Por qué construimos Loon: un motor de almacenamiento para datos de IA que nunca deja de cambiar.
Este blog se publicó originalmente en zilliz.com y se ha vuelto a publicar con permiso.
Puntos clave
Esta es una inmersión larga y profunda en ingeniería, así que aquí están los puntos clave antes de entrar en los detalles.
- Los conjuntos de datos de IA no son tablas estáticas. Las mismas filas cambian constantemente a medida que los equipos sustituyen los modelos de incrustación, añaden vectores dispersos, revisan las leyendas, rellenan las etiquetas, reconstruyen los índices y ejecutan análisis fuera de línea.
- Los esquemas de almacenamiento tradicionales se estropean de tres formas: las largas columnas de vectores encarecen los rellenos, un único formato de archivo no puede servir bien tanto para escaneos como para lecturas puntuales, y el almacenamiento privado en bases de datos obliga a las canalizaciones externas a crear copias adicionales de la verdad.
- Loon es el nuevo motor de almacenamiento de Milvus y Zilliz Vector Lakebase. Se basa en formatos de archivo híbridos, alineación de ID de fila y un Manifiesto que define el estado versionado del conjunto de datos.
- El objetivo es permitir que un único conjunto de datos vectoriales admita la búsqueda en línea, el análisis fuera de línea, los rellenos, la compactación y el cálculo externo sin copiar, reescribir o reimportar datos constantemente.
Introducción
Durante un tiempo, hubo un argumento en contra de las bases de datos vectoriales que sonaba razonable.
Las bases de datos tradicionales ya almacenan enteros, cadenas, JSON, blobs e índices. ¿Por qué no añadir un tipo _vector_ , construir un índice RNA a su lado y listo?
Para las primeras búsquedas semánticas, eso funciona bastante bien. Una columna vectorial más un índice pueden servir para una demo, una pequeña aplicación RAG o una función de búsqueda interna. El problema aparece más tarde, cuando el conjunto de datos empieza a comportarse menos como una tabla y más como un sistema de datos de IA.
Un conjunto de datos vectoriales de producción tiene filas, claves primarias, campos escalares y columnas consultables. En ese sentido, se parece a una tabla de base de datos. Pero también tiene la escala y la forma de flujo de trabajo de un lago de datos. Puede contener cientos de millones de registros. Es leído y reescrito repetidamente por Spark, Ray, DuckDB, pipelines de formación, trabajos de evaluación y sistemas de calidad de datos.
También depende del almacenamiento de objetos. Los objetos fuente suelen ser vídeos, imágenes, PDF, archivos de audio o documentos web que permanecen en S3, GCS, OSS u otro almacén de objetos. La base de datos almacena referencias, metadatos, características derivadas e índices. A continuación, añade elementos que los modelos de almacenamiento tradicionales no están diseñados para gestionar como objetos de primera clase: incrustaciones densas, vectores dispersos, subtítulos, índices vectoriales, índices de texto, registros de eliminación, estadísticas, versiones de modelos, versiones de analizadores sintácticos, referencias a blobs externos y las relaciones de versión entre todos ellos.
Ahí es donde empieza a fallar el "basta con añadir una columna vectorial". La cuestión no es si una base de datos puede almacenar bytes vectoriales. Muchos sistemas pueden. La cuestión más difícil es si el modelo de almacenamiento puede gestionar cómo cambian los datos vectoriales, cómo se consultan y cómo se comparten a través de la pila de datos de IA.
Por eso hemos creado Loon, el nuevo motor de almacenamiento para Milvus y Zilliz Vector Lakebase (la próxima evolución de Zilliz Cloud).
Loon está diseñado con tres ideas:
- Utilizar diferentes formatos físicos para diferentes tipos de columnas.
- Alinear esas columnas a través de un espacio compartido de ID de fila.
- Utilizar un Manifiesto para definir el estado versionado del conjunto de datos.
Para ver por qué estas piezas son importantes, empecemos con un flujo de trabajo multimodal común.
Un conjunto de datos vectorial nunca está realmente terminado.
Imaginemos un equipo de IA que crea un conjunto de datos de vídeo para el entrenamiento multimodal.
Se carga un vídeo largo en el almacenamiento de objetos. Un proceso lo corta en clips en función de los cambios de escena, los límites de las tomas o las ventanas de tiempo. Los clips demasiado largos o demasiado cortos, borrosos, duplicados o de baja calidad se filtran. Los clips restantes son puntuados por un modelo estético, subtitulados por otro modelo, integrados por un modelo de lenguaje visual y almacenados en una base de datos vectorial para búsqueda, deduplicación y filtrado de datos de entrenamiento.
A primera vista, el flujo de trabajo parece sencillo:
video
→ clips
→ metadata
→ aesthetic_score
→ caption
→ embedding
→ search / dedup / training data filtering
Pero el conjunto de datos no llega completamente formado.
- En la primera semana, la tabla sólo puede contener
clip_id,video_id,start_offset, yduration. - En la segunda semana, el equipo añade
aesthetic_score. - En la tercera semana, se ejecuta un modelo de subtitulado y cada clip recibe un
caption. - En la cuarta semana, se pone en marcha el primer modelo de incrustación y cada clip recibe una incrustación CLIP de 768 dimensiones.
- Un mes después, el equipo cambia de modelo y vuelve a rellenar
embedding_v2, ahora con 1024 dimensiones. - Dos meses más tarde, la búsqueda híbrida se convierte en un requisito, por lo que el equipo añade una columna de vectores dispersos.
- Tres meses después, los pies de foto se someten a revisión humana y deben corregirse in situ.
El conjunto de datos nunca se completó. Seguía acumulando nuevas interpretaciones de las mismas filas subyacentes.
Esa es una de las principales diferencias entre los datos vectoriales y los datos comerciales tradicionales. La misma fila se vuelve a procesar una y otra vez. Y la escala hace que esto pase de ser un inconveniente a un problema de almacenamiento: los conjuntos de datos multimodales no suelen tener millones de registros, sino cientos de millones o miles de millones. LAION-5B es una referencia útil para la forma: miles de millones de pares imagen-texto, cada uno con metadatos, pies de foto e incrustaciones. Así que lo difícil no es la primera inserción. Lo difícil es todo lo que ocurre después de que el conjunto de datos empiece a evolucionar. Esta evolución plantea tres problemas.
Primer problema: las columnas largas encarecen la amplificación de la escritura
Los formatos columnares como Parquet son excelentes para muchas cargas de trabajo analíticas. Funcionan bien cuando los esquemas son bastante estables, los datos se leen con más frecuencia que se reescriben, las exploraciones sólo afectan a un subconjunto de columnas y la compresión es importante. Ese es el mundo para el que se optimizaron muchos formatos analíticos.
Las filas vectoriales son mucho más anchas que las filas analíticas
TPC-H lineitem es una buena referencia. Tiene 16 columnas: claves enteras, valores decimales, fechas, cadenas cortas y un pequeño campo de comentarios. Una fila sin comprimir ocupa aproximadamente 150 bytes. Tras la compresión, puede ser mucho más pequeña. Con un grupo de filas de 64 MB, un sistema de almacenamiento puede empaquetar cientos de miles de filas en un solo grupo.
Los conjuntos de datos vectoriales no tienen ese aspecto.
Un conjunto de datos de imagen-texto del tipo LAION se parece mucho más a lo que producen hoy en día muchas cadenas de inteligencia artificial. Cada fila sigue teniendo metadatos normales: una URL, un pie de foto, anchura, altura, puntuaciones de calidad, etiquetas, etcétera. Pero una vez añadida la incrustación, la forma física de la fila cambia.
Un vector CLIP de 768 dimensiones ocupa aproximadamente 1,5 KB en fp16 o 3 KB en fp32. Esa única columna puede ser mucho mayor que una fila entera de TPC-H lineitem.
Y 768 dimensiones no son inusuales ni grandes para los estándares actuales. Una incrustación de 1024 o 2048 dimensiones es habitual en los pipelines multimodales. La página text-embedding-3-large de OpenAI llega hasta las 3072 dimensiones, lo que equivale a unos 12 KB por vector en fp32.
