan aman oleh banyak sistem.
Apa yang berubah bagi pengguna ketika penyimpanan menjadi berversi
Untuk pengembang aplikasi, Loon seharusnya tidak menjadi beban API baru.
Pengguna harus tetap bekerja dengan konsep Milvus yang sudah dikenal: koleksi, sisipan, pencarian, dan pencarian hybrid. Mereka seharusnya tidak perlu memikirkan file Manifest, ColumnGroups, rentang ID baris, atau tata letak file selama pengembangan aplikasi normal.
Perubahannya ada di bawahnya. Penyimpanan menjadi lebih sadar akan bagaimana kumpulan data AI benar-benar berkembang.
Menambahkan penyematan baru seharusnya tidak memindahkan data lama
Sebelumnya, menambahkan embedding_v2 ke koleksi yang sudah ada sering kali membutuhkan pengeksporan data, melatih model baru, menghasilkan vektor, dan kemudian mengimpor ulang atau memperbarui koleksi secara massal melalui SDK. Jalur tersebut menciptakan banyak pekerjaan operasional: pelacakan versi, percobaan ulang pekerjaan yang gagal, pembangunan kembali indeks, dampak penyajian, dan pemeriksaan konsistensi.
Dengan Loon, hal ini dapat menjadi evolusi skema ditambah dengan komit ColumnGroup yang baru. Kolom penyematan yang baru dapat ditulis sebagai ColumnGroup fisiknya sendiri, disejajarkan dengan ID baris, dan dapat dilihat melalui Manifes. Kolom keterangan lama, kolom metadata skalar, dan kolom penyematan asli tidak perlu dipindahkan.
Pengisian ulang seharusnya tidak memerlukan perulangan pembaruan sisi klien
Banyak pembaruan data AI adalah pengisian ulang. Sebuah tim dapat menambahkan vektor yang jarang setelah pencarian hibrida menjadi penting. Tim dapat menambahkan fitur peringkat ulang setelah model baru dilatih. Dapat mengoreksi keterangan setelah ditinjau oleh manusia. Dapat menambahkan tag tata kelola setelah pembaruan kebijakan.
Dalam tata letak tradisional, perubahan ini sering terjadi melalui pembaruan SDK klien atau jalur penulisan khusus basis data, bahkan ketika data dihasilkan oleh Spark, Ray, atau mesin eksternal lainnya.
Dengan Loon, sistem komputasi eksternal dapat menghasilkan ColumnGroups baru dan mengomitnya melalui Manifest. Basis data tidak lagi harus menjadi satu-satunya titik masuk untuk setiap penulisan ulang.
Analisis offline seharusnya tidak memerlukan salinan lain dari kebenaran
Sebelumnya, tim sering kali membuang koleksi online ke dalam Parquet untuk evaluasi atau analisis offline. Hal ini menciptakan dua versi dari kumpulan data yang sama: koleksi online dan salinan analisis. Setelah keterangan dikoreksi, penyematan dibuat ulang, log hapus diterapkan, atau indeks dibangun kembali, tim harus menanyakan salinan mana yang terkini.
Dengan model penyimpanan berbasis Manifes, mesin analisis dapat membaca tampilan set data berversi yang sama dengan sistem penyajian. Mesin analisis dapat memproyeksikan hanya kolom yang mereka butuhkan, memindai hanya rentang baris yang relevan, dan bekerja berdasarkan versi dataset yang dideklarasikan, bukan snapshot yang diekspor secara manual.
Penghapusan dan koreksi hanya menyentuh apa yang berubah
Penghapusan, koreksi keterangan, perbaikan label, dan pembaruan tata kelola merupakan hal yang rutin dilakukan dalam set data AI. Mereka tidak boleh memaksa setiap kolom vektor yang panjang melalui jalur penulisan ulang yang sama.
Dengan Loon, menghapus log pertama-tama dapat diperlakukan sebagai penghapusan logis. Pemadatan selanjutnya dapat membersihkan ColumnGroup yang terpengaruh tanpa menulis ulang data yang tidak terkait. Jika bidang teks pendek berubah, lapisan penyimpanan tidak perlu menulis ulang ratusan gigabyte vektor padat hanya karena mereka berbagi baris logis yang sama.
Mesin eksternal menjadi bagian dari alur kerja, bukan tempat pelarian
Pergeseran yang lebih besar adalah bahwa mesin eksternal tidak lagi diperlakukan sebagai sistem di luar basis data vektor.
Spark, Ray, pekerjaan evaluasi, sistem pelabelan, dan pipeline tata kelola sudah menghasilkan dan memodifikasi sebagian besar data. Lapisan penyimpanan harus memungkinkan mereka untuk berkolaborasi di sekitar satu sumber kebenaran daripada terus-menerus mengekspor, menyalin, dan mengimpor ulang.
Itulah yang dimungkinkan oleh versi Manifest. Versi ini memberikan penyajian online, analisis offline, pekerjaan pengisian ulang, dan pemadatan sebuah tampilan bersama dari kumpulan data.