La comparación es clara:
| Forma del conjunto de datos | Tamaño aproximado de las filas | Qué domina la fila |
|---|---|---|
| Elemento de línea TPC-H | ~150 bytes sin comprimir | campos escalares y de cadena corta |
| Fila estilo LAION con vector fp16 de 768 dm | ~1,5 KB | incrustación |
| Fila de estilo LAION con vector fp32 de 768 dm | ~3 KB | incrustación |
| Fila con vector fp32 de 3072 dm | ~12 KB+ sólo el vector | incrustación |
En muchos conjuntos de datos de IA, la columna del vector no es un campo más. Físicamente, es la mayor parte de la fila. Eso cambia el coste de la evolución del esquema.
Añadir una columna vectorial puede suponer cientos de gigabytes
Supongamos que un conjunto de datos tiene 100 millones de clips de vídeo. Añadir una nueva columna de incrustación fp32 de 1024 dimensiones significa escribir aproximadamente 400 GB de datos vectoriales sin procesar. Esto no incluye estadísticas, índices, actualizaciones de metadatos, sobrecarga de almacenamiento de objetos, validación o integración de rutas de servicio.

Si el equipo añade una o dos columnas de tipo vectorial cada mes, como embedding_v2, sparse_vector, o funciones rerank, la evolución del esquema se convierte en un trabajo de ingeniería daAta recurrente que se mide en cientos de gigabytes o terabytes.
Las pequeñas actualizaciones lógicas pueden desencadenar grandes reescrituras físicas
Las actualizaciones son igual de importantes.
En los sistemas columnares, los datos antiguos no suelen actualizarse in situ. Un registro de borrado registra los cambios y, posteriormente, la compactación reescribe las filas activas en nuevos archivos. Este modelo es manejable cuando las filas son pequeñas.
Con datos vectoriales, una pequeña actualización lógica puede desencadenar una gran reescritura física.
Un trabajo de revisión humano puede corregir sólo unos cientos de bytes en un título. Pero si el título, el vector denso, el vector disperso y otras características derivadas comparten el mismo ciclo de vida físico del archivo, el sistema puede acabar reescribiendo también los vectores. El cambio lógico es pequeño. La E/S física puede ser enorme.
Este es el problema de amplificación de escritura en el almacenamiento vectorial. La parte costosa no es sólo que los vectores sean grandes. Es que los grandes campos derivados y los pequeños campos mutables a menudo están unidos por una disposición de almacenamiento que los trata como una unidad.
Para los conjuntos de datos de IA, el backfill es una carga de trabajo rutinaria.
En el caso de las tablas analíticas tradicionales, la evolución del esquema puede producirse sólo ocasionalmente. Para los conjuntos de datos de IA, es rutinaria. Los modelos de captura se actualizan. Los modelos de incrustación se sustituyen. Se añaden vectores dispersos. Aparecen características de reasignación. Se corrigen las etiquetas humanas. Se rellenan las etiquetas de gobernanza. Se reconstruyen los índices.
Estas operaciones no son simples añadidos. A menudo modifican o amplían las filas existentes.
Por ello, el almacenamiento vectorial no puede limitarse a optimizar el rendimiento de los escaneos. También tiene que abaratar los backfills y las actualizaciones parciales.
El segundo problema: los mismos datos deben soportar escaneos y lecturas puntuales
Una vez escritos los datos, la ruta de lectura se divide. Un mismo conjunto de datos vectoriales suele tener dos patrones de acceso distintos: la exploración analítica y las lecturas puntuales.
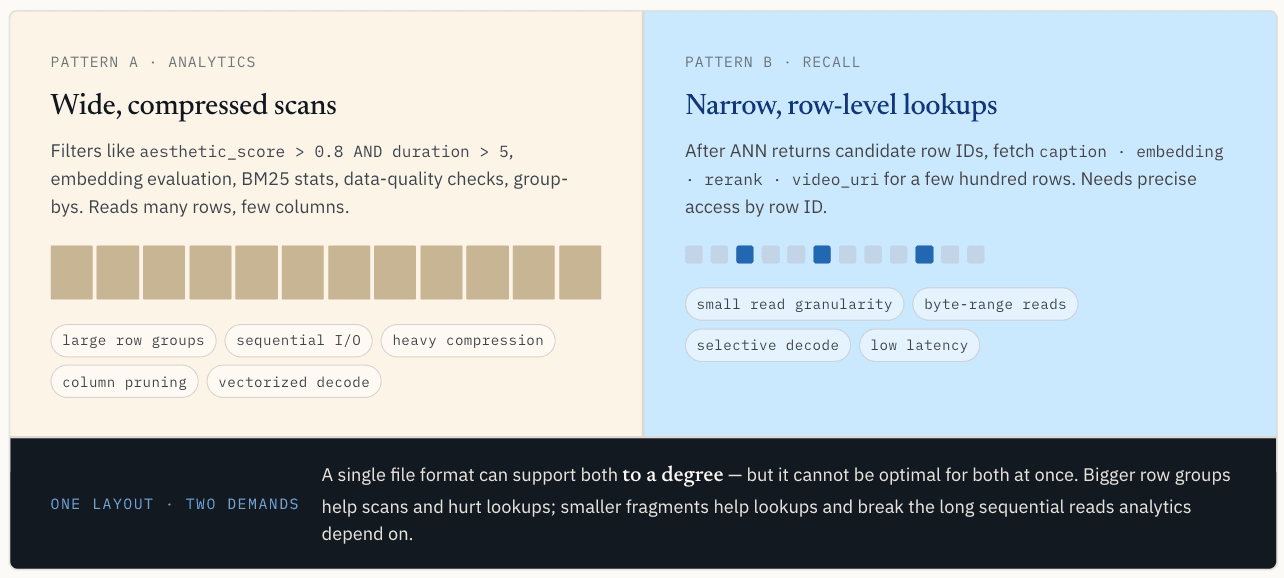
Las cargas de trabajo analíticas requieren barridos amplios y comprimidos.
Una canalización puede ejecutar filtros como:
WHERE aesthetic_score > 0.8 AND duration > 5
O puede ejecutar análisis fuera de línea, evaluación de incrustación completa, estadísticas BM25, construcción de mapas de bits, comprobaciones de calidad de datos, recuentos y agrupaciones.
Este patrón lee muchas filas pero sólo unas pocas columnas. Le gusta la E/S secuencial, los grupos de filas grandes, la compresión, la poda de columnas, la decodificación por lotes y la ejecución vectorizada.
Los grupos de filas grandes ayudan aquí. Permiten que una única solicitud de E/S extraiga una gran cantidad de datos útiles, mejoran la eficiencia de la compresión y proporcionan al motor de ejecución suficientes datos contiguos para amortizar la sobrecarga. Cuando se leen varias columnas juntas, mantenerlas organizadas para el rendimiento del escaneo también ayuda a reducir las pérdidas de caché durante la ejecución vectorizada.
Parquet es fuerte en este camino.
Los resultados de RNA necesitan búsquedas estrechas a nivel de fila
Después de que la búsqueda RNA devuelva los ID de las filas candidatas, el sistema a menudo necesita recuperar campos como:
caption
embedding
rerank feature
video_uri
metadata
Este patrón lee menos filas, a menudo cientos o miles, pero necesita un acceso preciso por ID de fila. Quiere localizar una fila y una columna concretas, obtener sólo el intervalo de bytes necesario y evitar extraer todo un grupo de filas sólo para recuperar unos pocos registros.
La búsqueda puntual tiene una preferencia casi opuesta a la exploración. Quiere una granularidad de lectura más pequeña. Idealmente, la capa de almacenamiento puede encontrar el segmento o rango de bytes relevante por ID de fila, leer sólo ese rango y decodificar sólo los datos necesarios para el resultado.
La compresión también tiene sus ventajas y desventajas. En el caso de los escaneos, una mayor compresión suele merecer la pena porque el sistema lee muchos datos y ahorra E/S. Para la búsqueda de puntos, la compresión puede convertirse en un inconveniente si la recuperación de una fila requiere la descodificación de un bloque comprimido mucho mayor.
Un diseño no puede optimizar ambas rutas
Este es el principal conflicto. El filtrado escalar y la analítica quieren diseños amplios, comprimidos y fáciles de escanear. La búsqueda vectorial quiere diseños estrechos, precisos y direccionables por filas.
Un único formato de archivo puede soportar ambas cosas hasta cierto punto, pero no puede ser óptimo para ambas simultáneamente.
Si todas las columnas viven en Parquet, los escaneos escalares son cómodos. Pero la búsqueda de RNA después de la recuperación se hace más difícil. El sistema puede necesitar sólo unos cientos de vectores, subtítulos o registros de metadatos, mientras que la capa de almacenamiento puede tener que leer grandes grupos de filas que contienen en su mayoría filas irrelevantes.
En un SSD local, la caché y el mmap pueden ocultar parte de este coste. Una vez que los datos se almacenan en el almacenamiento de objetos, el coste se hace más visible. Cada fallo de caché puede convertirse en una lectura de rango remoto. Si las filas candidatas están dispersas en muchos grupos de filas, una sola consulta puede desencadenar múltiples lecturas, cada una de ellas extrayendo más datos de los que la consulta necesita. En un diseño mal distribuido, buscar 1.000 filas candidatas puede fácilmente resultar en decenas o cientos de megabytes de E/S innecesarias, y en casos extremos, mucho más.
Hacer grupos de filas más pequeños ayuda a la búsqueda puntual, pero perjudica a las exploraciones. Demasiados fragmentos pequeños reducen la eficacia de la compresión, aumentan la sobrecarga de metadatos y rompen las largas lecturas secuenciales de las que dependen los motores analíticos.
Así que el problema no es encontrar un tamaño mágico de grupo de filas. El problema es que se está pidiendo al mismo conjunto de datos que se comporte como dos sistemas de almacenamiento diferentes.
La búsqueda híbrida fuerza ambos caminos en una sola consulta
La búsqueda híbrida hace que el conflicto sea más difícil de ignorar. Una sola consulta puede aplicar primero filtros escalares:
aesthetic_score > 0.8 AND duration > 5
A continuación, ejecuta la búsqueda RNA.
A continuación, obtiene el título, el vector y los metadatos por ID de fila.
Para el usuario, se trata de una solicitud de búsqueda. Para la capa de almacenamiento, se trata tanto de una exploración analítica como de una búsqueda aleatoria de baja latencia.
Por eso, el almacenamiento vectorial necesita algo más que una mejor configuración de Parquet. Necesita una forma de colocar las distintas columnas en función de cómo se lean realmente.
El tercer problema: el conjunto de datos no vive dentro de un motor
Los dos primeros problemas ocurren dentro de la base de datos. El tercero se produce en la frontera entre sistemas.

Los canales de datos de IA abarcan muchos sistemas
En el flujo de trabajo de vídeo, ocurre muy poco dentro de la propia base de datos vectorial.
Los vídeos sin procesar se almacenan en objetos. La generación de clips puede ejecutarse en Spark o Ray. La puntuación estética puede ejecutarse en un servicio GPU. El subtitulado puede ejecutarse en un canal de inferencia LLM. Las incrustaciones pueden ser generadas por otro trabajo de la GPU. Los vectores dispersos pueden proceder de un servicio SPLADE. La evaluación offline, el filtrado de datos de entrenamiento, la revisión humana y los trabajos de gobernanza pueden ejecutarse en cualquier otro lugar.
La base de datos vectorial sirve para la búsqueda en línea, pero el conjunto de datos es producido, corregido, evaluado y ampliado por muchos sistemas.
Los formatos de almacenamiento privados crean múltiples copias de la verdad
Si la base de datos utiliza un formato físico privado que sólo ella puede leer y escribir, cada trabajo externo necesita una exportación, una conversión, una copia y una importación. La misma colección puede existir en la base de datos, en un directorio temporal de Spark, en una salida de evaluación y en un directorio local de backfill. Entonces la verdadera pregunta es:
- ¿Qué copia es la fuente de la verdad?
- ¿Cuál contiene el modelo de capturas del mes pasado?
- ¿Qué filas ya han sido corregidas mediante revisión humana?
- ¿Qué columna de vectores dispersos fue generada por qué modelo?
- ¿Qué índice vectorial sigue siendo válido tras el relleno?
- ¿A qué objeto de vídeo original se refiere esta fila?
A pequeña escala, los equipos a veces pueden sobrevivir con convenciones de nomenclatura y comprobaciones manuales. Con cientos de millones de filas y terabytes de incrustaciones, esto se convierte en un problema de coherencia.
Los conjuntos de datos vectoriales necesitan un estado versionado compartido
Los sistemas Lakehouse abordaron una versión de este problema para los datos estructurados. Iceberg, Delta Lake y Hudi no se limitan a almacenar archivos. Su principal contribución consiste en permitir que varios motores se coordinen en torno al mismo estado de tabla.
Las bases de datos vectoriales necesitan ahora una capacidad similar, pero el estado es más complejo. No sólo debe incluir archivos de tablas y particiones, sino también índices vectoriales, índices de texto, características dispersas, registros de borrado, estadísticas, rangos de ID de filas y referencias a blobs externos.
La pregunta no es simplemente: "¿Puede Spark leer archivos Milvus?".
La pregunta es, después de que Spark rellena una columna de vector disperso, ¿cómo sabe Milvus a qué versión pertenece esa columna, qué filas cubre, qué modelo la produjo y cuándo pueden utilizarla con seguridad las consultas en línea?
La respuesta tiene que estar en el modelo de almacenamiento.
Por qué los parches no bastan
Resulta tentador tratar estos problemas como tres problemas de ingeniería independientes.
- ¿Ampliación de escritura? Añada la dosificación.
- ¿Lecturas puntuales? Añada una caché.
- ¿Sistemas externos? Añada herramientas de exportación e importación.
Estos parches pueden ayudar, pero no abordan el problema subyacente: un conjunto de datos vectoriales es físicamente heterogéneo.

En el ejemplo del vídeo, clip_id, video_id, duration, y aesthetic_score son campos escalares cortos. Son útiles para el filtrado y el análisis.
captiones texto. Puede utilizarse para BM25, revisión, corrección y relleno.embeddinges un vector largo y denso. Se utiliza para la recuperación de la RNA y, posteriormente, para la búsqueda a nivel de fila o la reordenación.embedding_v2es una nueva salida del modelo, a menudo rellenada mucho después de que se insertaran los datos originales.sparse_vectorsoporta la búsqueda híbrida y tiene su propio patrón de acceso.- El vídeo en bruto debe permanecer en el almacenamiento de objetos. La base de datos debe almacenar una referencia, una suma de comprobación, un tipo MIME, una versión del analizador sintáctico y una relación a nivel de fila.
- Los índices vectoriales, los índices de texto, las estadísticas y los registros de borrado son objetos derivados con su propia semántica de versiones.
Estos objetos comparten una fila lógica, pero no todos deben compartir la misma disposición física ni el mismo ciclo de vida.
- Si se fuerzan a una disposición de tabla ordinaria, las actualizaciones resultan caras.
- Si se fuerzan a un formato de archivo columnar, las lecturas de puntos se encarecen.
- Si se tratan como archivos de objetos no relacionados, la gestión de versiones se vuelve frágil.
Por tanto, el modelo de almacenamiento debe partir del hecho de que el conjunto de datos es heterogéneo.
De ahí se derivan tres requisitos de diseño:
- En primer lugar, los distintos grupos de columnas deben almacenarse en formatos físicos diferentes.
- En segundo lugar, esos grupos de columnas necesitan un espacio de ID de fila compartido, de modo que puedan seguir comportándose como una única tabla lógica.
- En tercer lugar, el conjunto de datos necesita un manifiesto versionado que declare qué archivos, índices, registros, estadísticas y referencias a objetos pertenecen a la vista actual.
Este es el diseño detrás de Loon, nuestro nuevo motor de almacenamiento detrás de Milvus y Zilliz Cloud.
Loon: un motor de almacenamiento detrás de Milvus y Zilliz Cloud para conjuntos de datos vectoriales en evolución
Para resolver todos los problemas anteriores, hemos construido Loon, el nuevo motor de almacenamiento para Milvus y Zilliz Vector Lakebase (la próxima evolución de Zilliz Cloud), diseñado para conjuntos de datos vectoriales en evolución.
El nombre sigue la tradición de Zilliz de poner nombres a las aves. Un colimbo es un ave buceadora que vive en los lagos, lo que se corresponde perfectamente con el objetivo del sistema: una base de datos vectorial no debería tener que mover, escanear o reescribir un lago entero de datos cada vez que ejecuta una consulta, rellena una columna o construye un índice. Primero debería comprender la versión actual del conjunto de datos, incluidas sus columnas, índices, estadísticas, registros de borrado y referencias a objetos, y después leer sólo la parte que realmente necesita.
Los formatos de archivo híbridos, la alineación de ID de fila y el Manifiesto no son tres características separadas. Se derivan de la misma premisa de diseño: un conjunto de datos vectorial es inherentemente heterogéneo.