Hal ini mungkin terdengar seperti detail penyimpanan internal, tetapi hal ini memengaruhi seberapa cepat tim dapat melakukan iterasi pada set data AI. Setiap perubahan model, pengisian ulang fitur, koreksi keterangan, filter kualitas, dan pembangunan ulang indeks bergantung pada pertanyaan yang sama: "Dapatkah sistem memperbarui kumpulan data tanpa memindahkan data yang tidak perlu dipindahkan?"
Itulah nilai praktis dari model penyimpanan.
Loon tersedia di Milvus 3.0 beta dan Zilliz Vector Lakebase
Loon tersedia di Milvus 3.0 beta dan juga merupakan bagian dari lapisan penyimpanan di Zilliz Vector Lakebase, evolusi berikutnya dari Zilliz Cloud. Dan rilis ini berfokus pada tiga area inti:
- Manifes. Tujuannya adalah agar penulisan, pengisian ulang, penghapusan, statistik, dan pembaruan indeks dapat menghasilkan tampilan kumpulan data berversi yang dapat dibuka oleh pembaca secara konsisten. Bagi pembaca, ini berarti sebuah kueri dapat membuka versi Manifes tertentu dan melihat tampilan set data yang stabil. Bagi penulis, ini berarti bahwa file data baru, log hapus, statistik, atau file indeks dapat dipersiapkan terlebih dahulu dan kemudian dibuat terlihat melalui komit berversi.
- KolomGroup dan dukungan format. Parket mendukung kolom skalar dan kolom yang ramah ekosistem. Vortex mendukung pola akses vektor-berat. Lance dapat diintegrasikan dalam mode hanya-baca untuk kompatibilitas dengan kumpulan data Lance yang ada.
- Indeks di Lake. Statistik skalar, indeks pemfilteran, dan indeks terbalik teks dapat berpartisipasi dalam perencanaan berbasis Manifest berdasarkan rentang baris. Indeks vektor asli danau lebih banyak terlibat. HNSW dan IVF memiliki perilaku yang berbeda pada penyimpanan objek, dan HNSW khususnya sensitif terhadap akses acak dan lokalitas cache. HNSW tidak dapat begitu saja menggunakan kembali tata letak yang dirancang untuk SSD lokal dan mengharapkan hasil yang sama.
Masih ada pekerjaan di depan
- Jalur penulisan eksternal penting karena Spark dan Ray harus dapat menghasilkan komit ColumnGroups dan Manifest tanpa memaksa setiap penulisan ulang melalui perulangan SDK klien.
- Interoperabilitas Lakehouse penting karena banyak tim yang sudah menggunakan katalog dan mesin kueri seperti Iceberg, Delta Lake, Trino, DuckDB, dan Athena. Data vektor harus dapat berpartisipasi dalam ekosistem tersebut tanpa kehilangan kinerja pencarian vektor.
- Tata letak indeks penting karena indeks grafik dan struktur terbalik memiliki pola akses yang berbeda pada penyimpanan objek.
- Semantik objek besar penting karena video mentah, PDF, gambar, dan file audio memerlukan manajemen referensi, pembuatan versi, dan perilaku penghapusan yang selaras dengan kumpulan data vektor yang diturunkan.
Perilaku rilis yang tepat, pengaturan default, dan jalur migrasi harus mengikuti catatan rilis Milvus dan Zilliz Cloud yang relevan. Namun, arah penyimpanannya jelas: basis data vektor membutuhkan fondasi asli yang berversi di bawah lapisan penyajian.
Coba Loon di bawah Zilliz Vector Lakebase
Jika tumpukan Anda saat ini memisahkan penayangan online, analisis offline, pengisian ulang, dan alur kerja data lake eksternal ke dalam sistem yang berbeda, Zilliz Vector Lakebase patut dicoba. Anda dapat mencobanya di Zilliz Cloud. Pendaftaran email kantor baru mendapatkan kredit gratis $100. Anda juga dipersilakan untuk berbicara dengan kami tentang kasus penggunaan Anda.
Anda juga bisa mengikuti rilis Milvus 3.0 untuk melihat bagaimana Loon berevolusi dalam mesin sumber terbuka.
Zilliz Vector Lakebase menyatukan:
- Penyajian berjenjang untuk kinerja real-time yang berbeda dan pertukaran biaya
- Pencarian sesuai permintaan untuk beban kerja berskala besar atau eksplorasi tanpa komputasi yang selalu aktif
- Pencarian danau data eksternal, sehingga Anda dapat mengindeks dan mencari secara langsung di atas data danau yang ada
- Pencarian spektrum penuh di seluruh vektor, teks, JSON, dan data geospasial, dengan pengambilan dan pemeringkatan hibrida
- Penyimpanan asli danau terpadu yang dibangun di atas Vortex, format terbuka yang dirancang untuk pembacaan acak yang lebih cepat dan berbiaya lebih rendah pada data yang sangat banyak vektornya
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word