Tres piezas, un modelo de almacenamiento
Los formatos de archivo híbridos reconocen que las diferentes columnas tienen diferentes patrones de acceso. Los campos escalares son adecuados para exploraciones y filtros. Los campos vectoriales necesitan una búsqueda eficiente a nivel de fila. Los objetos en bruto, como vídeos, PDF, imágenes y archivos de audio, deben almacenarse en objetos, no en archivos de datos de bases de datos.
La alineación de ID de fila reconoce que estas columnas pueden estar separadas físicamente, pero siguen describiendo las mismas filas lógicas. Un pie de foto, una incrustación, un vector disperso y un URI de vídeo pueden residir en archivos y formatos diferentes, pero aún así deben reunirse como un único resultado.
El Manifiesto reconoce que el conjunto de datos no se escribe una vez y se deja solo. Será modificado por múltiples sistemas, a través de múltiples versiones, para múltiples tareas. Los índices, las estadísticas, los registros de borrado, las referencias a objetos externos y los grupos de columnas deben aparecer en la misma vista versionada.
Por eso Loon no es sólo un formato de archivo vectorial más rápido. Un formato más rápido ayuda a la búsqueda de puntos, pero no resuelve la evolución del esquema ni la coordinación entre varios motores. La alineación de ID de fila permite que las columnas divididas se comporten como una única tabla, pero no especifica qué archivos pertenecen a la versión actual. Un manifiesto puede describir el estado de un conjunto de datos, pero sin grupos de columnas ni alineación de ID de fila, no puede representar limpiamente diferentes disposiciones físicas dentro de una colección lógica.
El modelo de almacenamiento necesita las tres cosas: diferentes formatos para diferentes grupos de columnas, un espacio compartido de ID de fila para reconstruir las filas y un Manifiesto versionado que indique a cada lector y escritor cuál es el conjunto de datos actual.
Dónde encaja Loon en Milvus y Zilliz Vector Lakebase
En Milvus, sustituye la antigua capa de almacenamiento binlog de segmentos por un modelo construido en torno a Manifest, ColumnGroup, formato de archivo y abstracciones del sistema de archivos. En Zilliz Vector Lakebase (la próxima evolución de Zilliz Cloud), la misma dirección se aplica a la arquitectura de Vector Lakebase: mantener la ruta de servicio de la base de datos vectorial rápida mientras se hace que los datos subyacentes sean más fáciles de evolucionar, analizar y coordinar con sistemas externos.
Los componentes Milvus de nivel superior siguen manteniendo sus funciones familiares. Proxy se encarga del enrutamiento. QueryCoord y DataCoord gestionan la programación. IndexNode crea índices. Las API orientadas a la aplicación para colecciones, inserciones, búsquedas y búsquedas híbridas no necesitan exponer archivos Manifest o ColumnGroups.
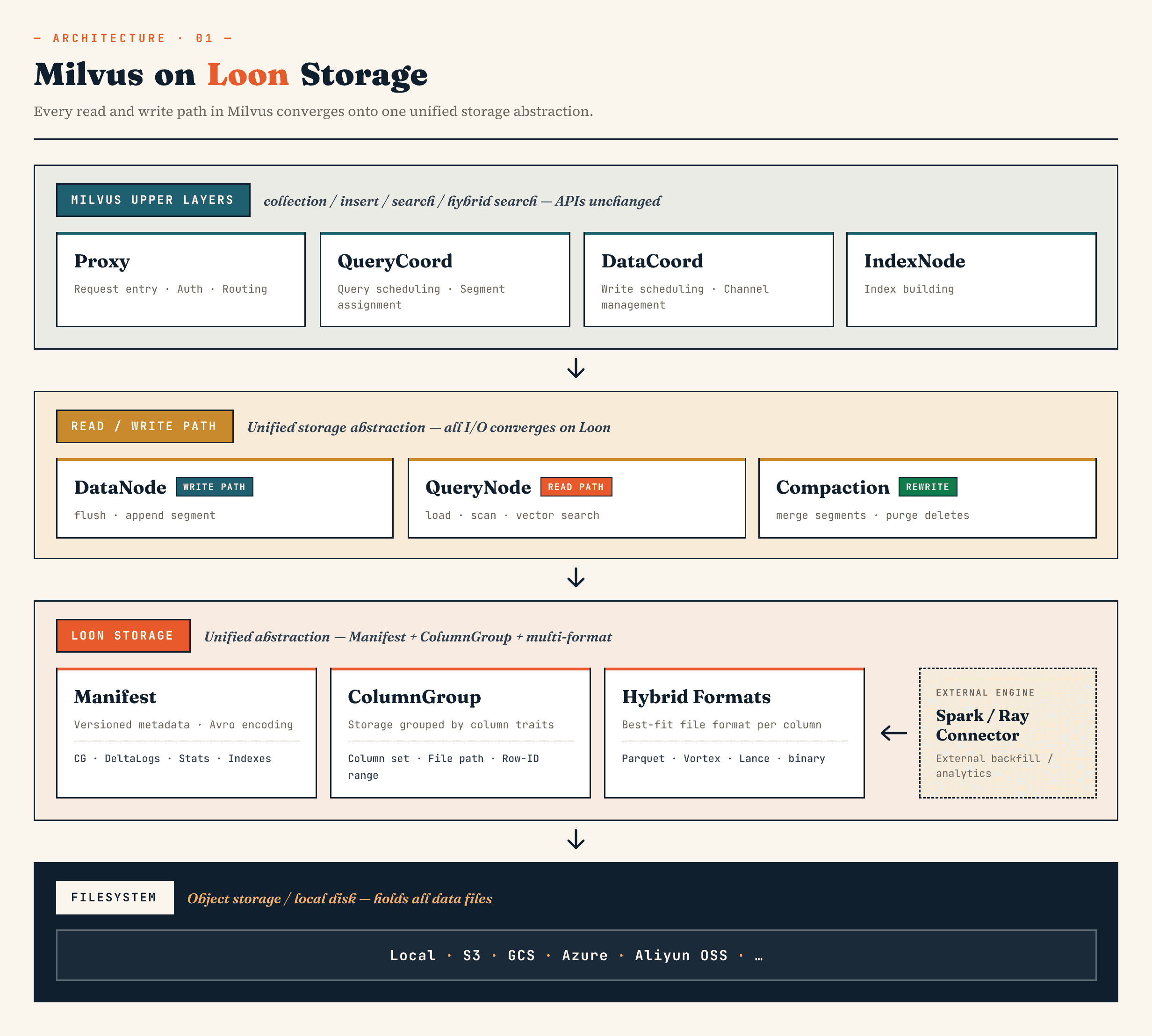
El cambio está por debajo.
DataNode, QueryNode, segcore, compactación y conectores externos pueden operar a través de la misma abstracción de almacenamiento. Esto es importante porque el conjunto de datos ya no es escrito y leído únicamente por la base de datos. Puede ser ampliado por sistemas informáticos externos y consumido simultáneamente por la búsqueda en línea.
A alto nivel, las capas tienen este aspecto:
Manifest
→ ColumnGroup
→ file format layer
→ filesystem abstraction
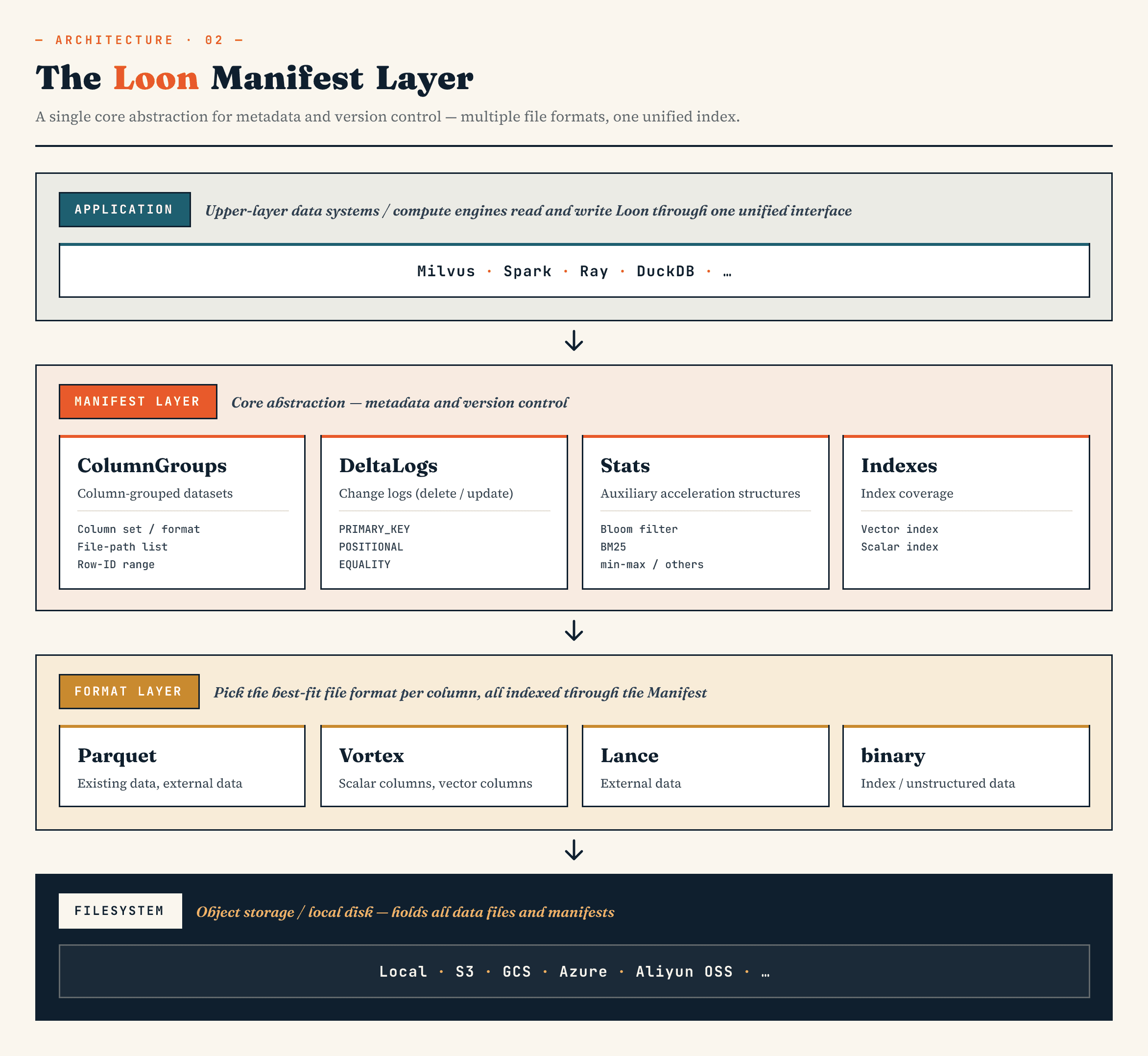
El Manifiesto describe el estado versionado del conjunto de datos. ColumnGroups mapea una colección lógica en grupos físicos de columnas. La capa de formato de archivo permite a cada ColumnGroup elegir el formato adecuado. La abstracción del sistema de archivos funciona tanto en el almacenamiento de objetos como en el almacenamiento local.
Lo importante es que los formatos de archivo híbridos, la alineación de ID de fila y el Manifiesto no son características separadas. Juntos, definen el modelo de almacenamiento.
Con ese modelo en su lugar, podemos ver las tres opciones de diseño una por una: cómo Loon almacena diferentes ColumnGroups, cómo los alinea de nuevo en filas, y cómo el Manifiesto convierte esos archivos en un conjunto de datos versionados.
Diseño 1: utilizar el formato de archivo adecuado para el grupo de columnas adecuado
Las diferentes columnas tienen diferentes patrones de acceso. No deben ser forzadas al mismo formato de archivo.
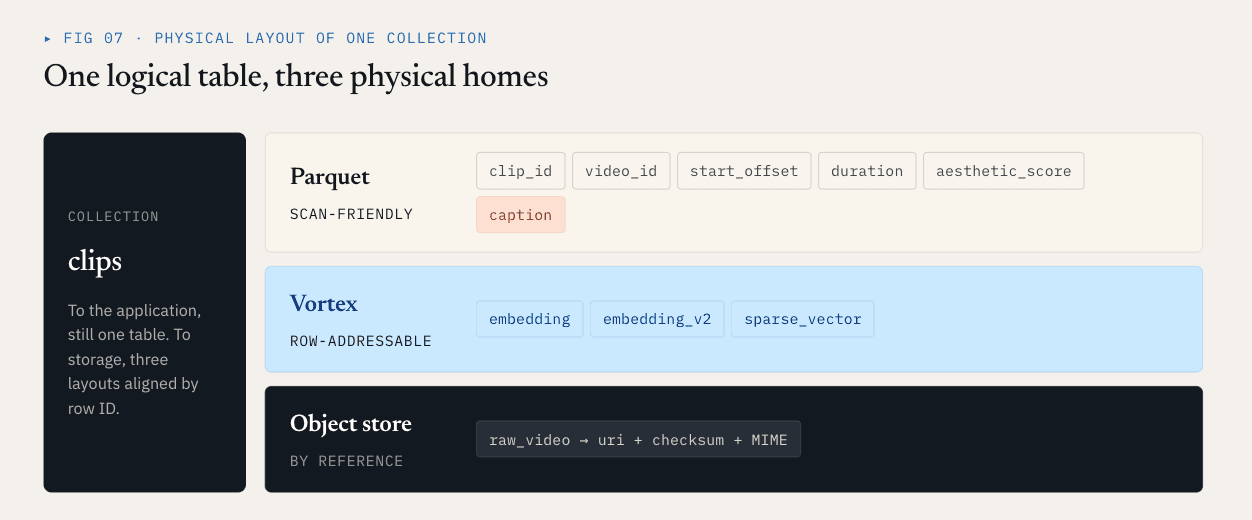
Loon separa una colección lógica en ColumnGroups.
- Los campos escalares, los campos de filtro, las claves de negocio y los campos estadísticos suelen explorarse, filtrarse, agregarse o utilizarse para la planificación de consultas. Se benefician de la compresión, la poda de columnas y la compatibilidad con el ecosistema. Parquet se adapta bien a estas columnas.
- Los vectores densos, los vectores dispersos y las características rerank suelen leerse después de la recuperación de RNA por ID de fila. Necesitan acceso aleatorio de baja latencia, lecturas precisas por rango de bytes y descodificación selectiva. Un diseño orientado a segmentos es más adecuado. Loon utiliza Vortex en esta dirección.
- Los objetos en bruto, como vídeos, PDF, imágenes y archivos de audio, no deben incrustarse en los archivos de datos de la base de datos vectorial. Deben permanecer en el almacenamiento de objetos. La base de datos registra referencias, sumas de comprobación, tipos MIME, versiones del analizador sintáctico y relaciones a nivel de fila.
Para el ejemplo del vídeo, un diseño físico podría tener este aspecto:
Parquet ColumnGroup:
clip_id / video_id / start_offset / duration / aesthetic_score / caption
Vortex ColumnGroups:
embedding
embedding_v2
sparse_vector
Object storage:
raw video objects
Para la aplicación, esto sigue siendo una colección. Para la capa de almacenamiento, las distintas partes de esa colección utilizan formatos físicos diferentes. Esto reduce directamente las reescrituras innecesarias. Añadir embedding_v2 puede convertirse en un nuevo vector ColumnGroup más un commit del Manifiesto. No requiere reescribir la columna de subtítulos, los metadatos escalares o la columna de incrustación existente.
La misma idea se aplica a vectores dispersos, características rerank u otros campos derivados. Si una nueva columna puede ser físicamente independiente y alineada por ID de fila, no tiene que arrastrar columnas no relacionadas a través de la misma ruta de reescritura.
Loon también adapta el uso de formatos de archivo.
En el caso de Parquet, la configuración por defecto no siempre es ideal para datos con muchos vectores. Un grupo de filas de 64 MB puede ser demasiado grande para la búsqueda de puntos porque una pequeña lectura aleatoria puede extraer muchos más datos de los necesarios. Loon reduce los grupos de filas a 1 MB en las rutas relevantes y desactiva las codificaciones, como la codificación de diccionario en columnas de vectores, cuando no ayudan a los datos vectoriales de aspecto aleatorio.
Para Vortex, el trabajo más importante es la disposición. Loon utiliza un diseño que equilibra la eficiencia del escaneado y la búsqueda de puntos. Dentro de un grupo de filas, los segmentos de columnas relacionadas pueden colocarse muy juntos para facilitar la exploración. Para realizar operaciones, las lecturas de subsegmentos permiten al sistema recuperar sólo los bytes relevantes en lugar de extraer un segmento entero.
Loon también admite la integración de Lance de sólo lectura, por lo que los conjuntos de datos Lance existentes pueden montarse como ColumnGroups cuando la compatibilidad es importante.
Lo que muestra el benchmark
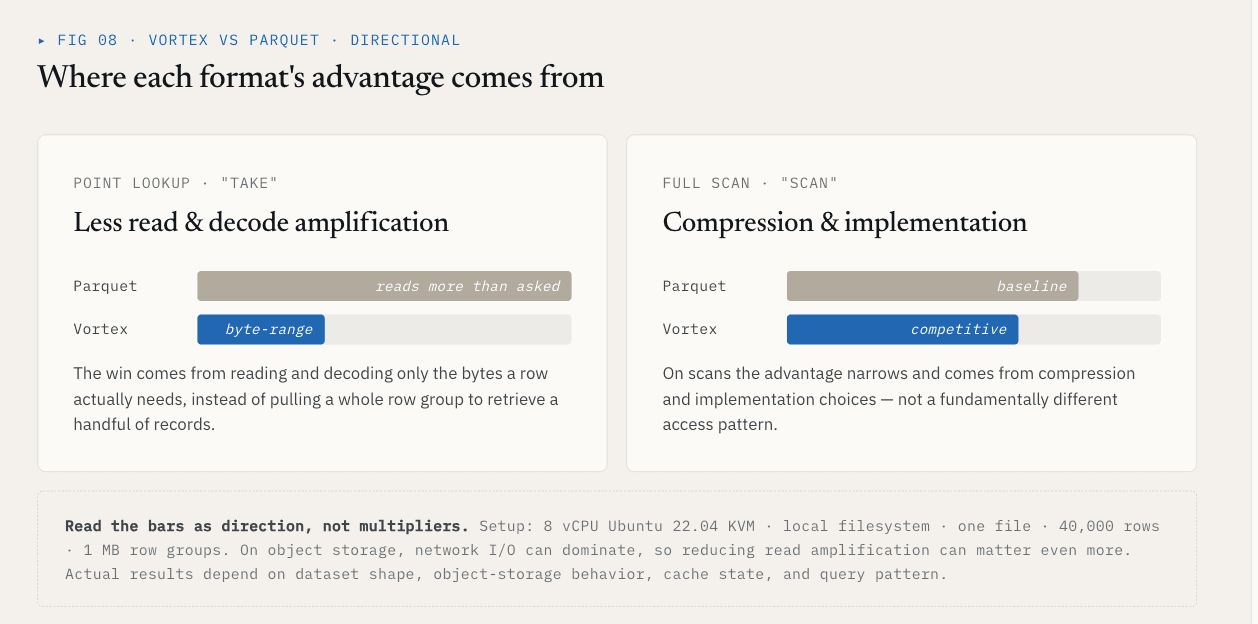
En una prueba local, utilizando un único archivo con 40.000 filas y el esquema {id: int64, name: utf8, value: float64, vector: list<float32>[128]}, Vortex mostró estos resultados frente a Parquet con grupos de filas de 1 MB:
| Operación | Vortex | Parquet | Diferencia |
|---|---|---|---|
| Toma, K=1000 filas aleatorias | 5,8 ms | 144 ms | 25 veces más rápido |
| Escaneado completo vector-columna | 21 ms | 142 ms | 6,76 veces más rápido |
| Tamaño del archivo, ~21 MB de datos sin procesar | 6,62 MB | 7,16 MB | 7% más pequeño |
El resultado de take se debe a la reducción de la cantidad de datos irrelevantes que hay que leer y descodificar. El resultado del escaneado procede de las opciones de compresión e implementación.
Estos números deben permanecer unidos a su configuración: 8 vCPU Ubuntu 22.04 KVM, sistema de archivos local, un archivo, 40.000 filas, grupos de filas de 1 MB y el esquema anterior. En el almacenamiento de objetos, la E/S de red puede dominar, por lo que reducir la amplificación de lectura puede ser aún más importante. Los resultados reales dependen de la forma del conjunto de datos, el comportamiento del almacenamiento de objetos, el estado de la caché y el patrón de consulta.
En general, no se trata de que todas las columnas deban utilizar Vortex.
La cuestión es que los conjuntos de datos vectoriales necesitan una elección de formato de archivo en el nivel ColumnGroup.
Diseño 2: alinear archivos físicos mediante ID de fila
Los formatos de archivo híbridos resuelven un problema: las distintas columnas pueden vivir ahora en los formatos que mejor se adapten a ellas.
Pero esto crea un segundo problema. Si los campos escalares viven en Parquet, los vectores viven en Vortex, y los objetos en bruto viven en el almacenamiento de objetos, ¿cómo puede el sistema seguir tratándolos como una colección?
Loon resuelve esto con la alineación de ID de fila.
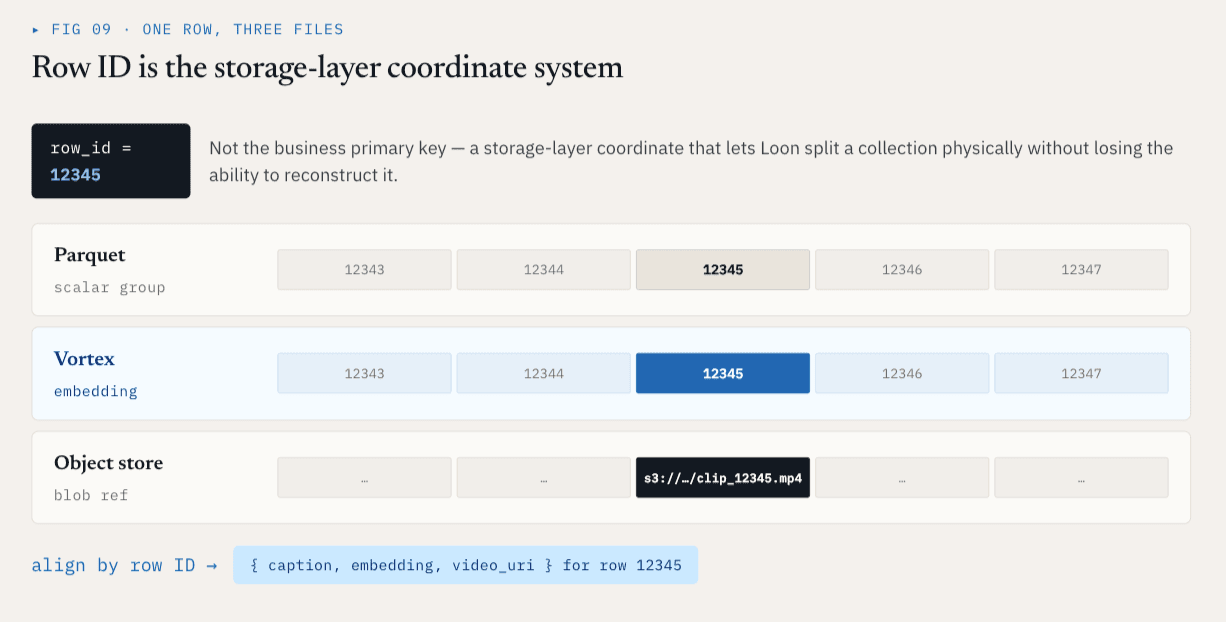
El ID de fila es el sistema de coordenadas de la capa de almacenamiento.
Cada ColumnGroupFile físico registra la ruta del archivo y el rango de ID de fila que cubre:
path
start_index
end_index
Diferentes ColumnGroups pueden cubrir el mismo espacio de ID de fila aunque vivan en diferentes ficheros y formatos.
Para el ID de fila 12345, los metadatos escalares pueden estar en un Parquet ColumnGroup, la incrustación puede estar en un Vortex ColumnGroup, y el vídeo en bruto puede estar representado por una referencia de almacenamiento de objetos. Lógicamente, siguen siendo una sola fila. Esto proporciona a la capa de almacenamiento un sistema de coordenadas estable.
El ID de fila no es la clave primaria del negocio. Es el sistema de coordenadas de la capa de almacenamiento que permite a Loon dividir físicamente una colección sin perder la capacidad de reconstruirla lógicamente.
Las columnas nuevas no tienen que reescribir las columnas antiguas
Añadir embedding_v2 no requiere reescribir el título original, metadatos, o embedding_v1 ColumnGroups. Loon puede escribir un nuevo vector ColumnGroup, registrar el rango de ID de fila que cubre y confirmar ese cambio a través del Manifiesto.
Lo mismo se aplica a los vectores dispersos, características rerank, u otros campos derivados que llegan más tarde.
Mientras el nuevo ColumnGroup cubra el rango de ID de fila correcto, puede unirse a la misma colección lógica sin forzar el movimiento de datos no relacionados.
Los borrados y la compactación pueden ser más específicos
La alineación del ID de fila también ayuda con los borrados.
Un borrado puede expresarse primero a través de un registro de borrado. La fila se vuelve invisible a nivel lógico, mientras que la limpieza física se retrasa hasta la compactación. Cuando finalmente se ejecuta la compactación, no siempre es necesario reescribir cada ColumnGroup vinculado a las filas afectadas. Puede centrarse en los ColumnGroups que necesitan limpieza.
Esto es importante porque no todas las columnas tienen el mismo perfil de coste. Reescribir un ColumnGroup escalar corto es muy diferente de reescribir cientos de gigabytes de vectores densos.
La búsqueda híbrida puede obtener sólo las columnas que necesita.
La alineación de ID de fila es también lo que hace que la búsqueda híbrida sea práctica sobre formatos de archivo híbridos.
Después de que la búsqueda RNA devuelva los ID de fila candidatos, el sistema puede obtener sólo los campos necesarios para el resultado final: pies de foto, metadatos, vectores, características rerank o referencias a objetos.
Por ejemplo, una consulta puede necesitar:
caption
embedding
video_uri
Estos campos pueden estar en diferentes ColumnGroups. Loon puede localizar los archivos relevantes por rango de ID de fila, leer los rangos de bytes necesarios y ensamblar el resultado.
Sin la alineación de ID de fila, los formatos híbridos serían simplemente archivos separados uno al lado del otro. Con la alineación de ID de fila, se comportan como una única colección lógica.
Packed Reader oculta la división a la capa superior
El componente en tiempo de ejecución que hace esto utilizable es el Packed Reader.
La capa superior ve un flujo unificado Arrow RecordBatch. Por debajo, los datos pueden provenir de múltiples ColumnGroups en diferentes formatos de archivo. El Packed Reader oculta esas diferencias, alinea los datos por rangos de ID de fila y programa la E/S de múltiples archivos con un uso controlado de la memoria.
También admite directamente take por ID de fila. Dado un conjunto de ID de fila, localiza los ColumnGroupFiles relevantes, emite lecturas de rango y devuelve los campos solicitados.
Para el flujo de trabajo de vídeo, una consulta RNA puede necesitar caption, embedding, y video_uri. El lector empaquetado puede obtener el ColumnGroup escalar y el ColumnGroup vectorial sin tocar columnas no relacionadas.
Esa es la diferencia entre "archivos separados" y "una tabla con múltiples diseños físicos".
Diseño 3: hacer del Manifiesto la fuente de la verdad
Los formatos de archivo híbridos definen cómo se almacenan físicamente los datos. La alineación de ID de fila determina cómo los ColumnGroups separados siguen formando una única tabla lógica. Pero el sistema aún necesita responder a una pregunta mayor: ¿qué archivos, registros, estadísticas, índices y referencias de objetos pertenecen a la versión actual del conjunto de datos? Esa es la tarea del Manifiesto.

Los directorios de almacenamiento de objetos no son suficientes
El almacenamiento de objetos no es un catálogo de base de datos. Un directorio puede contener archivos antiguos, archivos nuevos, resultados de trabajos fallidos, archivos temporales, registros de borrado, archivos a los que todavía hacen referencia instantáneas anteriores y archivos en espera de limpieza. El hecho de que un archivo exista no significa que pertenezca a la versión actual del conjunto de datos.
Un conjunto de datos Loon puede estar organizado en directorios como:
_metadata/
_data/
_delta/
_stats/
_index/
Pero la estructura de directorios no es la fuente de la verdad. El Manifiesto sí lo es. Los lectores no deben listar los directorios e inferir el estado de los archivos que existan. Deberían leer el Manifiesto actual y seguir la vista versionada que declara.
El manifiesto define una vista versionada del conjunto de datos
El manifiesto define el conjunto de datos en una versión determinada. Registra
- qué ColumnGroups existen
- qué rangos de ID de fila cubren
- qué formato físico utiliza cada ColumnGroup
- dónde se encuentran los archivos
- qué registros de borrado están activos
- qué estadísticas están disponibles
- qué índices existen
- a qué blobs externos se hace referencia
- qué columnas y rangos de filas cubren esas estadísticas o índices
Cada actualización escribe una nueva versión del Manifiesto. Un lector que abre la versión N ve una vista estable del conjunto de datos en la versión N. Un escritor puede preparar la versión N+1 sin interrumpir a los lectores que siguen utilizando la versión N.
El Manifiesto rastrea algo más que archivos de tablas
En Loon, el cuerpo del Manifiesto se codifica con Apache Avro y se organiza en torno a cuatro secciones principales.
- ColumnGroups describe las columnas, formatos, archivos y rangos de ID de fila.
- DeltaLogs describe los borrados. Diferentes tipos de borrado cubren diferentes fuentes de cambio, como borrados de clave primaria de clientes, borrados posicionales de compactación interna o borrados de igualdad de motores externos.
- Las estadísticas incluyen metadatos de planificación como filtros bloom, estadísticas BM25 y valores mín./máx.
- Los índices describen el tipo de índice, los parámetros, las columnas cubiertas y los rangos de ID de fila. Pueden incluir índices vectoriales como HNSW o IVF, índices de texto, índices invertidos, índices de mapa de bits y estructuras relacionadas.
Aquí es donde Loon difiere de un manifiesto de tabla tradicional.
Un conjunto de datos vectoriales no sólo debe rastrear archivos de datos y particiones. También necesita rastrear índices vectoriales, índices de texto, características dispersas, registros de borrado, estadísticas, referencias a objetos externos y los rangos de ID de fila que los conectan.
El Manifiesto debe poder ser escrito por algo más que la base de datos
Lo más importante no es sólo lo que contiene el Manifiesto. Es quién puede escribirlo.
- Si sólo la base de datos puede escribir el Manifiesto, siguen siendo metadatos internos. Metadatos más limpios, pero aún privados para un motor.
- Si motores externos pueden generar nuevos ColumnGroups, estadísticas y entradas de Manifiesto, el Manifiesto se convierte en una interfaz de coordinación.
- Un trabajo de Spark, por ejemplo, puede rellenar una columna de vectores dispersos. Escribe un nuevo ColumnGroup, registra la cobertura de filas y las estadísticas, y consigna un nuevo Manifiesto. Las consultas en línea pueden seguir leyendo la versión antigua durante el trabajo. Una vez que el commit tiene éxito, la nueva versión se hace visible.
Esto es similar en espíritu a Iceberg y Delta Lake, pero el modelo de objetos es más amplio. Un conjunto de datos vectoriales necesita realizar un seguimiento de índices vectoriales, índices de texto, características dispersas, registros de borrado, estadísticas, referencias a blobs y rangos de ID de filas, no sólo de archivos de tablas y particiones.
Las confirmaciones optimistas simplifican las actualizaciones de versiones
Cada confirmación escribe una nueva versión del Manifiesto. Un escritor puede construir nuevo contenido basado en la versión N, y luego intentar escribir manifest-{N+1}.avro. La escritura condicional del almacenamiento de objetos o la semántica de coincidencia de generación pueden hacer que la confirmación falle si esa versión ya existe. El escritor puede volver a intentarlo con la versión más reciente.
Esto proporciona a Loon una concurrencia optimista sin forzar cada actualización a través de una ruta de coordinación pesada y fuertemente consistente. Sin un manifiesto, el almacenamiento multiformato y multimotor acaba convirtiéndose en convenciones de nomenclatura y reconciliación manual. Esto puede funcionar para pequeños conjuntos de datos. No funciona para datos vectoriales a escala TB.
El Manifiesto es lo que convierte archivos heterogéneos en un conjunto de datos que múltiples sistemas pueden leer y actualizar con seguridad.
Qué cambia para los usuarios cuando el almacenamiento se convierte en versionado
Para los desarrolladores de aplicaciones, Loon no debería convertirse en una nueva carga para la API.
Los usuarios deberían seguir trabajando con conceptos Milvus familiares: colecciones, inserciones, búsqueda y búsqueda híbrida. No deberían tener que pensar en archivos Manifest, ColumnGroups, rangos de ID de filas o diseño de archivos durante el desarrollo normal de aplicaciones.
El cambio está por debajo. El almacenamiento es más consciente de cómo evolucionan realmente los conjuntos de datos de IA.
Añadir una nueva incrustación no debe mover los datos antiguos
Anteriormente, añadir embedding_v2 a una colección existente a menudo requería exportar los datos, entrenar un nuevo modelo, generar vectores y, a continuación, volver a importar o actualizar la colección a través del SDK. Esa ruta genera mucho trabajo operativo: seguimiento de versiones, reintentos de trabajos fallidos, reconstrucciones de índices, impacto en el servicio y comprobaciones de coherencia.
Con Loon, esto puede convertirse en una evolución del esquema más un nuevo commit de ColumnGroup. La nueva columna de incrustación puede escribirse como su propio ColumnGroup físico, alineado por ID de fila, y hacerse visible a través del Manifiesto. La antigua columna de título, la columna de metadatos escalares y la columna de incrustación original no necesitan moverse.
Los backfills no deberían requerir un bucle de actualización del lado del cliente
Muchas actualizaciones de datos de IA son rellenos. Un equipo puede añadir vectores dispersos después de que la búsqueda híbrida sea importante. Puede añadir características rerank después de entrenar un nuevo modelo. Puede corregir subtítulos tras una revisión humana. Puede añadir etiquetas de gobernanza tras la actualización de una política.
En un diseño tradicional, estos cambios se producen a menudo a través de actualizaciones del SDK del cliente o de rutas de escritura exclusivas de la base de datos, incluso cuando los datos son producidos por Spark, Ray u otro motor externo.
Con Loon, los sistemas de computación externos pueden producir nuevos ColumnGroups y confirmarlos a través del Manifiesto. La base de datos ya no tiene que ser el único punto de entrada para cada reescritura.
El análisis fuera de línea no debe requerir otra copia de la verdad
Anteriormente, los equipos a menudo volcaban una colección en línea en Parquet para su evaluación o análisis fuera de línea. Esto creaba dos versiones del mismo conjunto de datos: la colección en línea y la copia de análisis. Una vez que se corrigen los subtítulos, se regeneran las incrustaciones, se aplican los registros de borrado o se reconstruyen los índices, el equipo tiene que preguntarse qué copia es la actual.
Con un modelo de almacenamiento basado en manifiestos, los motores de análisis pueden leer la misma vista versionada del conjunto de datos que el sistema servidor. Pueden proyectar sólo las columnas que necesitan, escanear sólo los rangos de filas relevantes y trabajar con una versión declarada del conjunto de datos en lugar de con una instantánea exportada manualmente.
Las supresiones y correcciones sólo deben afectar a lo que ha cambiado
Las supresiones, correcciones de leyendas, correcciones de etiquetas y actualizaciones de gobernanza son rutinarias en los conjuntos de datos de IA. No deberían forzar a todas las columnas de vectores largos a pasar por la misma ruta de reescritura.
Con Loon, el borrado de registros puede tratarse primero como un borrado lógico. La compactación posterior puede limpiar los ColumnGroups afectados sin reescribir datos no relacionados. Si cambia un campo de texto corto, la capa de almacenamiento no debería tener que reescribir cientos de gigabytes de vectores densos sólo porque comparten la misma fila lógica.
Los motores externos se convierten en parte del flujo de trabajo, no en una vía de escape
El cambio más importante es que los motores externos ya no se tratan como sistemas externos a la base de datos de vectores.
Spark, Ray, los trabajos de evaluación, los sistemas de etiquetado y los pipelines de gobernanza ya producen y modifican gran parte de los datos. La capa de almacenamiento debería permitirles colaborar en torno a una única fuente de verdad en lugar de estar constantemente exportando, copiando y reimportando.
Esto es lo que hace posible una versión de Manifest. Ofrece una vista compartida del conjunto de datos a los servidores en línea, los análisis fuera de línea, los trabajos de backfill y la compactación.
Puede que parezcan detalles de almacenamiento interno, pero afectan a la rapidez con la que los equipos pueden iterar sobre los conjuntos de datos de IA. Cada cambio de modelo, relleno de características, corrección de subtítulos, filtro de calidad y reconstrucción de índices depende de la misma pregunta: "¿Puede el sistema actualizar el conjunto de datos sin mover datos que no necesita mover?".
Ese es el valor práctico del modelo de almacenamiento.
Loon está disponible en Milvus 3.0 beta y Zilliz Vector Lakebase
Loon está disponible en Milvus 3.0 beta y también forma parte de la capa de almacenamiento en Zilliz Vector Lakebase, la próxima evolución de Zilliz Cloud. Esta versión se centra en tres áreas principales:
- El Manifiesto. El objetivo es que las escrituras, backfills, eliminaciones, estadísticas y actualizaciones de índices produzcan vistas de conjuntos de datos versionados que los lectores puedan abrir de forma consistente. Para los lectores, esto significa que una consulta puede abrir una versión específica del Manifiesto y ver una vista estable del conjunto de datos. Para los escritores, esto significa que los nuevos archivos de datos, registros de borrado, estadísticas o archivos de índice pueden prepararse primero y luego hacerse visibles mediante un commit versionado.
- El ColumnGroup y el soporte de formato. Parquet soporta columnas escalares y ecosistémicas. Vortex soporta patrones de acceso vector-heavy. Lance puede integrarse en modo de sólo lectura para compatibilidad con los conjuntos de datos Lance existentes.
- El índice en Lance. Las estadísticas escalares, los índices de filtrado y los índices invertidos de texto pueden participar en la planificación basada en manifiestos por rango de filas. Los índices vectoriales nativos de Lake están más implicados. HNSW e IVF tienen un comportamiento diferente en el almacenamiento de objetos, y HNSW en particular es sensible al acceso aleatorio y a la localidad de la caché. No puede limitarse a reutilizar una disposición diseñada para un SSD local y esperar el mismo resultado.
Aún queda trabajo por hacer
- Las rutas de escritura externas son importantes porque Spark y Ray deberían ser capaces de producir ColumnGroups y Manifest commits sin forzar cada backfill a través de un bucle SDK de cliente.
- La interoperabilidad de Lakehouse importa porque muchos equipos ya utilizan catálogos y motores de consulta como Iceberg, Delta Lake, Trino, DuckDB y Athena. Los datos vectoriales deberían poder participar en ese ecosistema sin perder rendimiento en la búsqueda vectorial.
- Ladisposición de los índices es importante, ya que los índices gráficos y las estructuras invertidas tienen diferentes patrones de acceso en el almacenamiento de objetos.
- La semántica de los objetos grandes es importante porque los vídeos, PDF, imágenes y archivos de audio sin procesar requieren una gestión de referencias, un control de versiones y un comportamiento de eliminación que se ajusten al conjunto de datos vectoriales derivados.
El comportamiento exacto de la versión, la configuración predeterminada y la ruta de migración deben seguir las notas de la versión de Milvus y Zilliz Cloud pertinentes. La dirección de almacenamiento, sin embargo, es clara: las bases de datos vectoriales necesitan una base versionada y nativa de Loon debajo de la capa de servicio.
Pruebe Loon bajo Zilliz Vector Lakebase
Si su pila actual separa el servicio en línea, el análisis fuera de línea, los backfills y los flujos de trabajo externos del lago de datos en diferentes sistemas, merece la pena echar un vistazo a Zilliz Vector Lakebase. Puedes probarlo en Zilliz Cloud. Las nuevas inscripciones de correo electrónico de trabajo reciben $ 100 créditos gratis. También puede hablar con nosotros sobre su caso de uso.
También puedes seguir el lanzamiento de Milvus 3.0 para ver cómo evoluciona Loon en el motor de código abierto.
Zilliz Vector Lakebase reúne:
- Servicio por niveles para diferentes compensaciones de rendimiento y costes en tiempo real
- Búsqueda bajo demanda para cargas de trabajo a gran escala o exploratorias sin computación permanente
- Búsqueda externa en el lago de datos, para que pueda indexar y buscar directamente en los datos del lago existentes
- Búsqueda de espectro completo en vectores, texto, JSON y datos geoespaciales, con recuperación y reordenación híbridas.
- Almacenamiento unificado nativo del lago basado en Vortex, un formato abierto diseñado para lecturas aleatorias más rápidas y de menor coste en datos vectoriales.
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word



